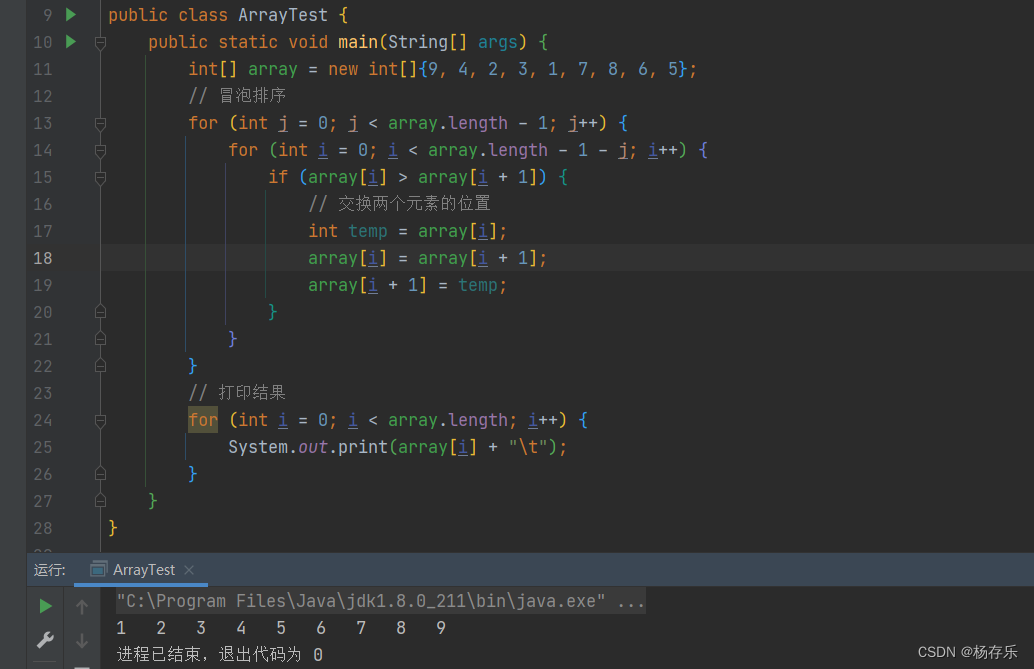
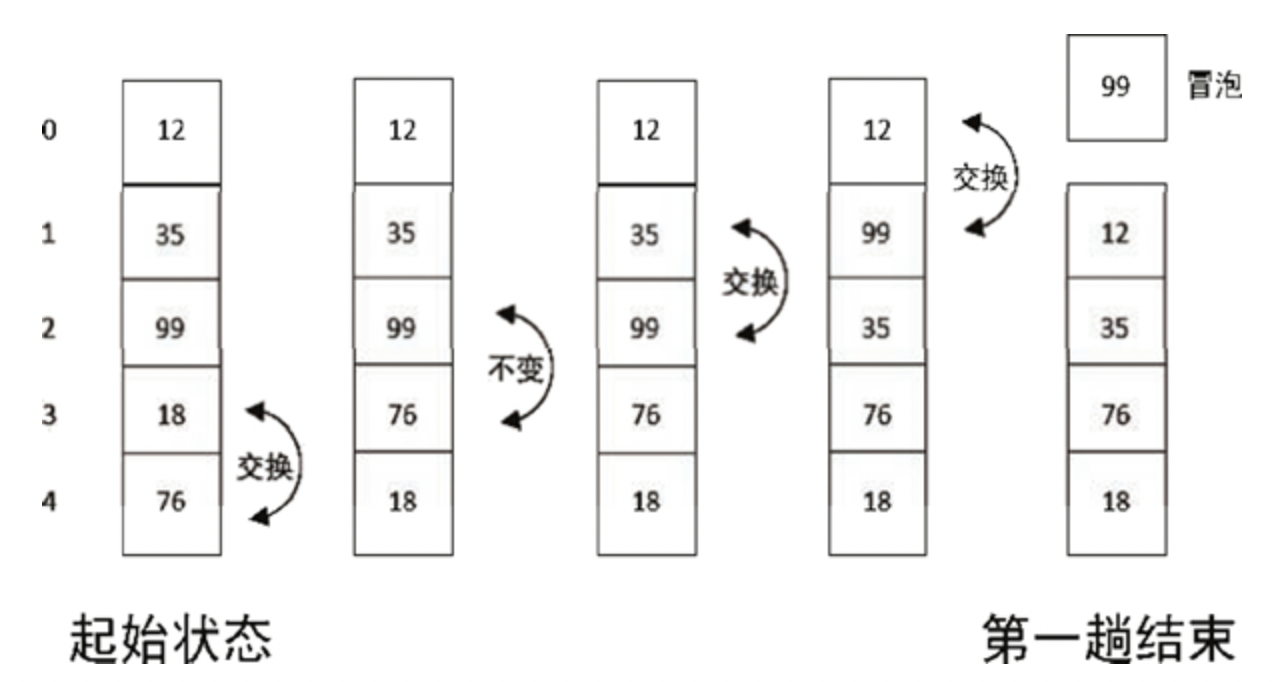
Hello everybody!今天打算给大家介绍一个功能比较强大的数据结构的基础,它不仅具有很高的应用价值而且排序效率很高。冒泡排序都知道叭,它的时间复杂度为O(n^2),而堆排序的时间复杂度为O(n*logn)。堆排序直接碾压冒泡排序。在c语言阶段,我曾给过大家qsort函数模拟实现的代码,我是以冒泡排序为底层逻辑实现的:时间复杂度为O(n^2)。而真正库文件中的qsort是以快排为底层逻辑实现的:时间复杂度为O(n*logn)。所以当我们排较长的数值时,肉眼可见的会发现自己模拟实现的qsort的效率远远不及库文件中的qsort。这就很好的体现了时间复杂度为O(n*logn)的数据结构的魅力所在!那好,废话不多说,我们直接开始叭!

1.二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
1.顺序结构
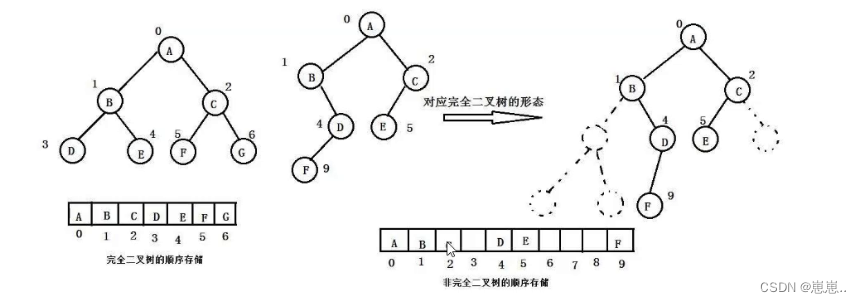
顺序结构存储就是使用数组来存储,一般使用数组只适合完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
2.链式存储
二叉树的链式存储结构是指,用链表来表示一颗二叉树,即用链来指示元素的逻辑关系。通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。链式结构又分为二叉链和三叉链。在当前的知识将借助一般都是二叉链,后面的高阶数据结构如红黑树等会用到三叉链。

2.堆的基本结构
3.接口的实现
3.1初始化&销毁
3.2插入数据
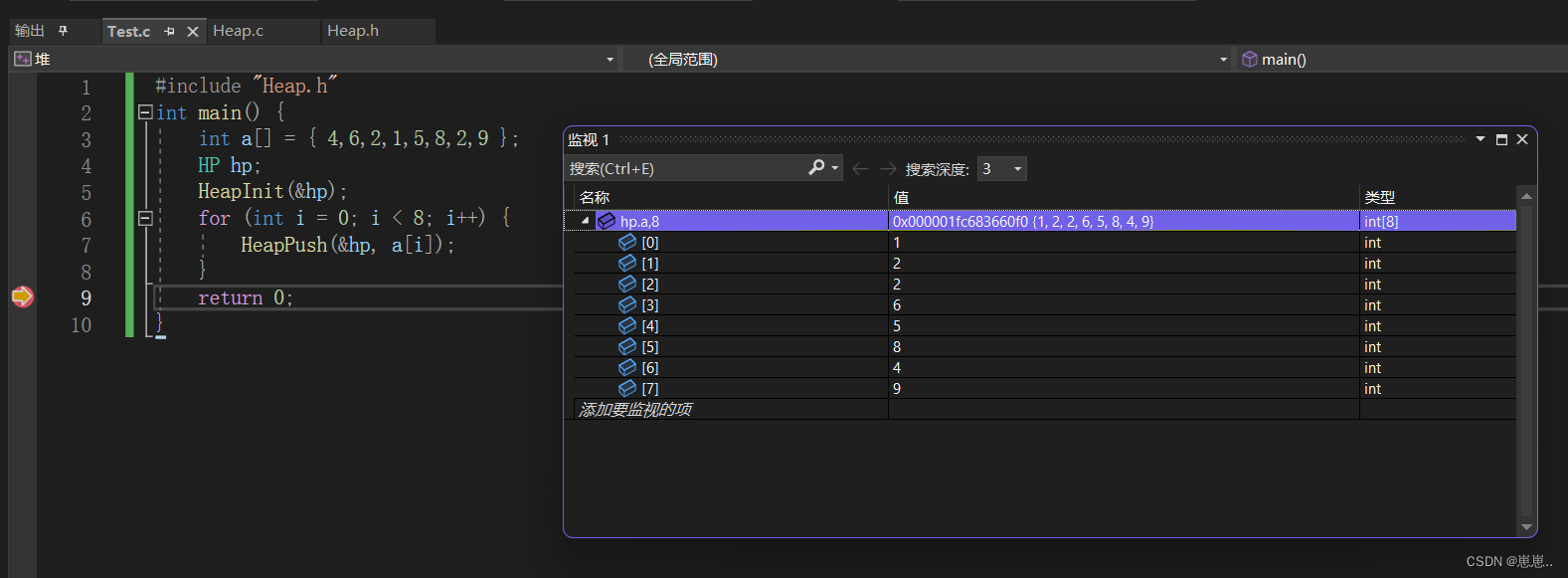

3.3删除堆顶
3.4结点个数&访问根节点&判空

4.代码
5.结语
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。