本文介绍: HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。Hadoop是一个能够让用户轻松搭建和使用的分布式计算平台,能够让用户轻松地在Hadoop上开发和运行处理海量数据的应用程序。
1 Hadoop的简介
Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案。Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
2 Hadoop的特点
Hadoop是一个能够让用户轻松搭建和使用的分布式计算平台,能够让用户轻松地在Hadoop上开发和运行处理海量数据的应用程序。Hadoop的主要特点如下。
1)高可靠性。Hadoop的数据存储有多个备份,集群部署在不同机器上,可以防止一个节点宕机造成集群损坏。当数据处理请求失败时,Hadoop将自动重新部署计算任务。
2)高扩展性。Hadoop是在可用的计算机集群间分配数据并完成计算任务的。为集群添加新的节点并不复杂,因此可以很容易地对集群进行节点的扩展。
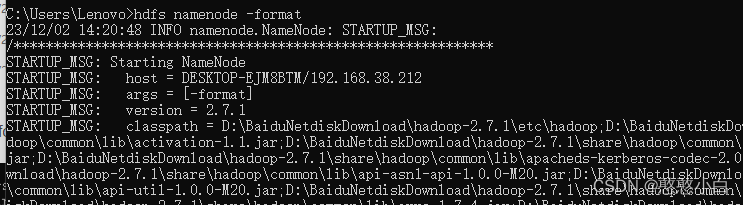
3、windows上安装Hadoop.
1、安装JDK
2、配置环境变量
(配置HADOOP_HOME,环境变量path添加%HADOOP_HOME%bin)

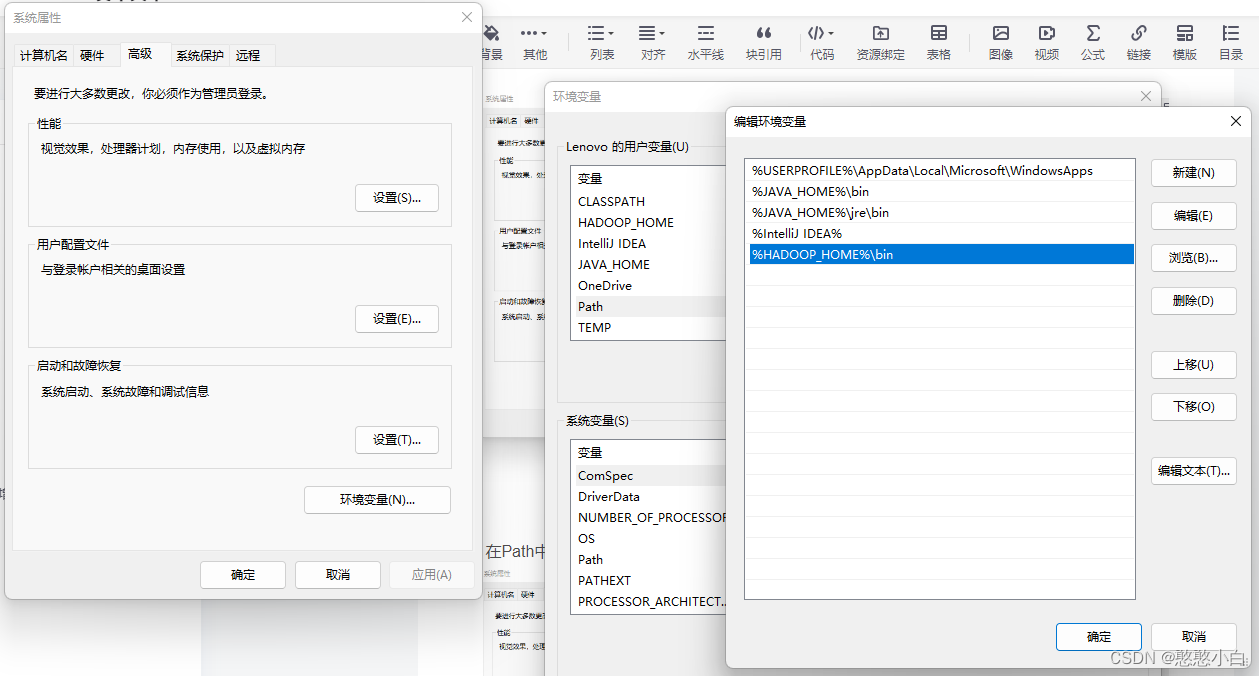
3、使用快捷键win+R后输入cmd确认->弹出dos界面输入set确认是否配置成功。


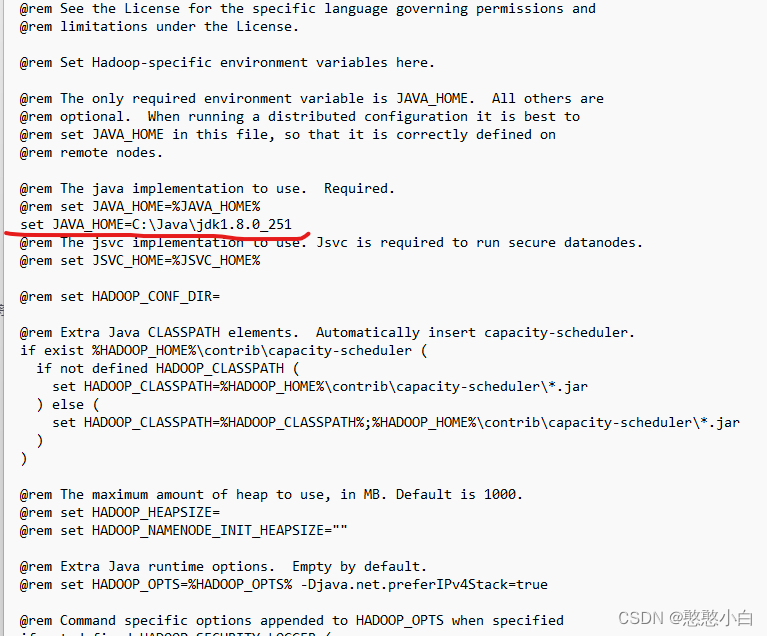
4、对hadoop-2.7.1etchadoophadoop-env.cmd中JDK路径进行修改:下面路径修改为jdk安装路径
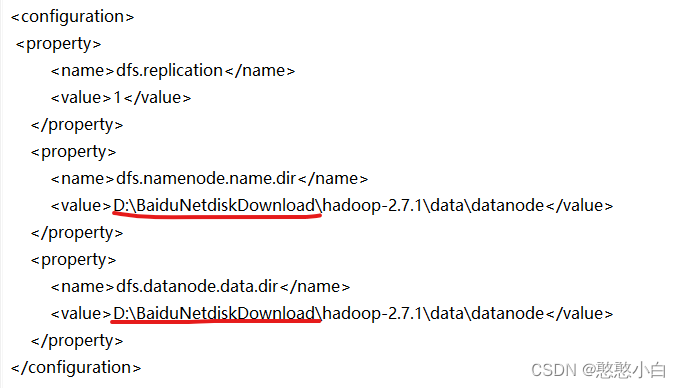
5、对hadoop-2.7.1etchadoophdfs–site.xml的路径进行修改
6、从项目路径hadoop-2.7.1bin下拷贝hadoop.dll到 C:WindowsSystem32 。

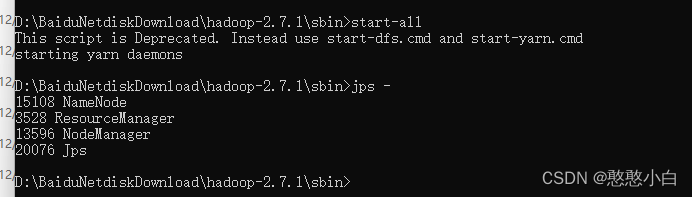
7、转到hadoop-2.7.1sbin文件下,输入start-all,启动hadoop集群
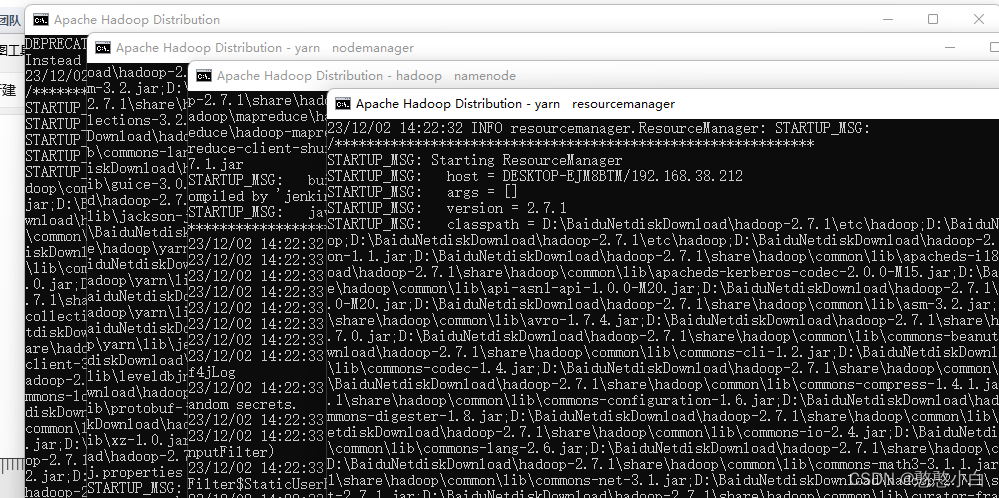
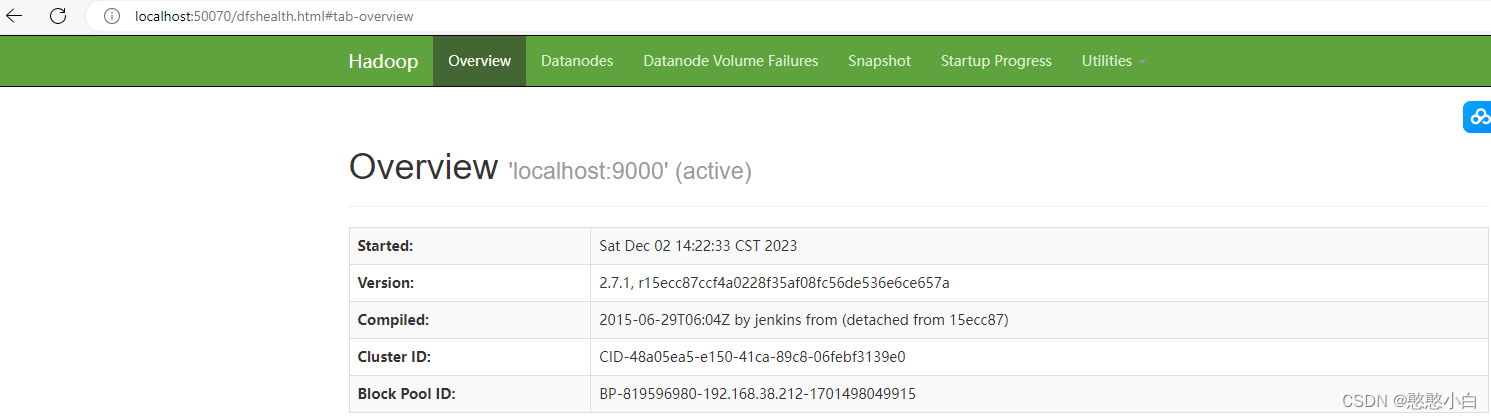
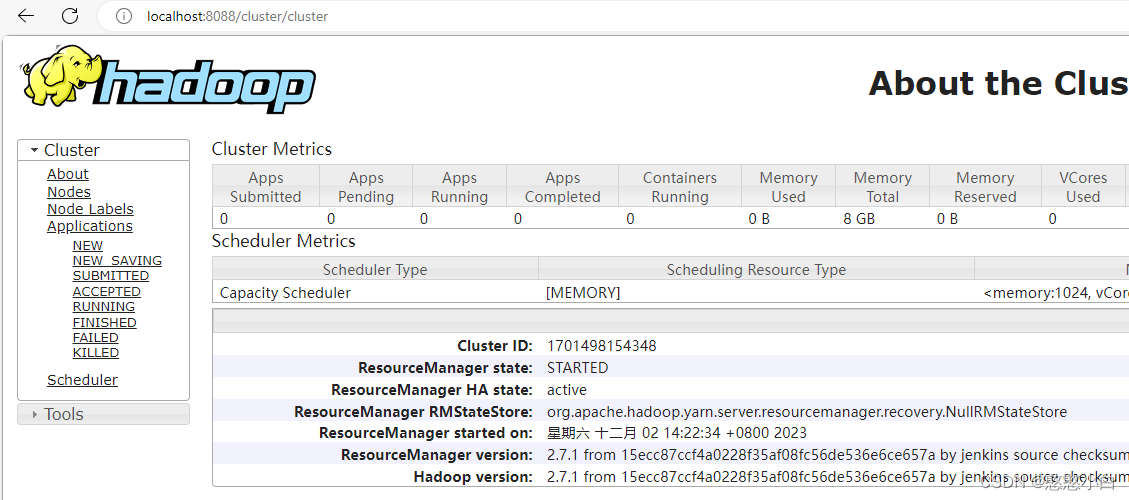
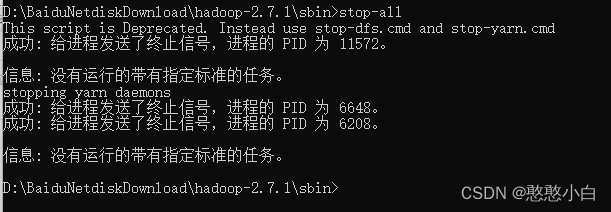
8、停止运行的所有节点的命令stop-all
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。