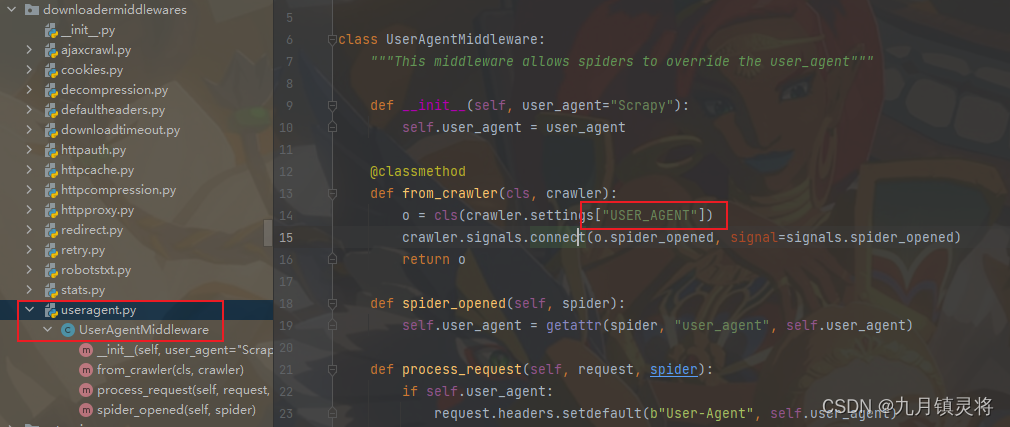
本文介绍: Scrapy中间件是在Scrapy引擎处理请求和响应的过程中,允许你在特定的点上自定义处理逻辑的组件。它们在整个爬取过程中能够拦截并处理Scrapy引擎发送和接收的请求和响应。全局性处理请求和响应: 中间件可以截取所有请求和响应,允许你对它们进行全局性的修改,例如添加自定义的请求头、代理设置或处理响应数据等。自定义爬取过程: 通过中间件,你可以自定义爬取的逻辑。例如,在请求被发送之前,可以通过中间件对请求进行处理,或者在收到响应后对响应进行预处理,以适应特定需求或网站的要求。
简介
Scrapy是一个强大的Python爬虫框架,可用于从网站上抓取数据。本教程将指导你创建自己的Scrapy爬虫。其中,中间件是其重要特性之一,允许开发者在爬取过程中拦截和处理请求与响应,实现个性化的爬虫行为。
本篇博客将深入探讨Scrapy中间件的关键作用,并以一个实例详细介绍了自定义的Selenium中间件。我们将从Scrapy的基本设置开始,逐步讲解各项常用设置的作用与配置方法。随后,重点关注中间件的重要性,介绍了下载器中间件和Spider中间件的作用,并通过一个自定义Selenium中间件的示例,演示了如何利用Selenium实现页面渲染,并在Scrapy中应用该中间件。
如果对您对scrapy不了解,建议先了解一下:
初识Scrapy:Python中的网页抓取神器 – 掘金 (juejin.cn)
编写settings.py
这些设置可以在Scrapy项目中的settings.py文件中进行配置。例如:
以上是一些常用的Scrapy设置,可以根据需要进行调整和扩展,以满足特定爬虫的要求。
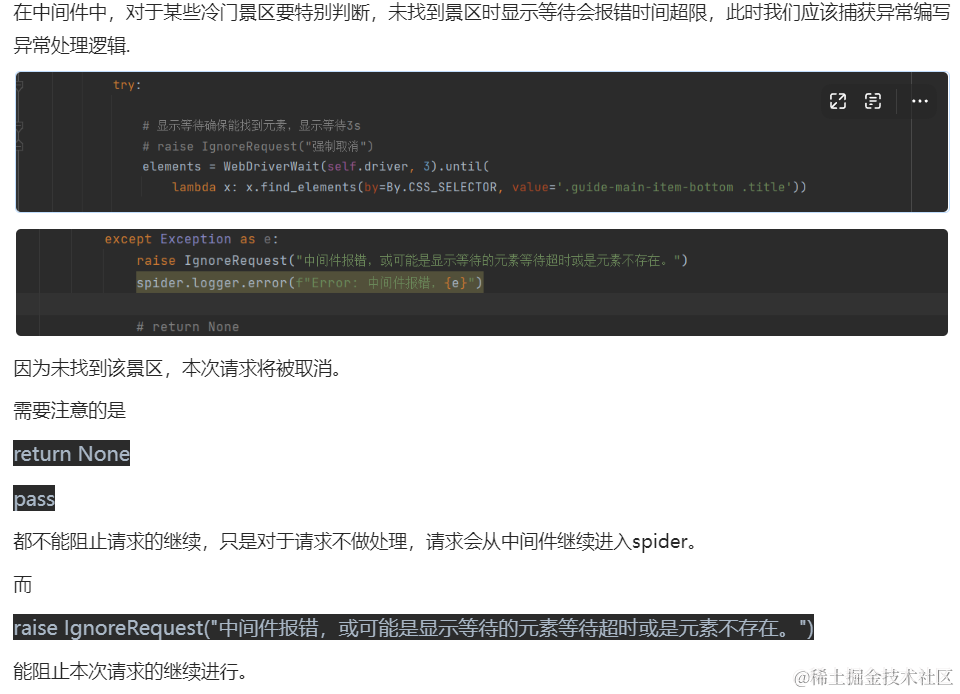
自定义中间件
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。