智能交通系统(ITS),包括无人驾驶车辆,尽管在道路上,已经逐渐成熟。如何消除各种环境因素造成的干扰,进行准确高效的交通标志检测和识别,是一个关键的技术难题。然而,传统的视觉对象识别主要依赖于视觉特征提取,例如颜色和边缘,这存在局限性。卷积神经网络(CNN)是针对基于深度学习的视觉对象识别而设计的,成功克服了传统对象识别的缺点。
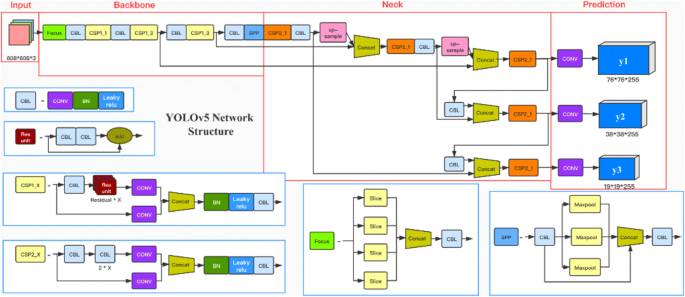
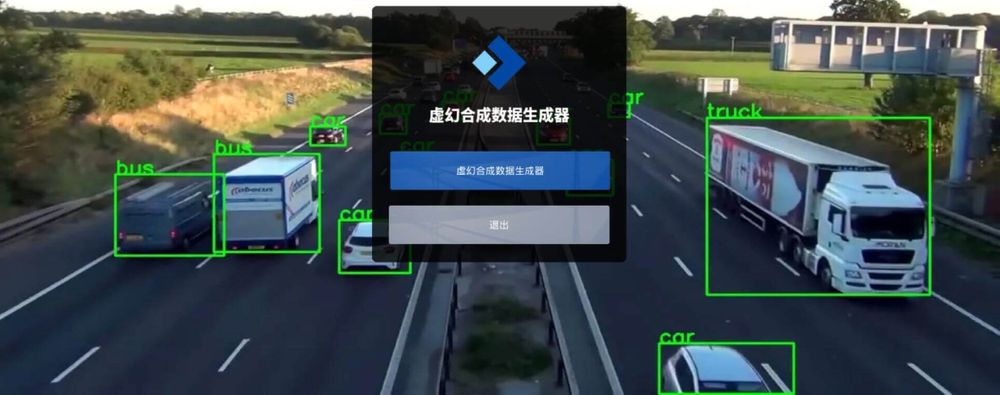
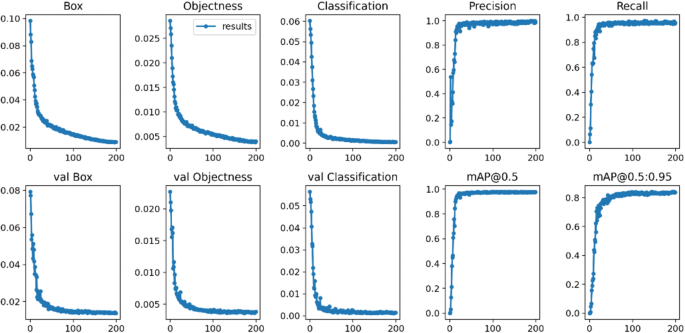
在本文中,我们基于我们的交通标志识别 (TSR) 数据集实施了一个实验来评估最新版本的 YOLOv5 的性能,本项目中的实验利用UnrealSynth虚幻合成数据生成器 生成了试验的数据集。
1、介绍
近年来,随着人工智能(AI)的爆发,车载辅助驾驶系统更新了以往的驾驶模式。通过获取实时路况信息,系统及时提醒驾驶员进行准确操作,从而防止因驾驶员疲劳而发生车祸。除了辅助驾驶系统外,自动驾驶汽车的开发还需要从数字图像中快速准确地检测交通标志。
交通标志识别(TSR)是从数字图像或视频帧中检测交通标志的位置,并给出特定的分类。TSR方法基本上利用了视觉信息,例如交通标志的形状和颜色。然而,传统的TSR算法在实时测试中也存在一些弊端,例如容易受到驾驶条件的限制,包括照明、摄像头角度、障碍物、行驶速度等。实现多目标检测也非常困难,由于识别速度慢,容易遗漏视觉对象。
随着计算机硬件的不断完善,人工神经网络的局限性得到了很好的缓解,使机器学习进入了发展的黄金时期。深度学习是一种机器学习方法。深度神经网络模型在处理信息时模拟我们人脑的神经结构。利用该神经网络模型从道路图像中提取有效特征,远优于传统的TSR算法,具有提高算法鲁棒性和泛化性的潜力。
TSR的研究成果不仅避免了交通事故,保护了驾驶员,还有助于高效准确地检查道路上的交通标志,从而减少了不必要的人力和资源。此外,它还为无人驾驶和辅助驾驶提供技术支持。因此,基于深度学习的研究工作具有巨大的意义,对我们的日常生活具有不可估量的价值。