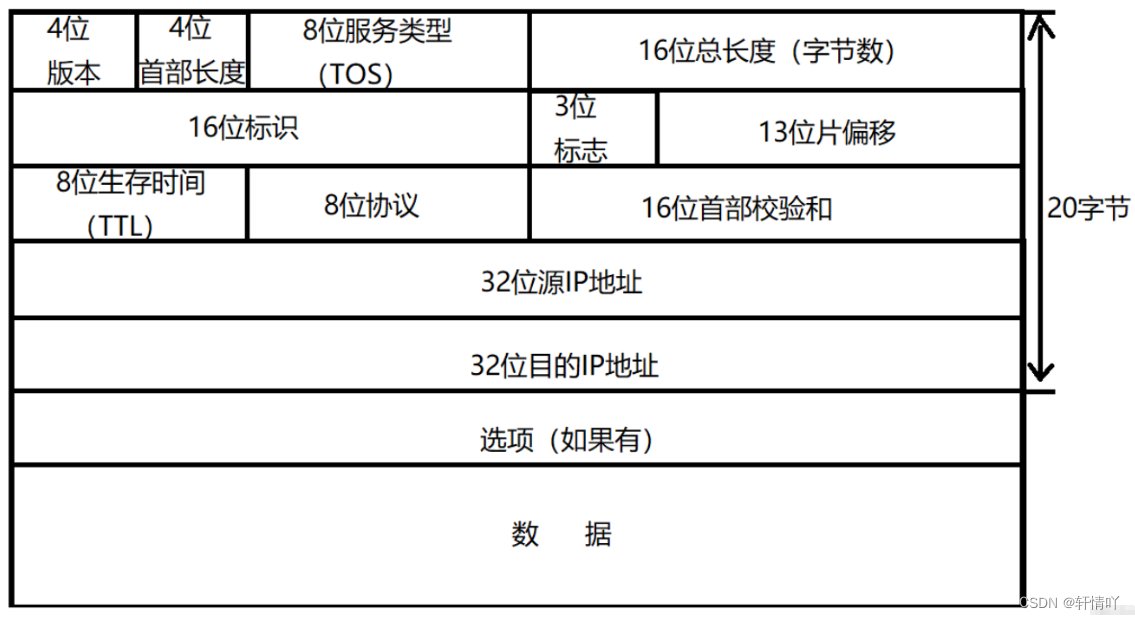
本文介绍: 其中,base_address是数组的基地址(即数组在内存中的起始地址),i是元素的下标,element_size是每个元素的大小(以字节为单位)。数组在内存中是连续存储的,因此数组的第一个元素(下标为0)存储在最低地址,而最后一个元素(下标为数组长度-1)存储在最高地址。由于数组元素在内存中是紧密相邻的,访问数组时,可以通过简单的加法计算得到所需的元素地址。总之,C语言中数组从低地址到高地址的存储顺序是为了与计算机系统的内存组织方式相吻合,使得数组访问更加高效,并且与指针的偏移量计算方式保持一致。
在C语言中,数组的存储从低地址到高地址是有其历史原因的。这种设计主要是为了与计算机系统的内存组织方式相一致。
在计算机系统中,内存通常按照字节进行编址,地址从低到高递增。数组在内存中是连续存储的,因此数组的第一个元素(下标为0)存储在最低地址,而最后一个元素(下标为数组长度-1)存储在最高地址。
这种设计使得数组访问更加高效。由于数组元素在内存中是紧密相邻的,访问数组时,可以通过简单的加法计算得到所需的元素地址。例如,要访问数组中的第i个元素,可以通过以下方式计算其地址:
address = base_address + i * element_size
其中,base_address是数组的基地址(即数组在内存中的起始地址),i是元素的下标,element_size是每个元素的大小(以字节为单位)。这种地址计算方式与内存的编址方式相吻合,使得数组访问更加方便和高效。
另外,C语言中的指针和数组之间有着密切的联系。指针可以用来访问数组中的元素,而指针的偏移量也是基于数组元素的字节大小。因此,数组从低地址到高地址的存储顺序也与指针的偏移量计算方式相一致。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。