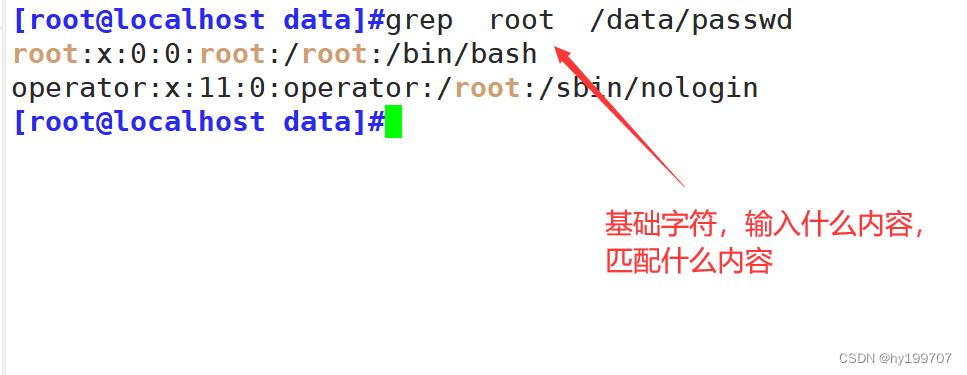
-
前言
- 正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配
- 使用不恰当的正则表达式可能会导致很严重的性能问题
- 比如:
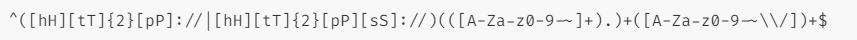
- 这个正则表达式看起来没什么问题,它可以分为三个部分:
- 第一部分匹配 http 和 https 协议,第二部分匹配 www. 字符,第三部分匹配许多字符
- 其实这里会导致 CPU 使用率高的关键原因就是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种正则表达式引擎在进行字符匹配时会发生回溯backtracking
- 而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度
-
正则表达式引擎
- 正则表达式引擎就是一套核心算法,用于建立状态机
- 简单地说,实现正则表达式引擎的有两种方式:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)
- 简单来讲,NFA 对应的是正则表达式主导的匹配,而 DFA 对应的是文本主导的匹配
- 简单来讲,DFA 自动机的时间复杂度是线性的,更加稳定,但是功能有限;而 NFA 的时间复杂度比较不稳定,有时候很好,有时候不怎么好,好不好取决于你写的正则表达式;但是胜在 NFA 的功能更加强大,所以包括 Java、.NET、Perl、Python、Ruby、PHP 等语言都使用了 NFA 去实现其正则表达式
- 那 NFA 自动机到底是怎么进行匹配的呢?我们以下面的字符和表达式来举例说明:

- 要记住一个很重要的点,即:NFA 是以正则表达式为基准去匹配的
- 也就是说,NFA 自动机会读取正则表达式的一个一个字符,然后拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,否则继续和目标字符串的下一个字符比较
- 上面这个匹配过程就是 NFA 自动机的匹配过程,但实际上的匹配过程会比这个复杂非常多,但其原理是不变的
-
NFA自动机的回溯
- 了解了 NFA 是如何进行字符串匹配的,接下来我们就可以讲讲这篇文章的重点了:回溯
- 为了更好地解释回溯,我们同样以下面的例子来讲解:

- 上面的这个例子的目的比较简单,匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串
- NFA 对其解析的过程是这样子的:
- 首先,读取正则表达式第一个匹配符 a 和 字符串第一个字符 a 比较,匹配了
- 于是读取正则表达式第二个字符
- 读取正则表达式第二个匹配符 b{1,3} 和字符串的第二个字符 b 比较,匹配了
- 但因为 b{1,3} 表示 1-3 个 b 字符串,以及 NFA 自动机的贪婪特性(也就是说要尽可能多地匹配),所以此时并不会再去读取下一个正则表达式的匹配符,而是依旧使用 b{1,3} 和字符串的第三个字符 b 比较,发现还是匹配
- 于是继续使用 b{1,3} 和字符串的第四个字符 c 比较,发现不匹配了
- 此时就会发生回溯
- 发生回溯是怎么操作呢?
- 发生回溯后,我们已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符串的位置
- 之后,程序读取正则表达式的下一个操作符 c,读取当前指针的下一个字符 c 进行对比,发现匹配
- 于是读取下一个操作符,但这里已经结束了
- 下面我们回过头来看看前面的那个校验 URL 的正则表达式:

- 出现问题的 URL 是:

- 我们把这个正则表达式分为三个部分:
- 我们可以发现正则表达式校验协议 http:// 这部分是没有问题的,但是在校验 www.fapiao.com 的时候,其使用了 xxxx. 这种方式去校验
- 那么匹配过程是这样的:
- 这是这个正则表达式存在的第一个问题
- 另外一个问题是在正则表达式的第三部分,我们发现出现问题的 URL 是有下划线(_)和百分号(%)的,但是对应第三部分的正则表达式里面却没有
- 这样就会导致前面匹配了一长串的字符之后,发现不匹配,最后回溯回去
- 这是这个正则表达式存在的第二个问题
-
解决方案
- 明白了回溯是导致问题的原因之后,其实就是减少这种回溯,你会发现如果我在第三部分加上下划线和百分号之后,程序就正常了

- 运行上面的程序,立刻就会打印出match!!
- 但这是不够的,如果以后还有其他 URL 包含了乱七八糟的字符呢,我们难不成还再修改一遍
- 肯定不现实
- 其实在正则表达式中有这么三种模式:贪婪模式、懒惰模式、独占模式
- 在关于数量的匹配中,有 + ? * {min,max} 四种两次,如果只是单独使用,那么它们就是贪婪模式
- 如果在他们之后多加一个 ? 符号,那么原先的贪婪模式就会变成懒惰模式,即尽可能少地匹配
- 但是懒惰模式还是会发生回溯现象
- 例如下面这个例子:

- 正则表达式的第一个操作符 a 与 字符串第一个字符 a 匹配,匹配成功
- 于是正则表达式的第二个操作符 b{1,3}? 和 字符串第二个字符 b 匹配,匹配成功
- 因为最小匹配原则,所以拿正则表达式第三个操作符 c 与字符串第三个字符 b 匹配,发现不匹配
- 于是回溯回去,拿正则表达式第二个操作符 b{1,3}? 和字符串第三个字符 b 匹配,匹配成功
- 于是再拿正则表达式第三个操作符 c 与字符串第四个字符 c 匹配,匹配成功;于是结束
- 如果在他们之后多加一个 + 符号,那么原先的贪婪模式就会变成独占模式,即尽可能多地匹配,但是不回溯
- 于是乎,如果要彻底解决问题,就要在保证功能的同时确保不发生回溯
- 将上面校验 URL 的正则表达式的第二部分后面加多了个 + 号,即变成这样:

- 这样之后,运行原有的程序就没有问题了
原文地址:https://blog.csdn.net/weixin_59624686/article/details/134794667
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_46944.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。