诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Language Models as Knowledge Bases?
ArXiv网址:https://arxiv.org/abs/1909.01066
官方GitHub项目:https://github.com/facebookresearch/LAMA
本文是2019年EMNLP论文,作者来自脸书和伦敦大学学院。
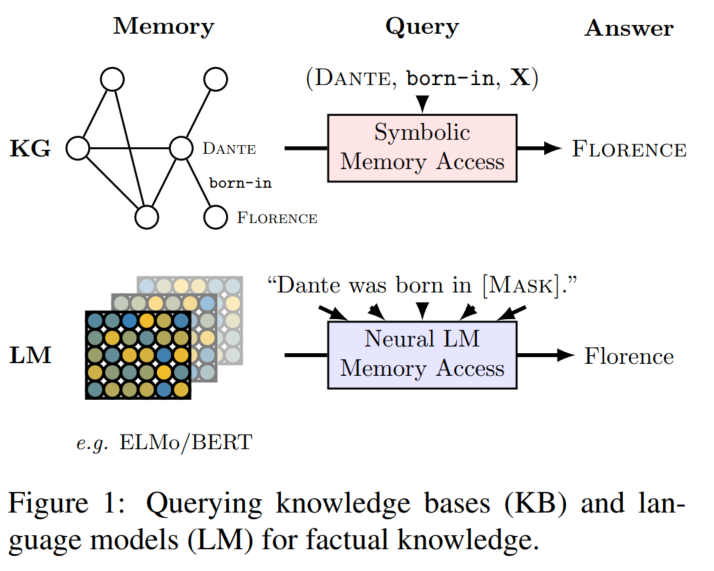
本文关注LM中蕴含的知识,想要探索的问题是,通过在大型的文本语料上进行预训练,语言模型是否已经(或是有潜力)学习到并存储下了一些事实知识(主体-关系-客体形式的三元组 (subject, relation, object) 或是问题–答案对)?
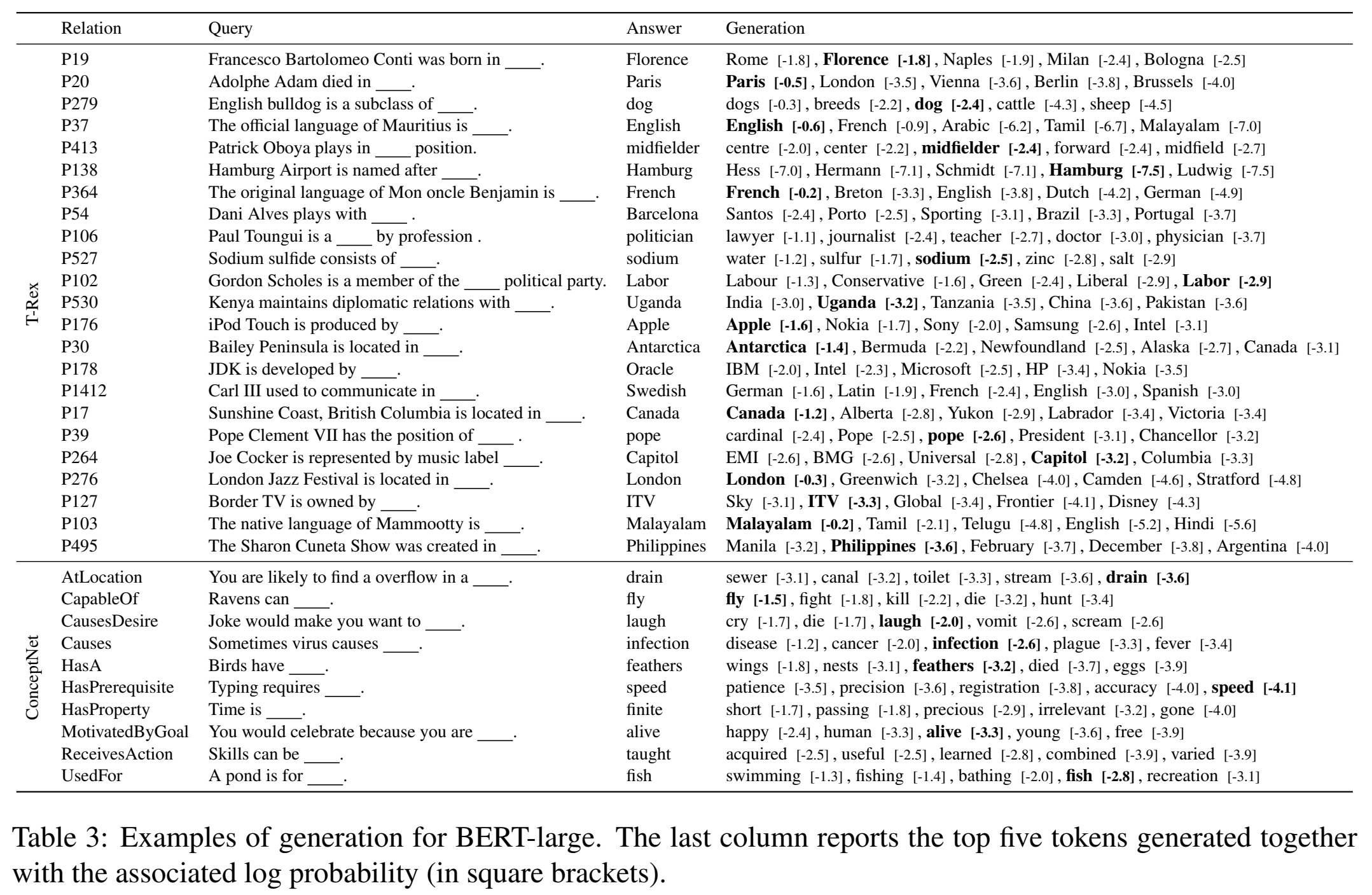
本文通过将事实三元组转换为自然语言形式,让LM(未经过微调的)用完形填空的形式来预测其中的object(把relation反过来也能预测subject),来进行这一探查:LAMA (LAnguage Model Analysis)
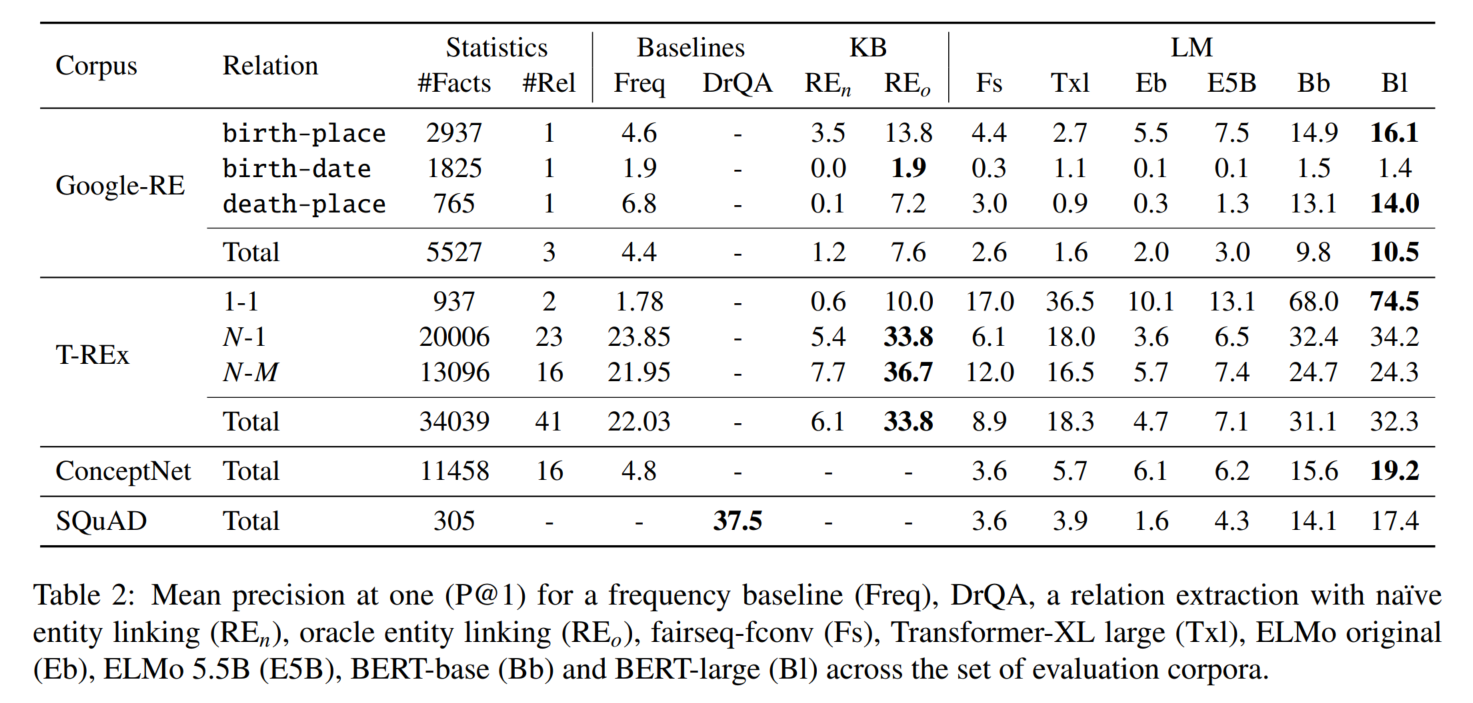
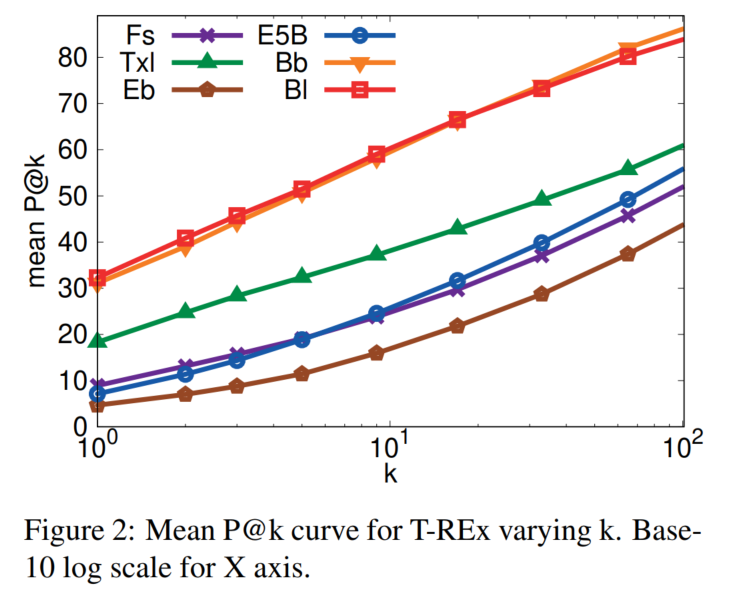
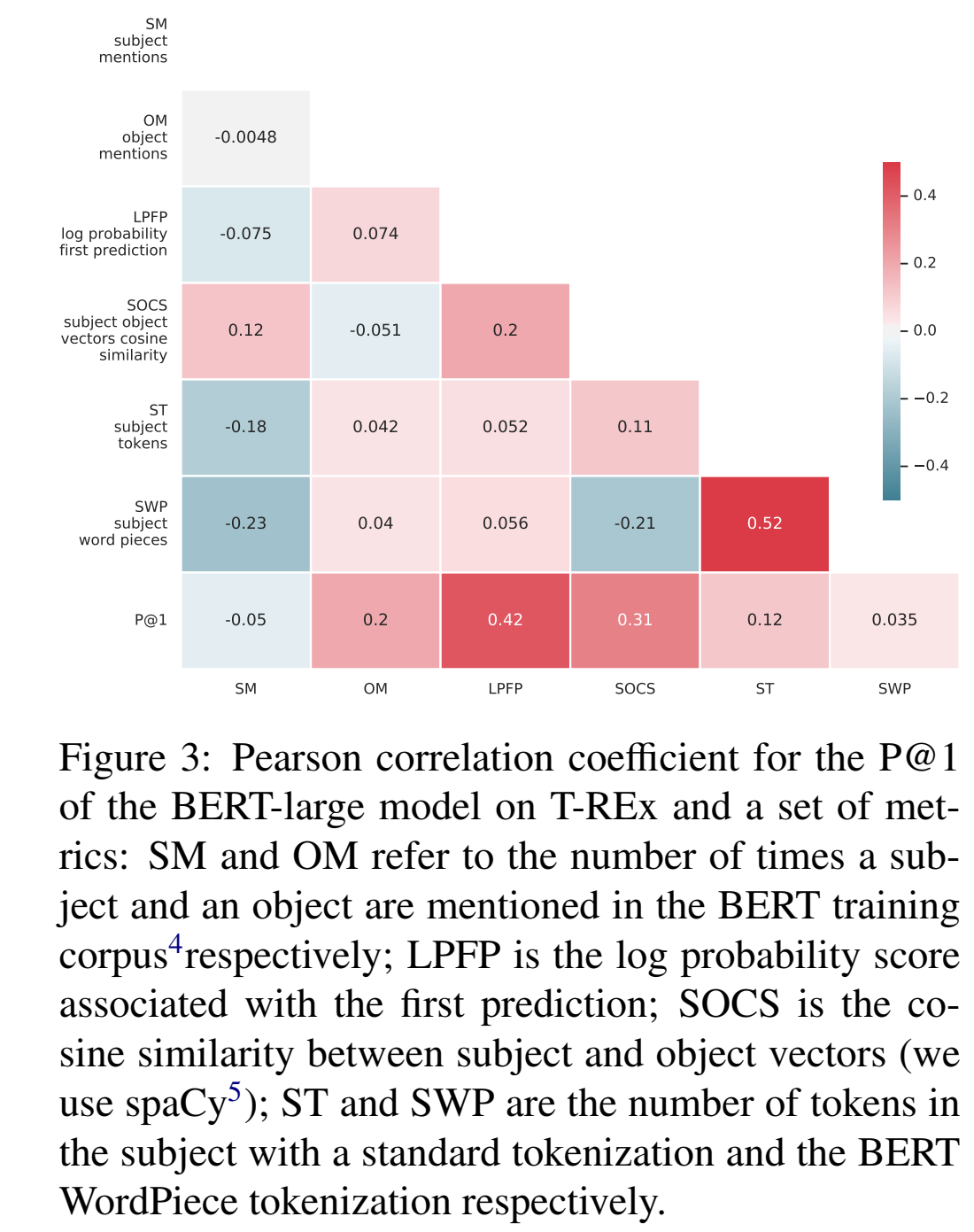
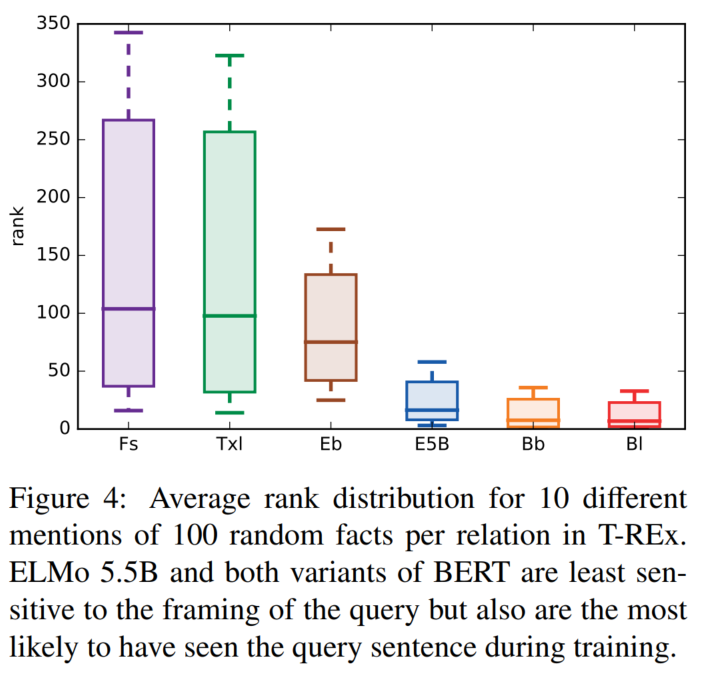
评估正确结果的排序
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。