一. String 字符串
常见用途:缓存用户信息,将用户信息结构体使用 JSON 序列化为字符串,然后将序列化后的字符串给 Redis 来缓存
Redis 字符串是动态字符串,是可以修改的字符串 —— 实现类似 ArrayList ???
操作:
单个操作:
set 、 get 、 exists 、del、setex、setnx(不存在就创建)、incr、incrby
批量操作:
mset 、mget
二、list 链表
相当于 Java 语言中的 LinkedList,插入删除速度非常快,但是定位索引非常慢

底层使用 quicklist 快速链表结构,当数据量小时,分配一块连续内存(ziplist),数据量大时,才改成 quicklist。从而使得满足快速插入删除性能的同时,又不会出现太大的空间冗余。
当成异步队列使用,将任务序列化为字符串存入 list 中,再另开一个线程从列表中轮询数据进行处理
操作:
rpush , lpop,rpop,llen,lindex(得到某个位置的元素,可为负数,表示倒序拿,非常慢,慎用),ltrim(保留某个范围的元素)
三、hash (字典)
相当于 Java 语言中的 HashMap ,其是无序字典。与 Java 语言 rehash 方法不同,使用渐进式 rehash 策略 (在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中)。
hash 也可以用来存储用户信息,这样在获取时,可以做到部分获取,这种部分获取可以减少网络流量的浪费,但是 hash 结构存储的消耗更高,到底选择如何需要根据情况而定。
操作:
hset 、hgetall 、hlen、hget 、hmset、hincrby、incr
四、set(集合)
相当于 Java 语言中的 HashSet,因为其具有去重功能,适合存储活动中奖的用户 ID。
操作:
sadd , smembers , sismember , scard(获取长度) , spop
五、zset (有序列表)
Java 中 SortedSet 和 HashMap 的结合体,一方面可以保证 value 的唯一性,一方面为每个 value 赋予一个 score,代表这个 value 的排序权重,可以进行排序。其内部使用 跳跃列表 的数据结构实现。
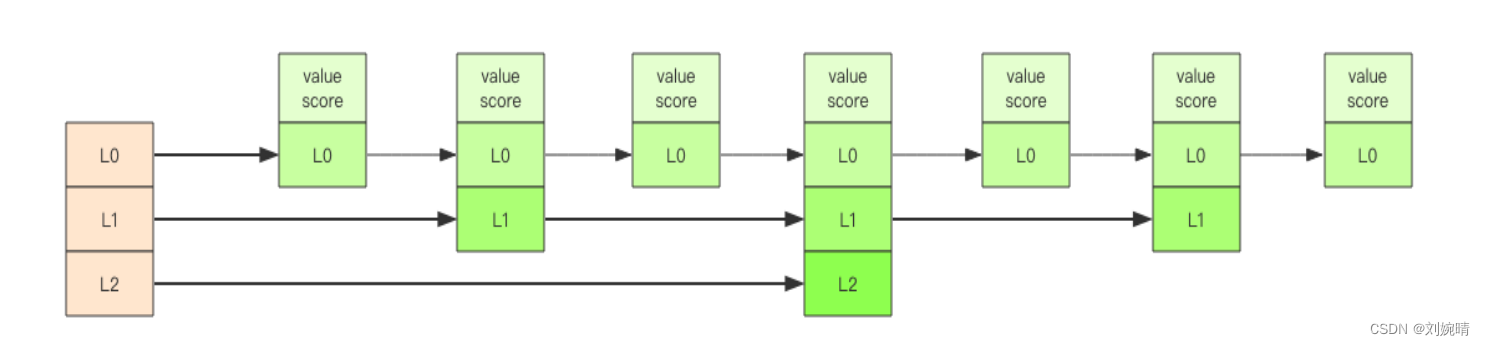
zset 适合用来存储粉丝列表,这样可以对粉丝按照关注时间进行排序。
操作:
zadd、zrange(按照score得到某个范围的数据)、zrevrange(按照score得到某个范围的数据逆序输出)、zcard(含几个元素) 、zrank(某个元素排第几位) 、 zrangebyscore(按照排序输出范围)、zrem(删除某个元素)、 zscore(得到某个元素的 score)
容器型数据结构遵循的原则:
扩展: 存储用户对象时,使用 hash 还是 string
可以认为是“最佳实践”,因为每个对象都是全特性的key,JSON解析特别块,尤其是一次性查询很多个字段的时候。但是如果只查询一个字段,速度就显得比较慢了
也可以认为是最佳实践,每个对象都是一个全特性的key,不需要解析JSON字符串。但是如果要查询对象的全部字段会比较慢并且嵌套类型的对象无法轻易存储。
HMSET users {id} ‘{“name”:“Fred”,“age”:25}’
这个方案可以仅用两个key,不需要很多key。但是没法对每个用户对象设置TTL(Time to Live,剩余生存时间),因为对象仅仅是hash中的一个字段,而不是全特性的key
这种方式对主key的命名空间污染更少,如果要存储很多对象,那么内存使用和方案1相当。当只需要查询一个字段时,会比方案2速度慢。
- 存储对象的每个属性作为单独的key
原文地址:https://blog.csdn.net/liuwanqing233333/article/details/129131373
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_46052.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






