写在开头
在数据分析的世界里,选择合适的工具至关重要。本篇博客将深入比较常用的数据分析工具,包括Excel、Python和R,以帮助读者更好地选择适合自己需求的工具。
1.Excel:经典易用的电子表格
优势:
示例场景1(销售趋势分析):

使用excel后,制作可视化分析结果:
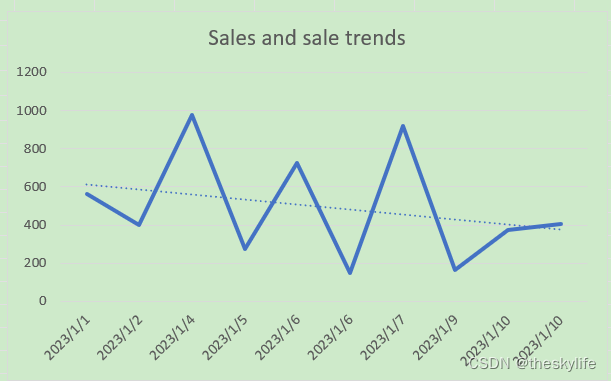
从上面的图表上来看,虽然数据有所波动,但从趋势线来看,整体的销售额呈现下滑的趋势。
示例场景2(销售排名分析):
假如我们要对上述场景1中的数据进行销售额排名,看销售额最好和最差的是哪款产品。
打开excel,绘制柱状图,结果如下:
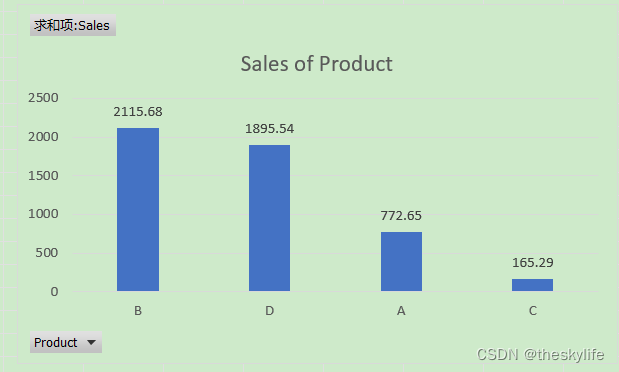
从上面的图标中可以看出,在数据源中,销售情况最好的是产品A,为2115.68,销售情况最差的是产品C,为165.29。
因此,我们可能要对B和产品C进行复盘,看究竟是什么原因造成上述的差异,从而对产品本身或者销售过程进行优化,最终实现销售额的增长。
示例场景3 (关联性分析)
假如我们要对上述场景1中的数据进行进一步探索,从而找出与销售额情况相关的因子。
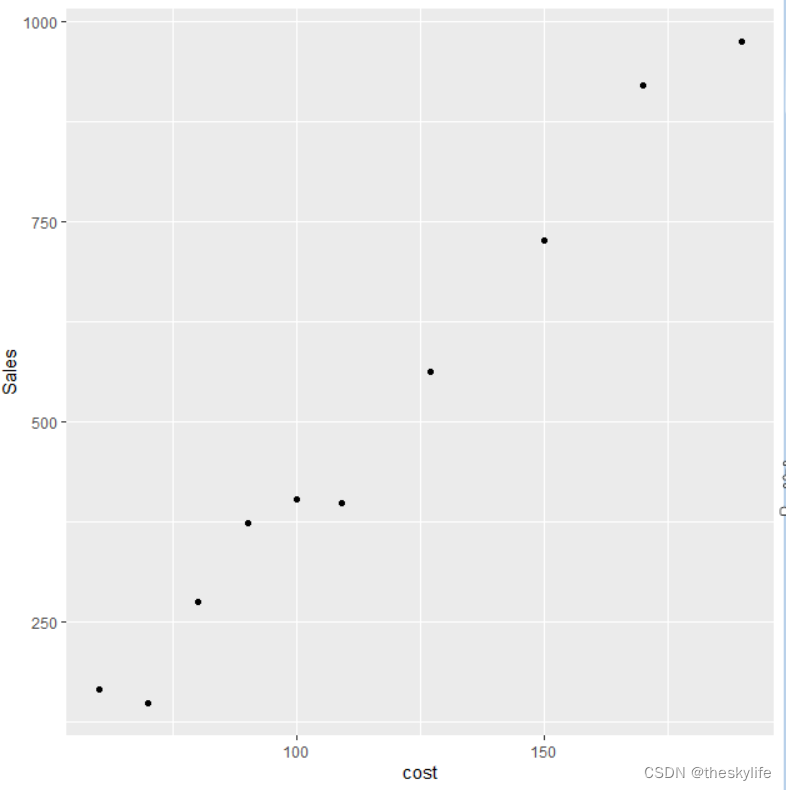
打开excel,绘制散点图,结果如下:
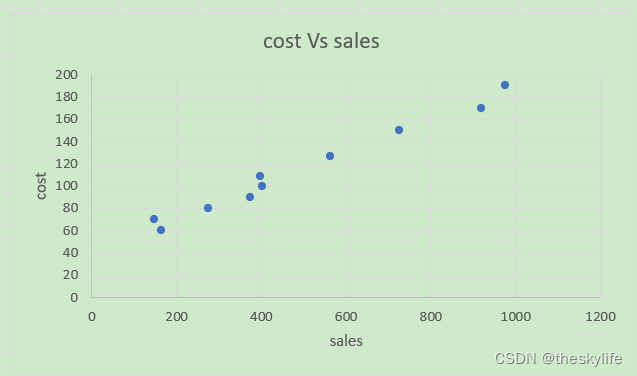
从上述散点图中,我们能够直观的发现销售额和销售投入之间存在相关关系。
为了进一步验证相关性的强弱,我们在excel中进行相关系数分析,分析结果如下:
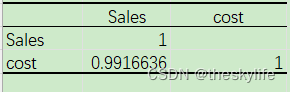
从上面的截图中看出,相关系数为0.99,因此这两者之间的关联性非常的强。补充知识:
示例场景4 (建立数学模型)
从场景3中,我们可以看到sales和cost之间存在强的相关关系,那我们能否建立一个模型来反应两者的关系?
利用excle进行回归分析,得出下面的结果:
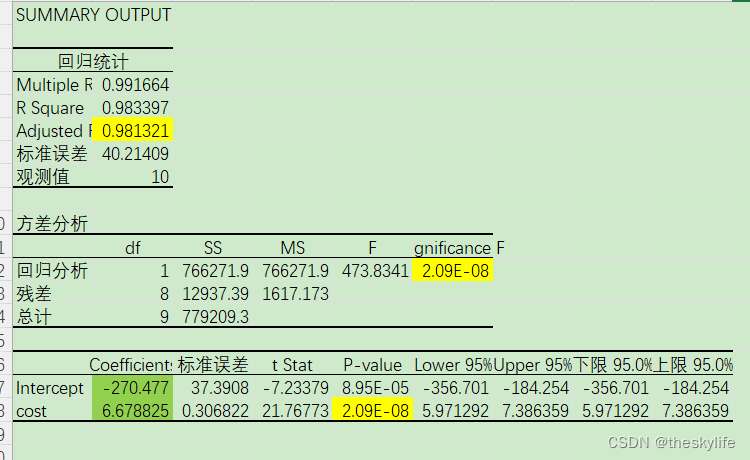
从上述截图(标颜色区域需要特别留意)中,我们可以得出对应的关系式为
2.Python:灵活多变的利器
优势:
示例场景1(计算平均值):
示例场景2(计算产品的销售额排名):

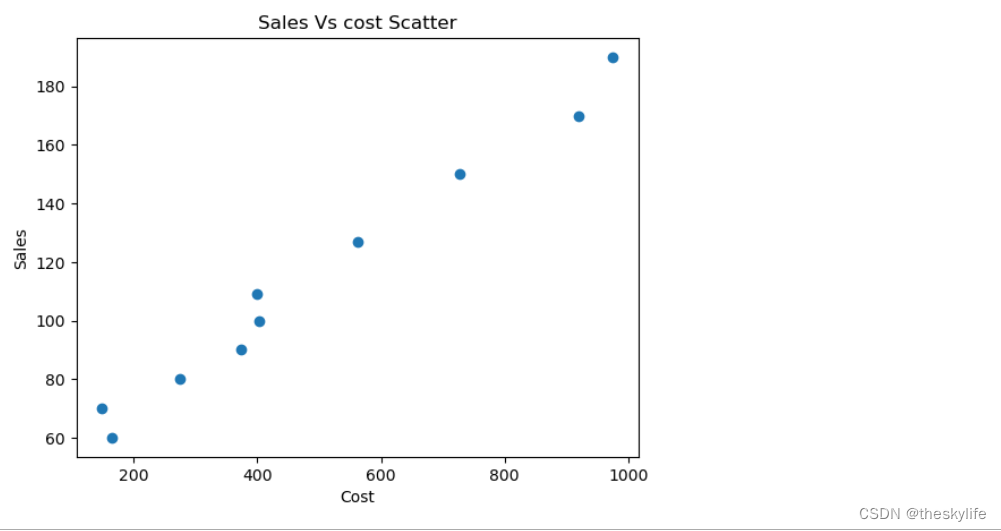
示例3(绘制散点图)
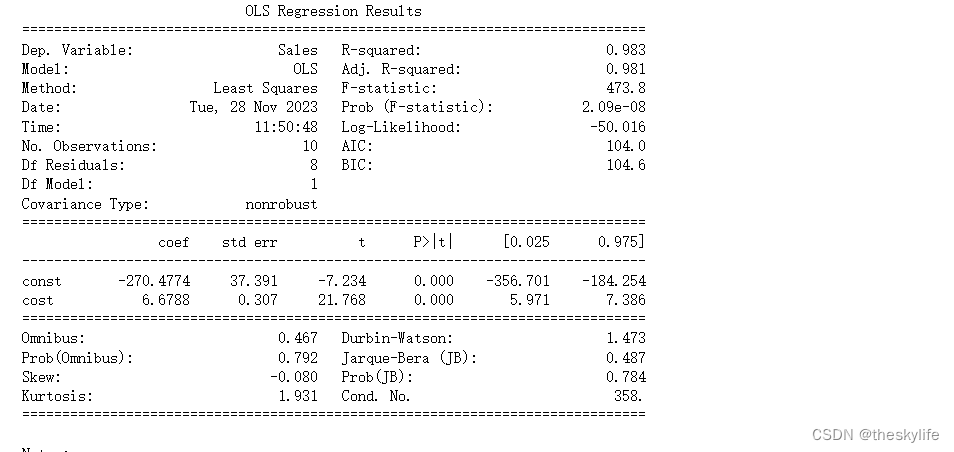
示例4(进行回归分析)
3.R:统计分析的精灵
优势:
示例场景1(计算平均值):
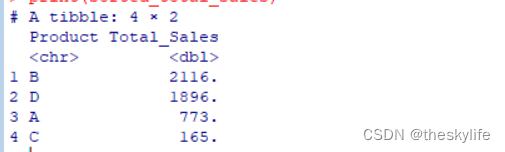
示例场景2(计算产品的销售额排名):
4.三个工具对比与选用建议
写在最后
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




![[office] sumifs函数和sump #媒体#学习roduct哪个运算更快–Excel函数 #职场发展#媒体](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)

