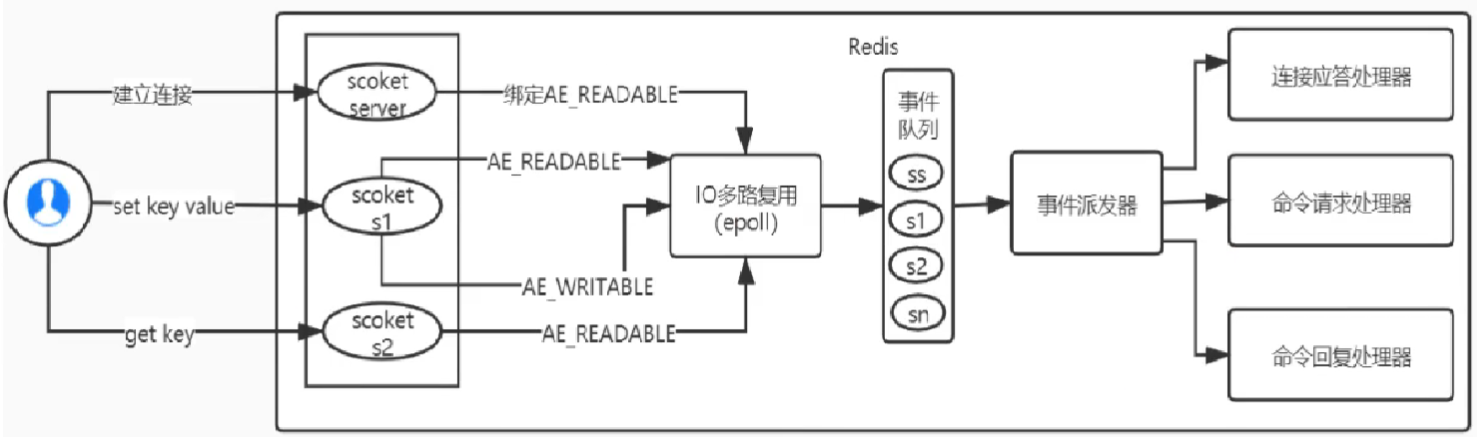
IO多路复用的概念
IO多路复用其实一听感觉很高大上,但是如果细细的拆分以下,
IO:网络IO,操作系统层面指数据在内核态和用户态之间的读写操作。
多路:多个客户端连接(连接就是套接字描述符,即Socket)
复用:用一个或多个连接处理
其实就是用一个服务端连接进行处理多客户端的请求。实际就是一个服务端进程处理多个套接字描述符,实现返回有select、poll、epoll。
那么什么是文件描述符呢?
说白了就是非负整数,当打开或者创建一个文件描述符时返回一个数值。
整个流程是什么样的?
当用户有请求进来之后,会将用户socket文件描述符注册进入epoll,然后epoll监听哪些socket有消息到达。可以避免Redis主线程来回进行切换或者被阻塞。通过一个主线程来控制请求数据量的转发。
为什么这样的方式吞吐量比较高呢,其实如果是来一个请求创建一个线程,那么太耗费资源,但是如果一个线程轮询处理,那么可能会被阻塞导致吞吐量较低。
通信方式
同步:调用者需要等待下游系统的结果,线程一直会在等待中。比如订单系统调用支付系统,需要支付系统返回结果才可以进行后续的订单状态修改。处理时间比较快的系统推荐使用。
异步:调用者接受到被调用者的相应,就处理别的事情,一般需要被调用者通过回调函数或者异步MQ的返回方式将结果写回,这种方式对于处理比较耗时的系统来说,一般采用异步方式。
阻塞:调用方会被阻塞,一直什么不干。
非阻塞:调用方不会阻塞,先返回做别的事情。
同步异步:在于被调用方返回消息的通知方式上
阻塞非阻塞:在于调用方等待时候的行为
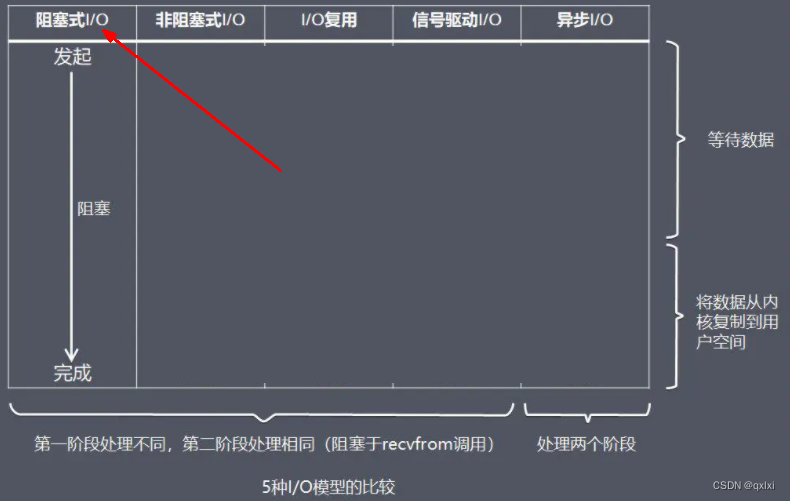
五种网络编程的IO模型
Blocking IO: 阻塞IO
NoneBlocking IO : 非阻塞IO
IO multiplexing : IO多路复用
singal driven Io 信用驱动IO
saynchronuns 异步IO
BIO
public static void main(String[] args) throws IOException {
byte [] bytes = new byte[1024];
ServerSocket serverSocket = new ServerSocket(6379);
while (true) {
System.out.println("1.建立连接");
Socket accept = serverSocket.accept();
System.out.println("2.连接成功");
InputStream inputStream = accept.getInputStream();
int length = -1;
System.out.println("3.等待读取数据");
while ((length =inputStream.read(bytes)) != -1) {
System.out.println("4.读取到数据");
System.out.println(new String(bytes));
}
System.out.println("5.数据读取结束");
inputStream.close();
accept.close();
System.out.println("6.关闭资源结束");
}
}
客户端
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
while (true) {
Scanner scanner = new Scanner(System.in);
String next = scanner.next();
if (next.equalsIgnoreCase("quit")) {
break;
}
outputStream.write(next.getBytes());
System.out.println("写入数据成功");
outputStream.close();
socket.close();
}
}
可以发现如果服务端采用建立连接之后,客户端迟迟不写入数据,那么客户端就会一直阻塞在read()中。
那么这种问题如何解决呢,一般简单的就是使用创建多个线程的方式来解决read阻塞问题。
public static void main(String[] args) throws IOException {
byte [] bytes = new byte[1024];
ServerSocket serverSocket = new ServerSocket(6379);
while (true) {
System.out.println("1.建立连接");
Socket accept = serverSocket.accept();
System.out.println("2.连接成功");
//多个线程处理read数据读取
new Thread(()-> {
InputStream inputStream = null;
try {
inputStream = accept.getInputStream();
int length = -1;
System.out.println("3.等待读取数据");
while ((length =inputStream.read(bytes)) != -1) {
System.out.println("4.读取到数据");
System.out.println(new String(bytes));
}
System.out.println("5.数据读取结束");
inputStream.close();
accept.close();
System.out.println("6.关闭资源结束");
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
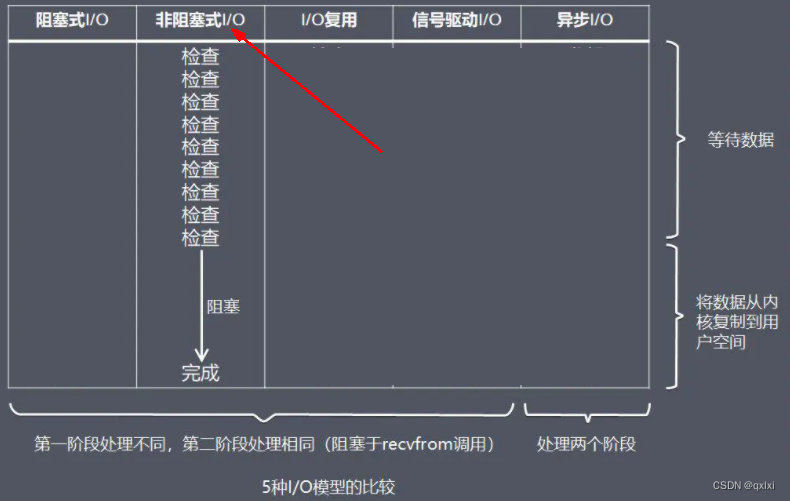
但是如果细心的同学就会发现,其实如果大量的创建线程,会十分消耗系统资源,并且进程内创建线程是有一定的上限,所以解决办法要么使用线程池进行复用,要么使用非read阻塞模式,也就是NIO。
NIO
通过上面分析可以知道,其实BIO主要是在read过程中读取数据会被阻塞,而NIO通过轮询的方式不断查询数据,但是这样其实也会频繁的空跑CPU。
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
while (true) {
Scanner scanner = new Scanner(System.in);
String next = scanner.next();
if (next.equalsIgnoreCase("quit")) {
break;
}
outputStream.write(next.getBytes());
System.out.println("写入数据成功");
outputStream.close();
socket.close();
}
}
Reactor模式
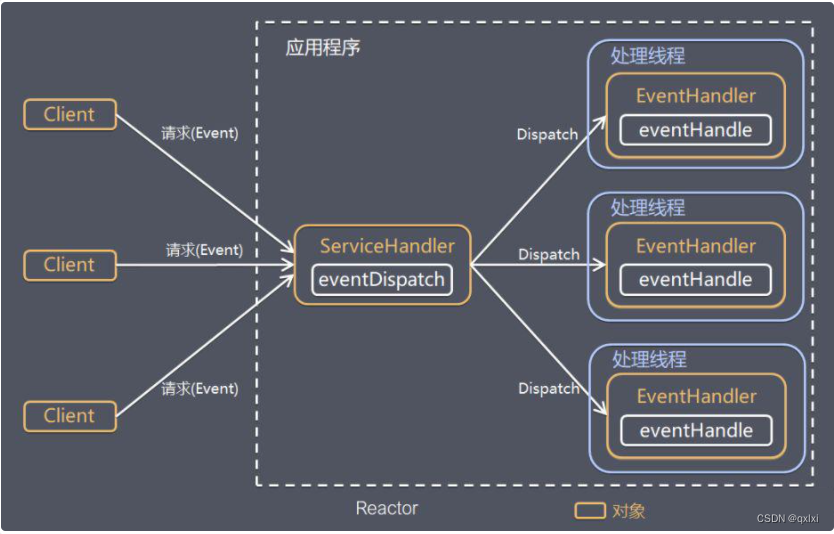
Reactor模式其实就是将请求处理和分发进行职责划分,一个线程负责请求的转发,而具体的业务逻辑由不同的处理现场进行处理。
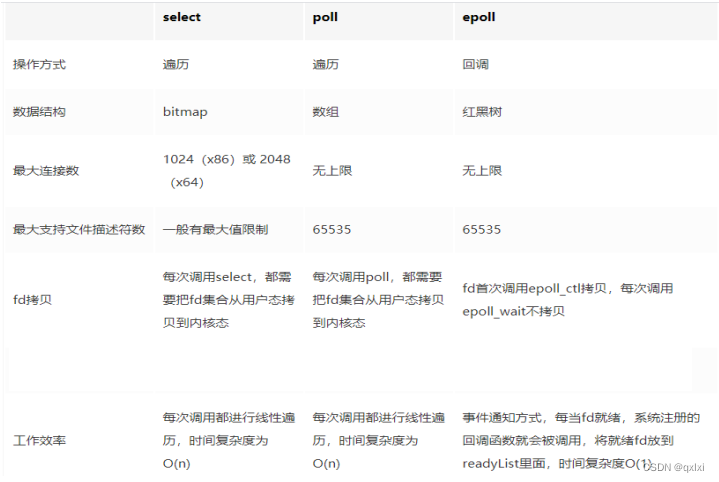
select

可以看到select监听的文件描述符包括三个readfds、writefds、exceptfds,将用户传入的数组拷贝到内核空间,select会被阻塞,直到描述符就绪,返回。
selcet核心执行流程
1.select是一个阻塞函数,当没有数据时,会一直阻塞在select。
2.当有数据时,会将对应的rset设置为1
3.select函数返回,不在阻塞。遍历文件描述符判断那个fd置位,读取数据,然后处理。
优点 :说白了select的核心其实还是将用户态的轮询搬到了内核态,这样可以避免频繁的上下文切换,执行时间和效率上肯定更快。
缺点:
1.rset位不可重复用,每次socket有数据就会相应的位被置位。
2.bitmap 最大1024 一个进程最多处理1024个客户端。
3.文件描述符数组拷贝到了内核态,select调用需要传入fd数组,需要拷贝一份到内核,高并发场景下消耗的资源是惊人的。
4.select 没有通知用户态哪一个socket有数据,需要O(N)遍历。
小结:select方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + N次就绪状态的文件描述符的 read 系统调用
poll

优点
1.使用数组来解决select的bitmap 1024限制。
2.有事件发生时,将对应的revents置位位为1,遍历的时候将对应的位置设置为0,可以实现重用。
缺点
1.poll fds数组拷贝到内核态,仍然有开销。
2.poll并没有通知用户态那个socket有数据,需要O(N)遍历
epoll

1.epoll_create : 创建一个epoll 句柄
2.epoll_ctl 向内核添加、修改或删除要监听的文件描述符
3.epoll_wait 类似发起select调用

总结:IO多路复用快的原因在于,本身是用户态到内核态的多次数据调用,进一步优化成一次用户态+内核层遍历文件描述符。
小结
本篇主要介绍了IO多路复用的机制,从IO模型,通信方式(同步、异步),调用方是否等待(阻塞、非阻塞) ,以及介绍了三种主要的IO模型(BIO、NIO、IO多路复用机制)
而IO多路复用机制是很多中间件核心原理,比如Nginx、Redis等。具体就是三种不同的内置函数,select、poll、epoll,核心就是原来在用户态的while(true)多次调用,调整到内核态的一次系统调用+内核层遍历文件描述符。

原文地址:https://blog.csdn.net/jia970426/article/details/130611163
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_46048.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!


![【C++入门到精通】C++的IO流(输入输出流) [ C++入门 ]](https://img-blog.csdnimg.cn/direct/32ed20b44d704746a77da19b16d060e5.jpeg)