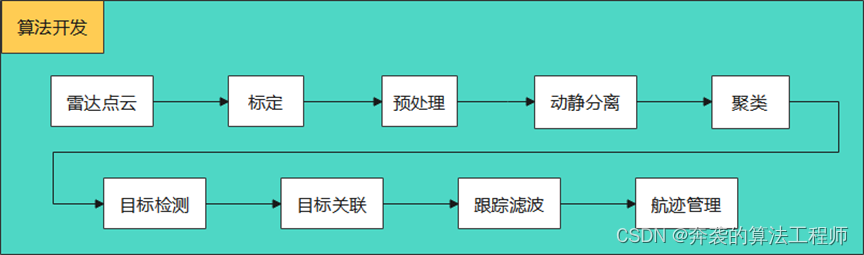
从接收到点云开始,先对点云做标定、坐标转换、噪点剔除、动静分离,再分别对动态目标和静态目标做聚类,然后根据聚类结果做目标的特征分析和检测等,之后对符合条件的聚类结果做目标起始、关联和跟踪等处理,输出目标结果。
2.预处理
2.1标定
将安装雷达的车辆停在水平地面上。根据车身确定车辆行进方向,在车辆正前方5~50m确定测试区域(直线),与行进方向平行或垂直(误差小于2cm);将角反射器调整到与雷达相同高度(误差小于1cm),选择多个点(不少于10个)放置角反射器并通过雷达读取角度值,根据多个点的数据拟合的直线斜率和夹角,最终确定偏航角θ。俯仰角φ的标定同偏航角方法。
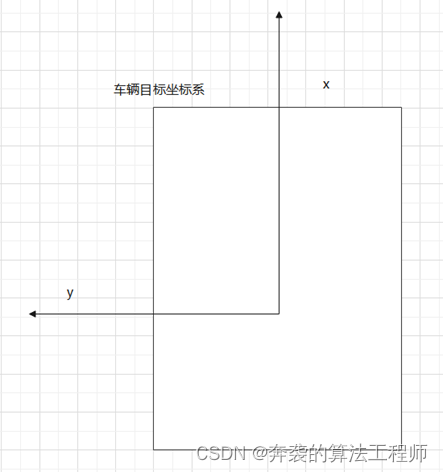
雷达点云通常是极坐标下的,表示为径向距离r,方位角azi,俯仰角ele,需要将坐标转到自车后轴中心在地面的投影为原点的坐标系,如下图。
x,y,z方向上的偏移分别为OFFSET_X,OFFSET_Y,OFFSET_Z,则最终的坐标为
x = r*cos(ele+φ)*cos(azi+θ)+OFFSET_X
y = r*cos(ele+φ)*sin(azi+θ)+OFFSET_Y
2.3噪点剔除

ROI区域通常设置成矩形,图中是XOY平面投影,实际处理需考虑Z轴方向的范围,应为矩形盒。
由于多径或环境噪声影响,雷达会检测到各种虚假目标,通常这些目标的RCS很小,可以通过RCS门限剔除。
而RCS随距离增加而增加,因此设置RCS门限时,也应把距离作为参数。
2.4动静分离
动静分离主要根据径向速度在车辆前进方向的投影为0进行判断。如下图所示,Vego表示本车车速,VR表示目标的径向速度,α表示目标的方位角,β表示雷达相对于车头正前方的横向偏角(由方向盘转角计算得到),将Vego向径向速度方向投影,对于每帧中的每个目标,均可建立各参数间的关系方程如下:
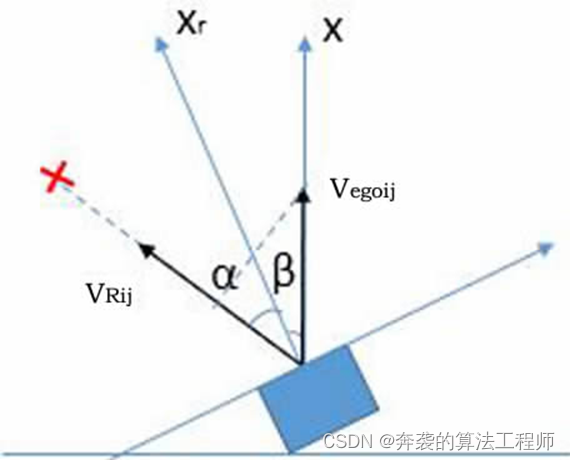
实际处理时,可通过设定门限判断目标是否静止。由于自车车速存在一定误差,Vego越大,误差越大,设置门限时应考虑这个因素。
3.目标检测
3.1目标聚类
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,就能得到最终的所有聚类类别结果。
DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ϵ, MinPts)用来描述邻域的样本分布紧密程度。其中,ϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为ϵ的邻域中样本个数的阈值。
假设样本集是D=(x1,x2,…,xm),则DBSCAN具体的密度描述定义如下:
1) ϵ-邻域:对于xj∈D ,其ϵ-邻域包含样本集D中与xj的距离不大于ϵ的子样本集,即Nϵ(xj)={xi∈D|distance(xi,xj)≤ϵ}、 这个子样本集的个数记为|Nϵ(xj)|
2) 核心对象:对于任一样本xj∈D,如果其ϵ-邻域对应的Nϵ(xj)至少包含MinPts个样本,即如果Nϵ(xj)|≥MinPts,则xj是核心对象。
3)密度直达:如果xi位于xj的ϵ-邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。
4)密度可达:对于xi和xj,如果存在样本序列p1,p2,…,pt,满足p1=xi,pt=xj, 且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,…,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
从下图可以很容易看出理解上述定义,图中MinPts=5,红色的点都是核心对象,因为其ϵ-邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列的ϵ-邻域内所有的样本相互都是密度相连的。

输入:样本集D=(x1,x2,…,xm),邻域参数(ϵ,MinPts)。
1)初始化核心对象集合Ω=∅,初始化聚类数k=0,初始化未访问样本集合Γ = D,类划分C = ∅。
2) 对于j=1,2,…m, 按下面的步骤找出所有的核心对象:
a) 通过距离度量方式,找到样本xj的ϵ-邻域子样本集Nϵ(xj)。
b) 如果子样本集样本个数满足|Nϵ(xj)|≥MinPts, 将样本xj加入核心对象样本集合:Ω=Ω∪{xj}。
4)在核心对象集合Ω中,随机选择一个核心对象o,初始化当前类核心对象队列Ωcur={o}, 初始化类别序号k=k+1,初始化当前类样本集合Ck={o}, 更新未访问样本集合Γ=Γ−{o}。
5)如果当前类核心对象队列Ωcur=∅,则当前类Ck生成完毕, 更新类划分{C1,C2,…,Ck}, 更新核心对象集合Ω=Ω−Ck, 转入步骤3。
6)在当前类核心对象队列Ωcur中取出一个核心对象o′,通过邻域距离阈值ϵ找出所有的ϵ-邻域子样本集Nϵ(o′),令Δ=Nϵ(o′)∩Γ, 更新当前类样本集合Ck=Ck∪Δ 更新未访问样本集合Γ=Γ−Δ 更新Ωcur=Ωcur∪(Δ∩Ω)−o′,转入步骤5。
3.2特征提取
聚类后,可以得到基本信息,比如目标位置(x,y,z)、点云数量、长度、宽度、高度、体积、投影面积、RCS、SNR以及各种统计分布,如位置方差等。根据这些信息,可以对目标进行分类,得到目标的分类结果。
3.3目标分类
毫米波分类可以考虑使用机器学习的方法进行分类,常见的有决策树模型、最近邻模型和支持向量机等。
使用激光雷达对毫米波点云进行标注,前提是激光雷达本身精度和准确度要足够高,如果存在问题,可考虑人工进行修改。

如图,红色和黄色圆圈代表毫米波点云,黑色方框是未经过时间补偿的lidar目标,而蓝色方框是经过时间补偿的lidar目标。通常情况下,补偿后的lidar目标框可以包围实际目标的毫米波点云,这样就能同时得到训练样本(点云类)和标注结果(补偿后的lidar目标)。
Python中导入sklearn工具包可以方便地调用不同模型进行训练,并且可以使用不同参数进行对比实验,输出分类准确率、错误率或混淆矩阵等。
另外Python的m2cgen工具包支持输出sklearn模型的C代码,方便部署到各类平台运行。
3.4路沿检测
对静止点聚类,如果某类中点数明显较多,且位置跨度较大,则认为是路沿,需要对路沿做拟合生成。
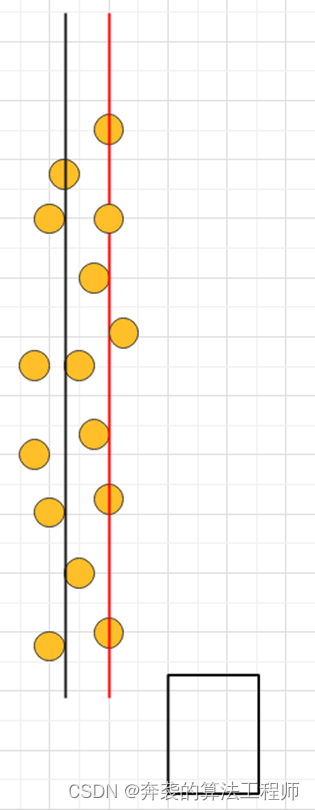
由于路沿存在一定宽度,如果直接拟合,则会生成如下图的黑色路沿,和实际结果存在较大误差。因此,这里需要每隔一段距离提取聚类的内侧点,再对内侧点进行拟合,得到下图中红色的路沿结果,与实际值误差较小。
4.目标跟踪
4.1目标起始
点云检测结果符合一定条件就可以起始目标,一般需要满足以下条件:
目标起始并没有统一的标准,需要根据实际情况调整参数,上述几个条件是较为常见的,根据实际场景可以微调或增加其他条件。
4.2目标关联
|center_xi – center_xj| < x_threshold
|center_yi – center_yj| < y_threshold
稳定航迹使用毫米波点云和目标包围框进行关联,判断点云位置和径向速度是否在关联门限内,类似于激光目标给毫米波点云做标注,可参考3.3节。
航迹成功和点云关联,则更新目标属性。如果累计帧数未达到生成航迹要求,则只保存历史数据,只有达到帧数要求或者稳定航迹成功关联点云,才做属性更新。
目标属性包括位置、速度、类别、朝向、长宽等。
4.3.1朝向估计
首先将历史点云做坐标转换,统一转换到当前坐标系下,可以通过最小面积、最小距离等遍历方法拟合朝向,具体方法可参考论文《Efficient L-Shape Fitting for Vehicle Detection Using Laser Scanners》。
实际数据仿真验证表明,速度较快时用最小二乘就能得到很好的结果。速度较慢时,使用更多历史点云可以得到更准确的朝向估计。
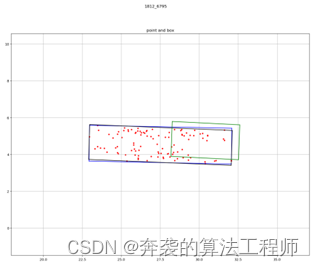
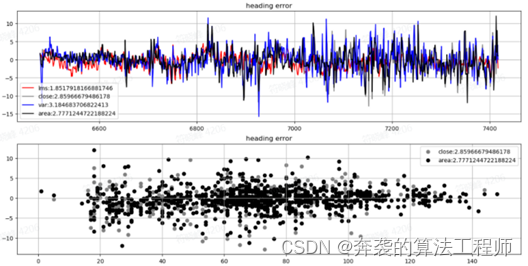
上图左是朝向估计的结果,绿色是激光雷达估计的目标框,蓝色和灰色是使用距离方差准则和最近距离准则估计的朝向。上图右是目标不同姿态下的统计结果,可以看到,随着点数的增加,朝向估计误差在减小。
有了朝向之后,可以计算聚类点云在朝向方向上的投影,从而计算长宽,这样聚类点云就多了朝向、长宽等特征,可以通过3.3节的机器学习方法做分类,再根据类别得到目标长宽的推理结果。
4.3.2速度估计
得到准确的目标朝向之后,可以通过径向速度、目标朝向、点云角度计算得到目标的速度。
如下图,Vt是目标速度,α是朝向角,Vego是自车速度,θ是点云方位角,β是自车速度和车体坐标系偏角。
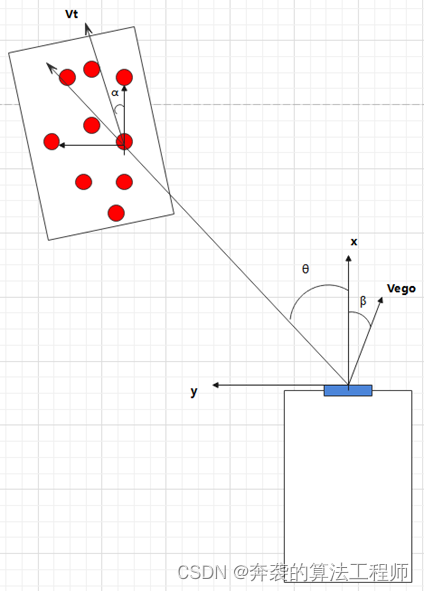
首先计算补偿车速后的绝对径向速度comp_Vr = Vr + Vego*cos(θ+β)
最后减去自车的横纵向速度得到相对横纵向速度
Vt_x = Vt_abs_x – Vego*cos(θ+β)
Vt_y = Vt_abs_y – Vego*sin(θ+β)
4.3.3跟踪滤波
使用卡尔曼滤波对检测得到的位置和速度等做跟踪滤波处理,一般由下面5个公式组成。

![]() 和
和![]() 分别表示k时刻和k-1时刻的后验状态估计值,是滤波的结果,这里使用匀加速直线(CA)运动模型,
分别表示k时刻和k-1时刻的后验状态估计值,是滤波的结果,这里使用匀加速直线(CA)运动模型,![]() =[x,y,vx,vy,ax,ay]。
=[x,y,vx,vy,ax,ay]。
![]() 是k时刻的先验状态估计值,是滤波的中间计算结果,即根据k-1时刻的最优估计预测的k时刻的结果,是预测方程的结果。
是k时刻的先验状态估计值,是滤波的中间计算结果,即根据k-1时刻的最优估计预测的k时刻的结果,是预测方程的结果。
F是状态转移矩阵,实际上是对目标状态转换的一种猜想模型。状态转移矩阵通常用来对目标的运动建模,其模型可能为匀速直线运动或者匀加速运动。
H是状态变量到测量(观测)的转换矩阵,表示将状态和观测连接起来的关系,卡尔曼滤波里为线性关系,它负责将m维的测量值转换到n维,使之符合状态变量的数学形式,是滤波的前提条件之一。
Q代表过程噪声协方差,该参数用来表示状态转换矩阵与实际过程之间的误差。因为无法直接观测到过程信号,所以Q的取值是很难确定的,可以参考何友《雷达数据处理及应用》给出初始值。
R是测量噪声协方差。滤波器实际实现时,测量噪声协方差R一般可以观测或统计分析得到。
将点云检测结果放到滤波器,通过调整参数Q和R,可以得到不同场景下的状态最优估计结果。
生命周期管理主要对目标生成和消亡做处理。航迹生成时,满足关联条件,且n个观测周期存在至少m次,则符合航迹生成要求,生成新航迹,赋予新ID。
如果n个观测周期存在次数小于m次,则不符合航迹生成要求,航迹不会生成,直接删除。
如果航迹稳定跟踪,单帧未关联点云,则用外推值更新;如果关联点云,则用卡尔曼滤波得到的新状态更新。
如果航迹稳定一段时间,连续t个观测周期中k次无法成功关联,则删除这条航迹。
5.特殊处理
5.1直线拟合估计目标速度和朝向
点云聚类后,通过径向速度和方位角也可以估计目标朝向。
假设目标朝向角为α,目标点云在速度方向的投影即是点云的径向速度Vr,则有:
V(i)*cos(θ(i)-α) = Vr(i)
V(i) = Vr(i) / cos(θ(i)-α)
由于车辆是刚体,车身每个点速度相等,则有V(1) = V(2) = … = V(n)
V(i) = V(j) = V
Vr(i) / cos(θ(i)-α) = Vr(j) / cos(θ(j)-α)
可以计算得到点云的朝向角α,进而得到目标的真实速度和横纵向速度。
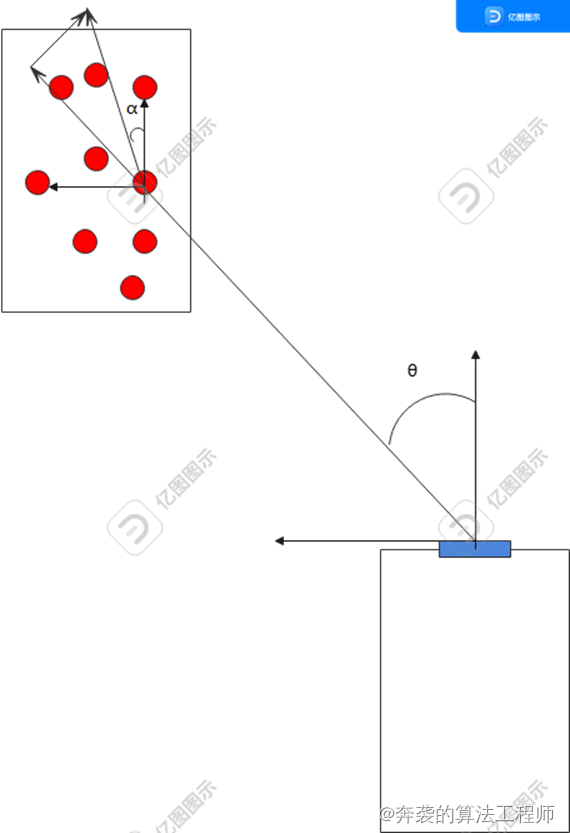
由于雷达对速度的测量可能存在模糊或出现错误,因此任意两个点的结果有较高错误概率,但多个点拟合得到的结果有较高的可行度,可以准确估计目标朝向和横纵向速度。
上文已经推导Vr(i) = V* cos(θ(i)-α) = V*(cos(θ(i))cos(α) + sin(θ(i))sin(α))
两边同时除以V*Vr(i)* cos(α),则有
cos(θ(i))/Vr(i) = 1 / V cos(α) – tan(α) * sin(θ(i))* /Vr(i)
令y(i) = cos(θ(i))/Vr(i), x(i) = sin(θ(i))* /Vr(i),b = 1 / V cos(α), k = – tan(α)则有
y(i) = k * x(i) + b
由于单个目标聚类后速度和角度离散性不足,使用最小二乘拟合往往不能得到最优解,此时可以考虑使用二分迭代法。
仍旧是角度和速度的关系表达式
V(i)*cos(θ(i)-α) = Vr(i)
通过预设的角度α,计算目标速度V(i) = Vr(i) / cos(θ(i)-α)
再计算不同角度α的V(i)离散程度,离散程度越小,则α是实际角度的概率越高。V(i)的离散程度可以用方差表示。
5.3自车轨迹路径静止点处理
通常目标起始跟踪不对静态点做处理,但考虑到碰撞风险,在自车运动轨迹上的静态点需要跟踪处理,做碰撞预警。
自车运动可以用圆周运动建模,通常直线行驶时认为圆周半径非常大,比如10000m。如果转弯时,则可以用下图示意的方法计算。
下图中,自车后轴中心为O,在以C为圆心的原点做圆周运动,半径为R,红色曲线代表自车运动方向。
则有Vego*t = R*α = R*yawrate*t –> R = V/yawrate
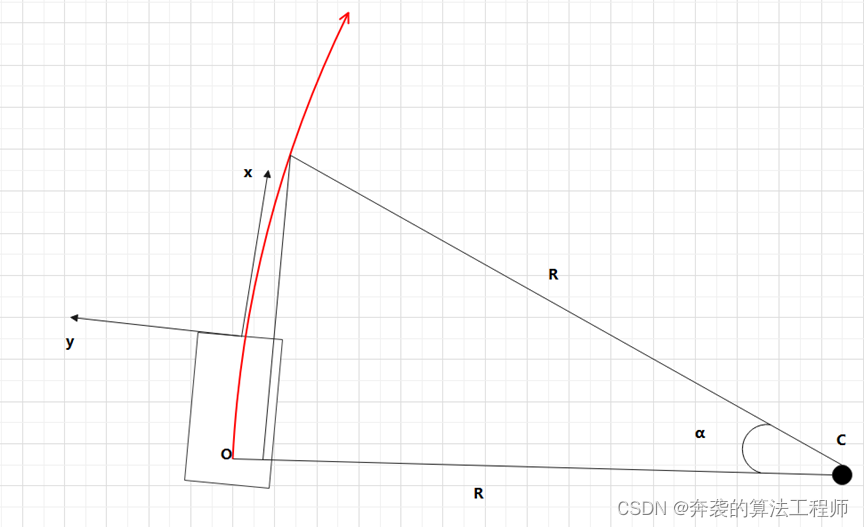
然后可以计算自车轨迹的方程

在自车轨迹附近的静态点加入到目标起始、跟踪流程中,生成一般障碍物或过滤虚假目标,起到预警作用。
原文地址:https://blog.csdn.net/weixin_41691854/article/details/134658925
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_45476.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!