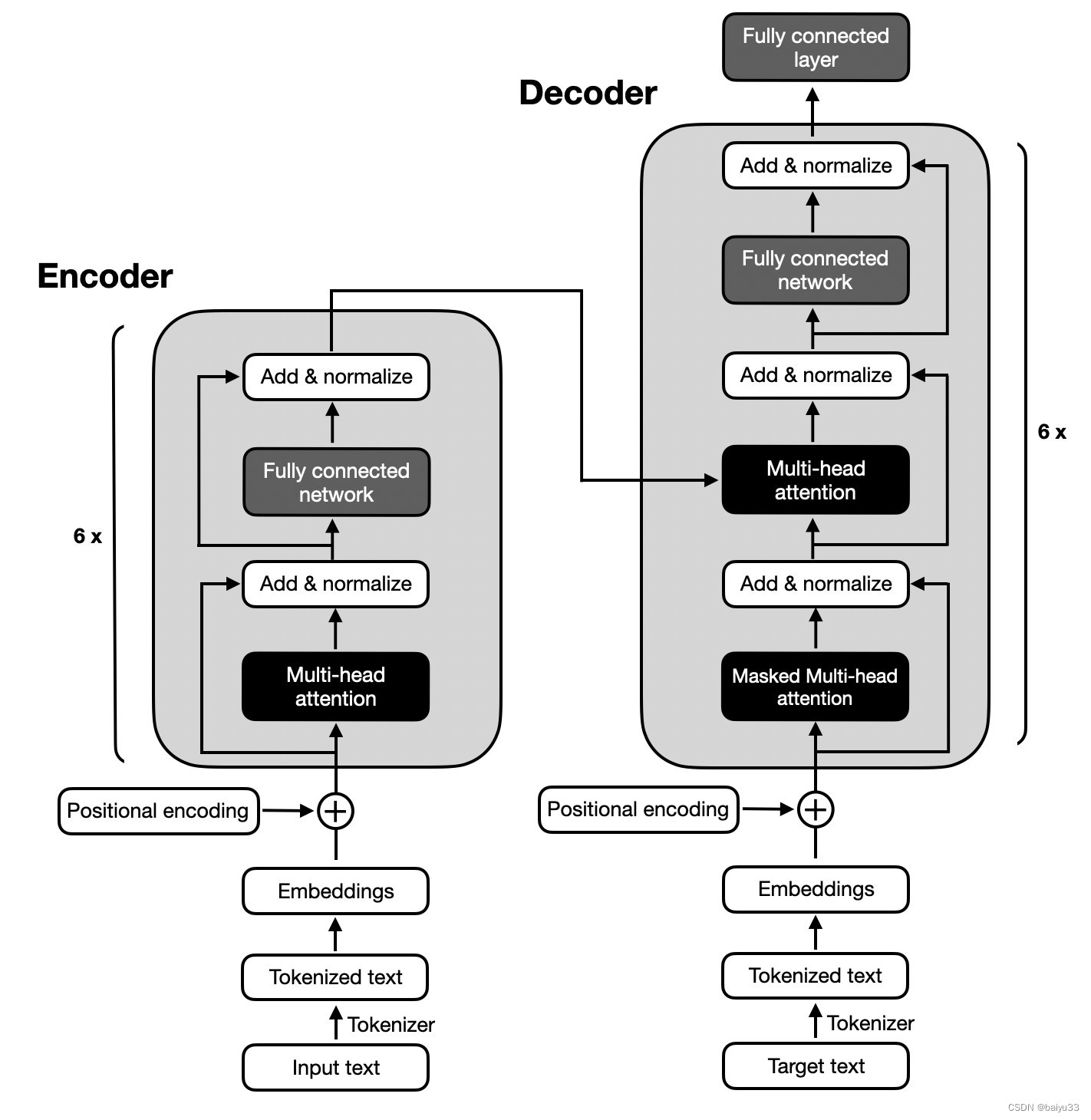
首先LLM有3种架构:Encoder-only、Decoder-only、encode-decode
整体情况
1、Encoder将可变长度的输入序列编码成一个固定长度的向量,比如在bert中应用的encoder,其实是输入和输出是等长的向量。通常情况下,encoder是用来提取特征的,因此更适合用于文本分类、情感分析等任务
2、Decoder将固定长度的向量解码成一个可变长度的输出序列,经常比如gpt中,就是用前面的n个tocken来预测下一个tocken,然后将真实的下一个tocken加入再预测下下个tocken,这里我们猜测能否将预测的tocken也加入,跟真实tocken一起预测呢?形成一种对抗。通常情况下,decoder更适合用于文本生成的工作。
3、Encoder-Decoder是传统的transformer结构,相比较decoder来说更加耗费内存,也更慢一些,它是用encoder先将可变长度编码成固定长度向量,再将固定长度向量解码成可变长度的过程。通常情况下,Encoder-Decoder更适合用于机器翻译这种需要输入特征,并且也要生成不定长序列的情况
参考: 大模型都是基于Transformer堆叠,采用Encoder或者Decoder堆叠,有什么区别?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。