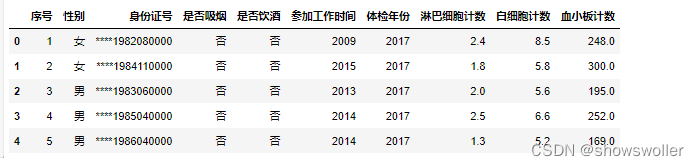
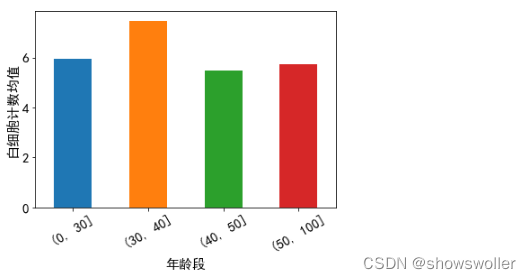
当前位置: 首页python正文 本文介绍: Python对职业人群体检数据进行分析与可视化(附源码 超详细)使用matplotlib pandas等对数据分析 需要源码和数据集请点赞关注收藏后评论区留言私信~~~ 职业人群体检数据分析 有的职业危害因素会对人体血液等系统产生影响。下面针对一次职业人群体检的部分数据进行分析 实现步骤如下 1:导入模块 2:获取数据 导入待处理数据testdata.xls并显示前五行 3:分析数据 首先查看数据类型 表结构 并统计各个字段空缺值的个数 接下来删除全为空的列以及身份证号为空的数据 删除全为空的列 DataFrame.dropna(axis=0, how=’any‘, thresh=None, subset=None, inplace=False) 函数作用:删除含有空值的行或列¶ axis:维度,axis=0表示index行,axis=1表示columns列,默认为0 how:”all“表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,”any“表示这一行或列中只要有元素缺失,就删除这一行或列 thresh:一行或一列中至少出现了thresh个才删除。 subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列) inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改 删除身份证号为空的数据 将“开始从事某工作年份”规范为4位数字年份,如“2018”,并将列名修改为“参加工作时间 增加列“工龄”(体检年份–参加工作时间)和“年龄”(体检时间-出生年份)两列 查看待处理是否有缺失值 然后删除所有缺失值 然后可以看到参加工作时间之一列的缺失值已经删除,同时也看到体检年份还有38个缺失值 也进行删除 身份证号,参加工作时间以及体检年份的数据类型都是object,需要进行类型转换,统一转化为int64类型,另外,体检年份这一列有很多异常数据,很多年份后都有年字,对体检年份数据进行时间提取 增加工龄和年龄这两列 统计不同性别的白细胞计数均值 并画出柱状图 统计不同年龄段的白细胞计数,并画出柱状图,年龄段划分为:小于或等于30岁,31-40岁,41-50岁以及大于50岁4个 经过上面这一系列工作,可以很清楚的看出数据的一些分布特征 有助于后续的解决方案 代码 部分代码如下 需要全部代码请点赞关注收藏后评论区留言私信~~~ import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 %matplotlib inline df = pd.read_excel("testdata.xls")#这个会直接默认读取到这个Excel的第一个表单 data =df.head()#默认读取前5行的数据 data df.info() df.dtypes df.shape df.isnull().sum() df.dropnaaxis=1, how='all',inplace= True)#将全部项都是nan的列删除 df.head() df.dropna(how='any',subset=['身份证号'],inplace= True) df.isnul().sum() df1 = df df.shape df.开始从事某工作年份 = df.开始从事某工作年份.str[0:4] df.rename(columns={"开始从事某工作年份": "参加工作时间"},inplace=True) df.head() df.isnull().sum() df1 = df.dropna(subset=['参加工作时间'],how='any') df1.isnull().sum() df1.isnull().sum() df2 = df1.dropna(subset=['体检年份'],how='any') # () df2.isnull().sum() #参加工作时间转换为int64类型 #首将体检年份转换为str类型 data['体检年份'] = data.体检年份.astype('str') #切片取前4位值之后再将体检年份转换为int64类型 data.体检年份 = data.体检年份.str[0:4].astype("int64") #取身份证的第4位-第7位,并转换为int64类型 data["出生年份"] = data.身份证号.str[4:8].astype('int64') d.head() data.参加工作时间 = data.参加工作时间.astype('int64') data['体检年份'] = data.体检年份.astype('str') data.体检年份 = data.体检年份.str[0:4].astype("int64") data["出生年份"] = data.身份证号.str[4:8].astype('int64') data.head() data = data.eval('工龄 = 体检年份-参加工作时间') data = data.eval("年龄= 体检年份- 出生年份") data.head() import matplotlib matplotlib.rcParams['font.size'] = 15 matplotlib.rcParams['font.family'] = 'SimHei' # mean.plot(kind='bar') #series.plot(kind='bar') mean.plot.bar() plt.xticks(rotation=0) plt.ylabel("白细胞均值") data['年龄段'] = pd.cut(data.年龄, bins=[0,30,40,50, 100]) count = data.groupby('年龄段')['白细胞计数'].mean() count count.plot(kind = "bar") plt.xticksotation=30) plt.ylabel("白细胞计数均值") 创作不易 觉得有帮助请点赞关注收藏~~~ 原文地址:https://blog.csdn.net/jiebaoshayebuhui/article/details/128729003 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_45786.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。数据源码职业 代码007普通 打赏 收藏 海报 链接