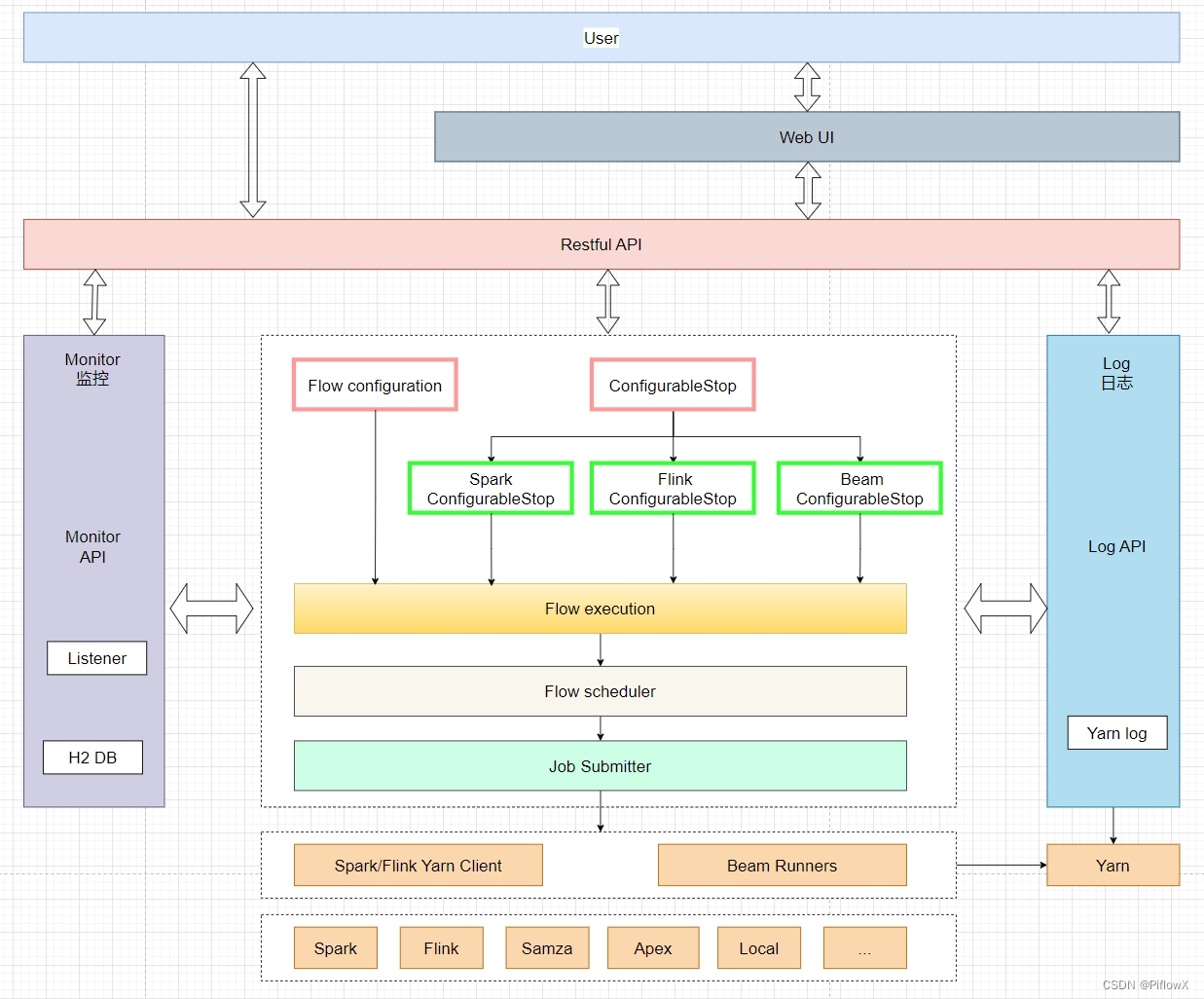
欢迎来到我们的技术博客!今天,我们要探讨的主题是Apache Spark的一个核心组件——Structured Streaming。作为一个可扩展且容错的流处理引擎,Structured Streaming使得处理实时数据流变得更加高效和简便。
什么是Structured Streaming?
Structured Streaming是基于Apache Spark SQL引擎构建的高级流处理框架。它允许用户使用SQL查询语言以及DataFrame和DataSet API来操作流数据,从而简化了复杂数据流的处理。
核心概念
Structured Streaming的核心在于将实时数据流视为动态表(即DataFrame或Dataset)。这意味着你可以使用熟悉的Spark SQL操作来处理这些数据流,并定义输出接收器来持续接收处理结果。随着新数据的不断到来,Spark SQL引擎会实时更新结果表。
输入表
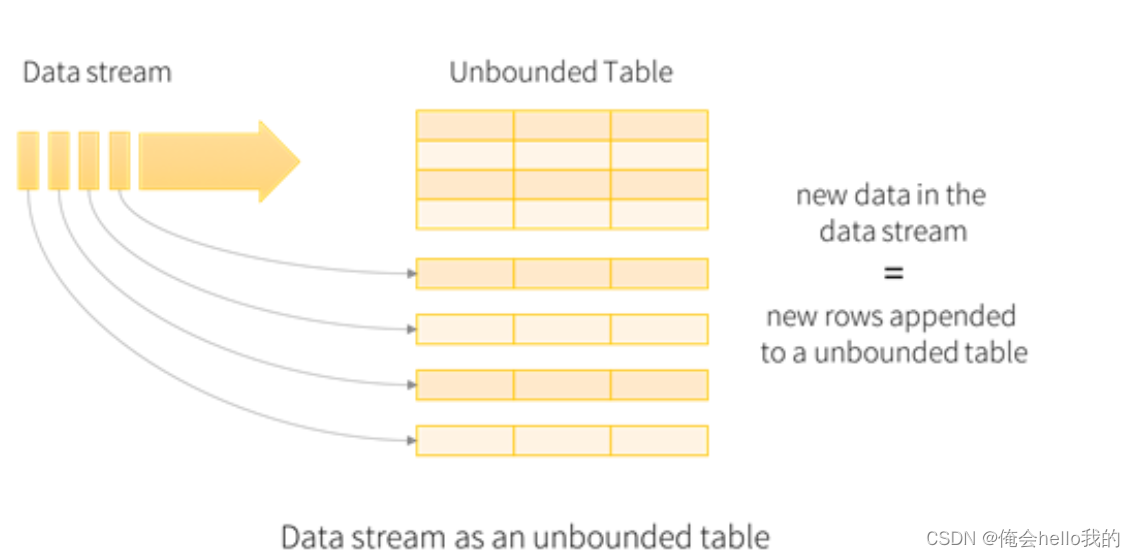
输出表
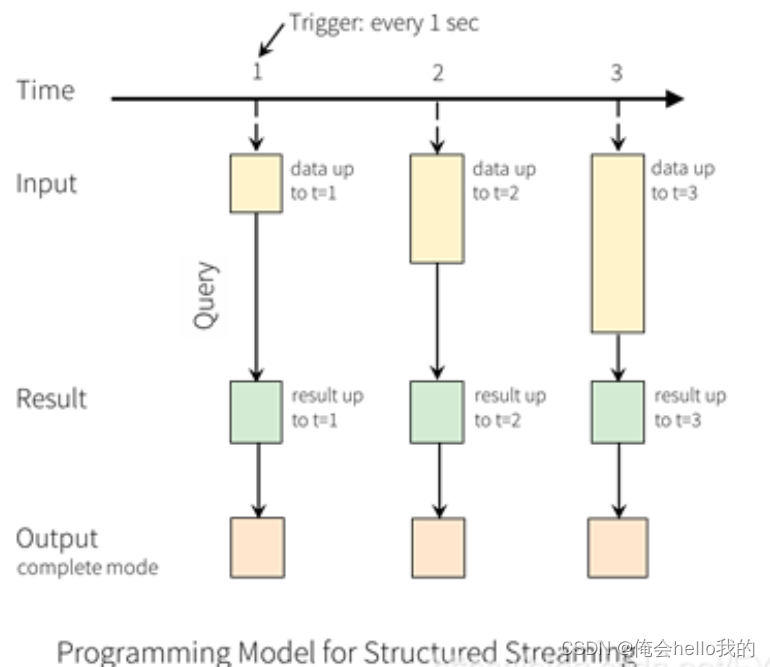
关键特性
-
触发器:
应用示例
以下是一个Structured Streaming应用的简单示例。该程序从TCP套接字读取实时文本数据,并计算每个单词的出现频率。
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
# 创建Spark会话
spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
# 创建代表来自localhost:9999的输入文本流的DataFrame
lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
# 将行拆分为单词
words = lines.select(explode(split(lines.value, " ")).alias("word"))
# 计算每个单词的出现次数
wordCounts = words.groupBy("word").count()
# 启动查询并将结果打印到控制台
query = wordCounts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
结语
Structured Streaming为处理复杂的实时数据流提供了一个强大、灵活且易于使用的解决方案。无论是初学者还是有经验的Spark开发者,都可以从中受益,高效地构建实时数据处理应用。
原文地址:https://blog.csdn.net/weixin_53285092/article/details/134692935
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_46318.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!