上海大学计算机体系结构实验四 HPL安装和测试(虚拟机centos7.6环境下保姆级教程!)
CSDN上的安装测试有很多,但在实际安装过程中经常碰到博客的教程缺了中间的某个指令,或者漏了某个配置(写的不完全)导致报错的情况,一波三折下来直接心态搞崩,不过好在最后终于是成功了。
特此我详细记录下本次HPL安装和测试的过程,给自己一个参考,也给其他人一个参考。(本过程仅在我的centos7.6虚拟机上安装成功,若有其他报错问题可以评论区告诉我)
一. 实验环境
接下来的安装顺序也是按照BLAS-3.8.0->CBLAS->MPICH-3.2.1->HPL-2.3来进行。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kvlb0uON-1683801947680)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511160212939.png)]](https://img-blog.csdnimg.cn/d6695c5526c641698f730fdaa5e12ee0.png)
二. 环境搭建
1、安装配置GCC和GFortran(这很重要,后面可能有人会出现G77不存在的报错,需要修改为GFortran)
2、下载安装BLAS-3.8.0(用来做矩阵计算或者向量计算的库)
2.1首先进入主目录,一般是/home/(你的usr名称)页面,一般点击下图的主目录即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3TEDXEw2-1683801947680)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511161705624.png)]](https://img-blog.csdnimg.cn/5ed3195dd3a4488b897497b0e2c88855.png)
2.2 直接在主目录右键打开终端,通过wget指令联网(虚拟机要能够联网)下载BLAS-3.8.0,然后解压在主目录即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fAD0HMjx-1683801947681)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511161946776.png)]](https://img-blog.csdnimg.cn/5ed9da0036bb40889ed0e8bf547a01d5.png)
2.3 输入下面两条指令编译生成blas_LINUX.a文件:make命令

2.4 链接.o文件生成libblas.a文件
2.5 复制一份blas_LINUX.a和libblas.a库文件到系统/usr/local/lib目录下(后续安装hpl配置环境时需要用到)
3、安装CBLAS(是BLAS的C语言接口)
3.1 回到主目录右键打开终端,输入指令下载cblas.tgz并解压
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5eT3uIJb-1683801947683)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511163750280.png)]](https://img-blog.csdnimg.cn/8e85fcb7bfce4e2d9a1920de2555ae7d.png)

3.2 进入CBLS文件夹下,使用绝对路径将处于BLAS-3.8.0文件夹下的blas_LINUX.a库文件拷贝到CBLS文件夹下
3.3 编译CBLS,CBLAS安装目录下的lib目录中产生一个静态链接库文件 cblas_LINUX.

3.4 修改 Makefile.in 文件中的 BLLIB字段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YLUFj2L4-1683801947684)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511164021433.png)]](https://img-blog.csdnimg.cn/e59d75f39f5d44118058f3ac303cb49e.png)
3.5 复制一份cblas_LINUX.a库文件到系统/usr/local/lib目录下(后续安装hpl配置环境时需要用到)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MlLGXRaW-1683801947685)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511165023165.png)]](https://img-blog.csdnimg.cn/6218c22233334bfbb6e8fb703953d084.png)
3.6 测试运行(hpl安装完成后可以返回进行测试)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FVMNbIDQ-1683801947685)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511164731000.png)]](https://img-blog.csdnimg.cn/32ead308f641459e84b5aa393150b81d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tsV0mUVo-1683801947686)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511164502212.png)]](https://img-blog.csdnimg.cn/686665100a444e8581c6f79fa2dbc509.png)
4、安装MPICH-3.2.1(用于并行运算的工具)
4.1 回到主目录右键打开终端,输入指令下载并解压mpich-3.2.1.tar.gz
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9KRZXvi2-1683801947686)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511165818866.png)]](https://img-blog.csdnimg.cn/7325b86637df4aba9ac7dcb9895b9f8a.png)
4.2 输入下面两条指令进入mpich文件夹下并设置安装路径
4.3 编译
4.4 安装
4.5 配置环境变量
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6gQmNMqj-1683801947687)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511171349787.png)]](https://img-blog.csdnimg.cn/81fe7517d79540549b16ca8488dbd05f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7xDGH2Z-1683801947687)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511171432790.png)]](https://img-blog.csdnimg.cn/7c31b6aa4c774a7bb51b4c299dc414dc.png)
4.6 查看前面工作是否成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7fzF9Jwu-1683801947688)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511171603669.png)]](https://img-blog.csdnimg.cn/935d399b305044c8b2e7ba8694b684d1.png)
5、安装HPL-2.3
5.1 查看/usr/local/lib目录下是否存在blas_LINUX.a和cblas_LINUX.a文件,若没有,请仔细阅读上文的步骤2和3的结尾部分,需要复制一份进去。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5GowGY6r-1683801947688)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511165023165.png)]](https://img-blog.csdnimg.cn/3007c4ed1c3e44d789e6fff825ac6cfd.png)
5.2 回到主目录右键打开终端,输入指令下载并解压hpl测试包
5.3 进入hpl-2.3文件夹,将setup文件夹下的Make.Linux_PII_CBLAS文件复制到hpl-2.3文件夹下(手动进入setup文件夹复制也行)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zkOnUrtV-1683801947689)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511172636667.png)]](https://img-blog.csdnimg.cn/77ce1f995252444a9a76ebce5e2ad53a.png)
5.4 配置环境参数(这一步极其重要,配错了就GG)






5.5 编译
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zC9YB0Ax-1683801947692)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511173843306.png)]](https://img-blog.csdnimg.cn/a70fcaae26dc455097a5d00b49fd022e.png)
5.6 运行测试,将测试结果写入到HPL-Benchmark.txt文件中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nHbqJa1j-1683801947693)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511173945847.png)]](https://img-blog.csdnimg.cn/107d0ba90d62452e85dd85e18b30d2a5.png)
至此hpl安装成功!可以返回到步骤3进行CBLAS的二次测试
三、hpl的测试
3.1 查看cpu详细参数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bd5NbIbp-1683801947693)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511181428825.png)]](https://img-blog.csdnimg.cn/0a4bd048ead84cb1ae2c82955269ab22.png)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QObDhHRl-1683801947693)(C:UserslvAppDataRoamingTyporatypora-user-imagesimage-20230511184411153.png)]](https://img-blog.csdnimg.cn/188c3772af3044ff94b7b08a2378c2a6.png)
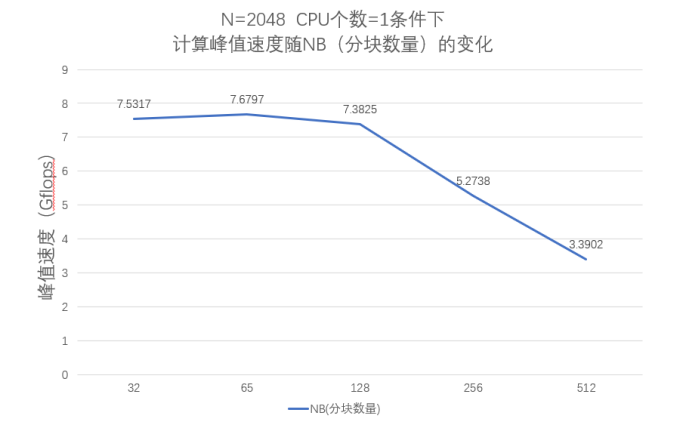
3.2 进行性能测试
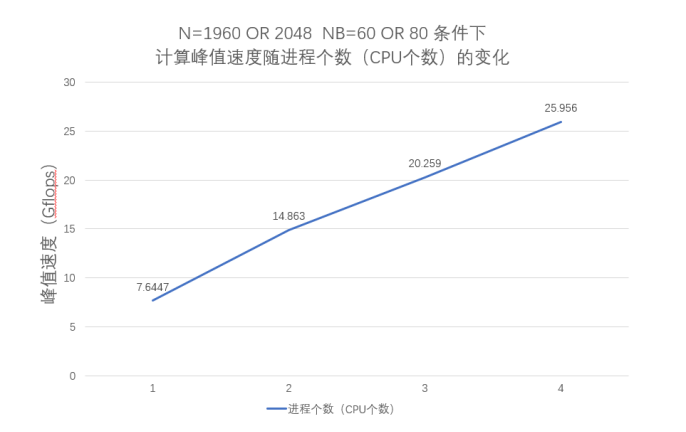

3.3 完成上述测试后比较和分析上面的测试结果,特别是如何能够得到高的性能测试值
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。