面试话术
-
-
- RabbitMq
- 授权话术
- Nginx
- Redis
- 工作流
- Spring
- SpringMvc
- Mybatis
-
- 1、介绍一下mybatis,说一下它的优点和缺点是什么?
- 2、**MyBatis与Hibernate有哪些不同**?
- 3、#{}和${}的区别是什么?
- 4、当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
- 5、通常一个Xml映射文件,都会写一个Dao接口与之对应,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
- 6、mybatis 如何执行批量插入?
- 7、mybatis 如何获取自动生成的(主)键值?
- 8、在mapper中如何传递多个参数?
- 9、Mybatis有哪些动态sql?
- 10、Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
- 11、Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
- 12、Mybatis的一级、二级缓存?
- 13、使用MyBatis的mapper接口调用时有哪些要求?
- 14、mybatis plus 了解过么?和mybatis有啥区别?
- 15、MyBatis框架及原理?
- 线程
- 锁
- Mysql
- linux
-
RabbitMq
1、介绍一下rabbitmq
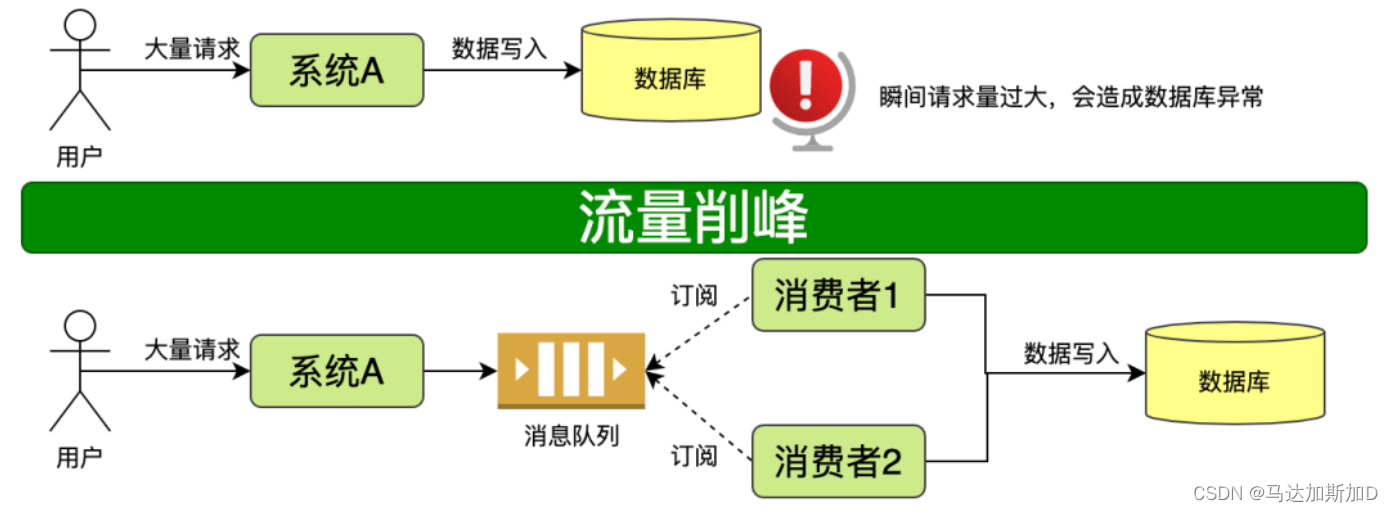
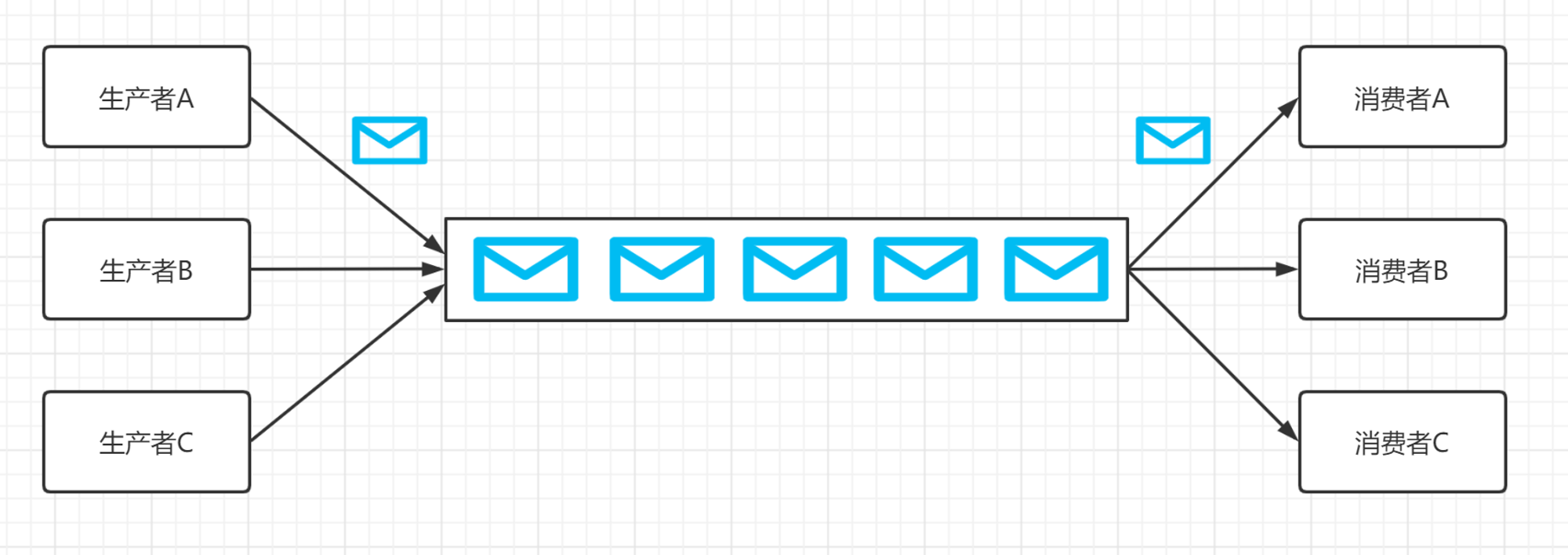
RabbitMQ是Erlang语言开发的基于AMQP的一款消息中间件,核心思想是生产者不会将消息直接发送给队列,消息在发送给客户端时先发送给交换机,然后由交换机转发给对应的队列。对路由(Routing),负载均衡(Load balance)、数据持久化都有很好的支持。
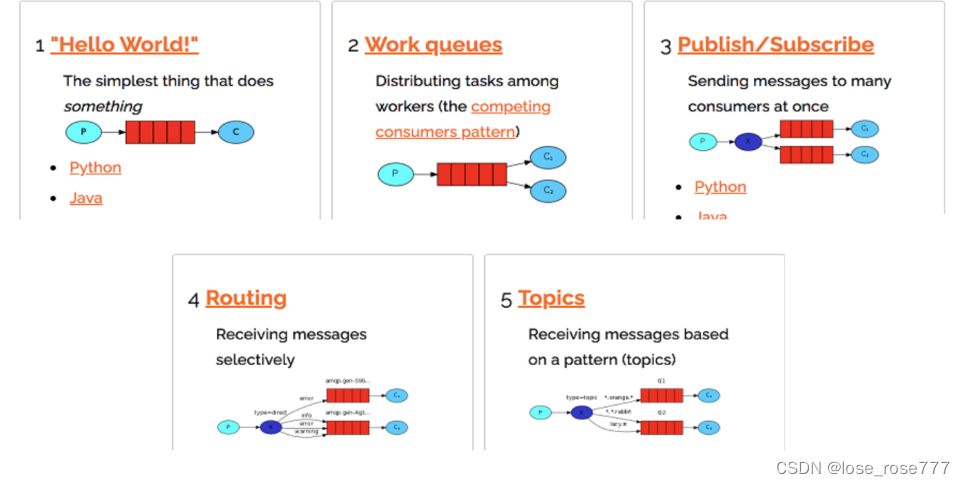
第一种是简单模型,一个生产者,一个队列,一个消费者,队列只能被一个消费者监听,所以生产者将消息发给队列之后,只能有一个消费者收到消息
第二种是工作模型,一个生产者,一个队列,多个消费者,队列可以被多个消费者监听,但是生产者将消息发给队列之后,还是只能有一个消费者接收到消息
后边三种都叫订阅模型,这三种里边引入了交换机的概念,具体的区分是根据交换机的类型区分的,在这三种模式种,生产者把消息发送给交换机,交换机不负责存储消息,由交换机发送给指定的队列,消费者监听队列消费消息。
首先是fanout类型,这种叫广播模式,生产者将消息发送给交换机,交换机会将消息转发给所有绑定到到当前交换机的队列中,对应监听队列的消费者都能收到消息,但是,如果没有队列绑定到这个交换机,消息会被mq丢弃。
接着是direct类型,这种叫定向模式,也叫路由模式,这种模式中,队列在绑定交换机的时候,同时指定了自己的routing key,可以理解为一个路由标示,生产者在发送消息给交换机的时候,同时指定要发送给的routing key,这时候,交换机就会根据这个routing key来定向的发送给对应的队列,对应监听该routing key的队列的消费者就能收到消息,但是如果交换机没有找到对应的routing key,消息会被丢弃。
最后是topic模式,这种叫通配符模式,队列在绑定交换机的时候,同时指定了自己的routing key,生产者在发送消息给交换机的时候,同时指定要发送给的routing key 的通配符,一般这个routing key是由多个单词用.的方式隔开的,通配符中,#号可以匹配一个或者多个单词,*号只能匹配一个单词,例如生产者指定的通配符为a.#,可以匹配到的routing key有:a.b、a.b.c等,如果是a.*的话,只能匹配a.b或者是a.c这样的routing key。每个队列绑定到交换机的时候可以定义多个routing key,交换机会跟据指定的通配符,发送到匹配通配符的routing key 对应的队列中,对应的消费者就可以收到消息了,但是,如果没有符合通配符的routing key ,消息会被丢弃
当然,在生产中使用的时候,为了避免mq宕掉等造成消息丢失的问题,我们都会配置持久化措施,在rabbitmq里,需要将交换机持和队列和消息持久化,这样消息就会被持久化到磁盘中,不会因为突发的断电等情况导致消息丢失
2、如何保证消息确定消息发送成功,并且被消费成功,有什么保障措施
首先,需要确保消息被发送成功,rabbitmq中提供了事物和confirm的机制,事物的话,就类似于数据库的事物,开启,执行,提交,如果过程中发生任何异常,就会触发回滚机制,我们可以在回滚中加入一些逻辑处理,重新发送或者日志记录,同时配置生产者确认的机制,就是在消息发送之后,该消息会被指定唯一的ID,如果有消息成功被交换机转发到队列之后,mq会给生产者发送ack确认,如果没有队列接收消息,那么会发送错误回执消息给生产者,生产者可以尝试重试发送,或者日志记录。通过这些可以看出,mq会增加一些保障性措施,必然会导致性能有一些下降,如果要保证消息的严格一致性,那么可以配置这些,如果消息不重要,或者允许有丢失的情况,那么可以不用配置,这样的话能提升mq的性能。
其次就是,消息确保发送成功之后,还要确保消息被消费成功,因为在消费者端,如果消息消费时发生异常,又没有做一些处理,那么消息就会丢失,这种情况,可以采取两种方式解决
第一种就是消费端配置手动ACK确认机制,消息被消费完成的时候,手动确认告诉mq消费成功,mq才会删除消息,如果消息被接收了,但是mq没有收到ack确认,那么消息在mq中会变为unacked状态,我们可以通过项目日志或者mq面板监控,当消费者断开连接之后,消息会重新回到队列中,消费者重新连接之后,会再次收到消息。
第二种就是可以结合数据库解决,生产者端发送成功之后,可以在数据库中存储发送的消息和发送时间,并标记状态为未消费状态,消费者端消费完成之后,标记mysql中数据的状态为已经消费。消费者端通过定时任务去数据库跑批检索超时未被消费的消息并重新发送,这种方式可以很好的解决消费失败的问题,但是增加了生产者和消费者之间的耦合度,以及会造成消息重复消费的问题,我们可以在保证消息发送成功的基础上,将上述逻辑放在消费者端,生产者正常发送消息,消费者在收到消息之后,存储到myqsl中,标记状态为未消费,同时ack通知mq确认,然后再消费消息,消息消费成功之后,改变mysql状态为已消费,消费端同时配置定时任务跑批检索数据库,定时重新执行超时未消费的消息。
以上的解决办法都是需要根据实际的业务需求来的,如果消息需要保证强一致性,不能出现任何差错,那么就需要按照前面说的添加对应的配置
我们项目中的mq主要用于数据同步使用的,mysql数据发生变化之后,需要同步到es索引库以及静态化页面中,这里我们配置了生产者确认模式,和消费者手动ack确认机制。
3、如何保证消息不被重复消费
我们可以在生产者端,发送消息时,数据的变动部分,进行md5加密处理,同时配置上一个唯一id,每次发送的数据的唯一id是递增的,相当于版本号的功能,在消费者端,收到消息之后,首先去数据库匹配一下md5值如果数据库中记录的当前记录已经被消费,那么就不进行消费,如果发现数据库没有记录当前消息,或者记录的状态没有被消费,那么才会重新消费该消息
4、RabbitMQ 宕机了怎么处理
RabbitMQ 提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重启 RabbitMQ,消息也不会丢失。持久化队列和非持久化队列的区别是,持久化队列会被保存在磁盘中,固定并持久的存储,当 Rabbit 服务重启后,该队列会保持原来的状态在RabbitMQ 中被管理,而非持久化队列不会被保存在磁盘中,Rabbit 服务重启后队列就会消失。非持久化比持久化的优势就是,由于非持久化不需要保存在磁盘中,所以使用速度就比持久化队列快。即是非持久化的性能要高于持久化。而持久化的优点就是消息会一直存在,不会随服务的重启或服务器的宕机而消失。使用的时候需要根据实际需求来判断具体如何使用。
授权话术
1、你给我说一下授权认证(登陆注册)的逻辑
这块来说就比较简单了,我们提供的注册功能有用户名密码注册,手机号注册,微信登陆绑定注册功能
-
我们系统规定的是用户名不得重复,注册的时候,会去做一下重复校验,向后台提交注册信息的时候,密码都会经过md5加密传输,到后台会首先用加密工具生成32位的盐值,然后把用户名通过md5加密之后,用户名的md5和密码的md5和盐值结合之后,生成md5值,然后一起存入数据库,用户登录的时候,按照首先根据用户名去数据库查找用户,找出来用户之后,根据相同的逻辑计算加密之后的密码和数据库的密码对比,对比一致则登陆成功
-
这里用到了阿里的短信服务功能,注册的时候,手机号码校验通过之后,向用户手机发送验证码,后台将验证码和手机号对应关系存入redis,用户提交注册之后,验证码跟redis中对比即可
-
这里结合微信登陆使用的,微信登陆之后,如果发现对应openid没有绑定系统用户,需要提示用户去绑定,然后才能注册
微信开放平台注册开发者帐号,并拥有一个已审核通过的网站应用,并获得相应的AppID和AppSecret。申请微信登录且通过审核后,可开始接入流程。就是你的网站要想实现微信扫码登陆功能首先要在微信备案通过,它才会给你个AppID和AppSecret。
2、网站带上AppID和回调域名参数请求微信OAuth2.0授权登陆。
6、java后端获取到code后,在带上带上AppID和AppSecret和code再去调微信接口获取access_token。
7、获取access_token后就可以解析用户的一些基本信息,比如:微信用户头像、用户名、性别、城市等一些基本参数。
- 微信app登陆
因为是app登陆,需要用到微信开放平台的接入功能,微信登陆采用的auth2.0的验证机制,在开放平台里注册了账号并通过企业认证,获取了AppID 和 AppSecret之后,第一步我们的服务器先获取code,传给移动端,移动端跟微信交互,用户确认授权之后,然后移动端请求我们后台获取用户信息,我们后台会先去用code获取access_token,然后在通过access_token获取用户信息,同时会返回用户的openId,我们会根据这个openId去我们的数据库查,是否已经获取过用户信息,如果获取过用户信息,看一下最后获取时间,因为每3天更新一次,所以这里会看一下是否需要重新获取如果没有获取过用户信息,会通过access_token获取用户信息,提示绑定系统用户,access_token失效时间为2个小时,因为微信有接口请求次数限制,2小时之内不会再去请求微信的access_token
因为我们系统是微服务架构,所以这里使用jwt实现了单点登录,因为平台有很多,有web端、管理端,还有一个清结算平台,实现单点登录会更方便用户使用,登录之后,给用户颁发了一个token令牌,每次请求的时候,都会在请求头里携带这个token,经过我们的网关的时候,会对这个token做一个权限认证,认证通过,然后才能请求到我们的微服务具体的接口
2、说一下jwt
微服务集群中的每个服务,对外提供的都是Rest风格的接口。而Rest风格的一个最重要的规范就是:服务的无状态性,即:
我们项目中也是采用的无状态登陆,使用token作为身份认证的令牌,这个token就是使用jwt生成的,jwt类型的token分为三部分,头部,载荷,签名,头部存储一些识别信息,载荷存储一些用户的基本字段,我们存储的是id的username,签名是通过头部和载荷外加RAS非对称加密生成的
3、说一下auth2.0机制
其实就是一种授权机制。数据的所有者告诉系统,同意授权第三方应用进入系统,获取这些数据。系统从而产生一个短期的进入令牌(token),用来代替密码,供第三方应用使用。
令牌(token)与密码(password)的作用是一样的,都可以进入系统,但是还是有一些差异的。
(1)令牌是短期的,到期会自动失效,用户自己无法修改。密码一般长期有效,用户不修改,就不会发生变化。
(2)令牌可以被数据所有者撤销,会立即失效。以上例而言,屋主可以随时取消快递员的令牌。密码一般不允许被他人撤销。
(3)令牌有权限范围(scope),比如只能进小区的二号门。对于网络服务来说,只读令牌就比读写令牌更安全。密码一般是完整权限。
有了这些设计,保证了令牌既可以让第三方应用获得权限,同时又随时可控,不会危及系统安全。这就是 OAuth 2.0 的优点。
注意,只要知道了令牌,就能进入系统。系统一般不会再次确认身份,所以令牌必须保密,泄漏令牌与泄漏密码的后果是一样的。这也是为什么令牌的有效期,一般都设置得很短的原因。
具体来说,auth2.0一共分成四种授权类型
第一种是授权码模式,这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用。授权码通过前端传送,令牌则是储存在后端,而且所有与资源服务器的通信都在后端完成。这样的前后端分离,可以避免令牌泄漏。比如A应用想要获取B应用的用户数据,A会首先访问B的授权页面,用户点击确认授权之后,B会请求A配置的回调地址,同时附带上授权码code,A可以通过这个code向B申请登录令牌access_token,获取到登录令牌之后,然后就可以向B应用请求用户信息数据了。最常见的就是微信登陆等第三方登录都用的这种方式。
还有就是隐藏式、密码式、客户端凭证等三种模式,我这边就是大概了解了一下,实际没有使用过。
Nginx
1、介绍一下nginx
Nginx 是一个高性能的 HTTP 和反向代理服务器,具有反向代理和负载均衡以及动静分离等功能
反向代理是指以代理服务器来接受用户的请求,然后将请求,分发给内部网络上的服务器,并将从服务器上得到的结果返回给用户,此时代理服务器对外就表现为一个反向代理服务器。 反向代理总结就一句话就是:代理端代理的是服务端。
反向代理的话,只需要配置对应的server模块就行了,里面配置上server_name和对应监听的端口,然后在配置location路径转发规则就行,当然也可以配置代理静态资源
再来说说负载均衡吧,负载均衡即是代理服务器将接收的请求均衡的分发到各服务器中,负载均衡主要解决网络拥塞问题,提高服务器响应速度,服务就近提供,达到更好的访问质量,减少后台服务器大并发压力,同时还可以保证服务端的高可用。常用的nginx的负载均衡策略有轮训、权重、iphash、最少连接数,默认的策略就是轮训
负载均衡这里需要配置upstream模块,在upstream中配置好当前的负载均衡规则,然后配置好每个server对应的ip端口即可,在server模块配置的转发规则就时向这个upstream上转发就行了
2、nginx如何处理http请求
Nginx这块的处理时结合多进程机制和异步机制 ,异步机制使用的是异步非阻塞方式
首先呢是多进程机制
服务器每当收到一个客户端请求时,就有服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
使用进程的好处是各个进程之间相互独立,不需要加锁,减少了使用锁对性能造成影响,同时降低编程的复杂度,降低开发成本。接着呢就是采用独立的进程,可以让进程互相之间不会影响 ,如果一个进程发生异常退出时,其它进程正常工作, master 进程则很快启动新的 worker 进程,确保服务不会中断,从而将风险降到最低。缺点是操作系统生成一个子进程需要进行 内存复制等操作,在资源和时间上会产生一定的开销。当有大量请求时,会导致系统性能下降
还有就是异步非阻塞机制
每个工作进程 使用 异步非阻塞方式 ,可以处理多个客户端请求 。
当某个工作进程接收到客户端的请求以后,调用 IO 进行处理,如果不能立即得到结果,就去 处理其他请求 (这就是非阻塞 );而 客户端 在此期间也 无需等待响应 ,可以去处理其他事情(这就是异步 )。
当 IO 返回时,就会通知此工作进程 ;该进程得到通知,暂时挂起 当前处理的事务去响应客户端请求 。
3、nginx常用命令
4、什么是动静分离,为什么要动静分离
这个我理解的来说就是把前端静态资源和后台请求分离开,主要就是为了提升静态资源的访问速度,一般前后端分离的项目用的居多,分离之后,我们可以把静态资源放入cdn中去,可以实现用户的就近访问,同时还提供了更大的带宽。
5、如何保证nginx高可用
因为nginx是我们所有项目的入口,必须要保证nginx的高可用,这里一般都用的nginx集群,并同时加入了keepalive来做的双机热备处理,通过请求一个vip(virtual ip:虚拟ip)来达到请求真实IP地址的功能,而VIP能够在一台机器发生故障时候,自动漂移到另外一台机器上,从来达到了高可用的功能
6、nginx如何配置负载均衡
Redis
1、介绍一下redis
Redis是一个非关系数据库,我们项目中主要用它来存储热点数据的,减轻数据库的压力,单线程纯内存操作,采用了非阻塞IO多路复用机制,就是单线程监听,我们项目中使用springdata–redis来操作redis
我们项目中使用redis的地方很多,比方说首页的热点数据,数据字典里的数据等都用热地说存储来提高访问速度
redis呢有5种数据类型,string、list、hash、set、zset,我们常用的有string、list和hash,一些简单的key-value类型的都存储在string类型中,比如一些系统开关之类的,是否开放注册等,还有一些存储在hash中,比如我们的首页的推荐数据和热门数据,都是用hash来存储的,一个固定的字符串作为key,每条数据的id作为field,对应的数据作为value存储
redis还有两种持久化方式,一个是RDB,这也是redis默认的持久化方式,这种方式是以快照的方式存储数据,在固定的时间段内如果有多少变化,那么就会生成快照存储到磁盘上,redis 在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。对于 RDB 方式,redis 会单独创建一个子进程来进行持久化,而主进程是不会进行任何 IO 操作的,这样就确保了 redis 极高的性能。 这种方式的优点呢就是快,但是如果没等到持久化开始redis宕机了,那么就会造成数据丢失
还有一种是AOF,是即时性的持久化方式,是将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。AOF的方式会导致性能下降
两种方式可以同时开启,当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
我们项目中使用的持久化方式就是默认的RDB,因为我们存储的数据首先来说不是很重要的数据,如果丢失了,还可以从数据库加载到,主要用的就是性能这块
2、redis缓存雪崩和缓存穿透、缓存预热、缓存降级
我们可以简单的理解为:由于原有缓存失效,新缓存还没有存入到redis的期间
比方说:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期,所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法:
加最多的解决方案就是锁,或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就是缓存失效时间分散开,不设置固定的实效时间,采用随机失效的策略来解决
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空,这就相当于进行了两次无用的查询。像这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空,不管是数据不存在,还是系统故障,我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
- 缓存预热:
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
操作方式:
然后就是缓存更新:
2.、当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存
- 缓存降级:
当访问量剧增、服务出现问题,比如响应时间慢或不响应,或者非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有问题的服务。redis可以帮助系统实现数据降级载体,系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。
3、redis分布式锁
这个分布式锁这里,我们原来传统的项目都在单台服务器上部署用java里的锁synchronized这个同步锁就行,但是他这个是针对对象的锁,但是我们分布式的项目需要把项目部署到多台服务器上,每台服务器的对象都不同,所以就得考虑用分布式锁,这块实现起来也比较简单,其实这个锁就是redis中的一个key-value的一对值,在使用的时候吧,首先使用setnx方法进行尝试加锁,并可以设置过期时间,如果返回1则代表加锁成功,然后立即对这个锁设置一个实效时间,防止服务宕机,锁一致存在,在处理完业务逻辑之后,删除锁就行了,其他线程就可以获取锁进行业务了
4、redis主从复制
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步,配置非常简单,只需要在从节点配置slave of主节点的ip即可,如果有密码,还需要配置上密码,从节点只能读数据,不能写数据
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
还有就是增量同步,主要发生在redis的工作过程中,Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
5、redis集群
Redis本身就支持集群操作redis_cluster,集群至少需要3主3从,且每个实例使用不同的配置文件,主从不用配置,集群会自己选举主数据库和从数据库,为了保证选举过程最后能选出leader,就一定不能出现两台机器得票相同的僵局,所以一般的,要求集群的server数量一定要是奇数,也就是2n+1台,并且,如果集群出现问题,其中存活的机器必须大于n+1台,否则leader无法获得多数server的支持,系统就自动挂掉。所以一般是3个或者3个以上的奇数节点。
Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。哨兵的作用就是监控redis主、从数据库是否正常运行,主数据库出现故障自动将从数据库转换为主数据库
我们公司搭建的redis集群是用的ruby脚本配合搭建的,我们一共搭建了6台服务器,3主3备,他们之间通信的原理是有一个乒乓协议进行通信的,我再给你说下一他们往里存储数据的机制吧,其实这个redis搭建好集群以后每个节点都存放着一个hash槽,每次往里存储数据的时候,redis都会根据存储进来的key值算出一个hash值,通过这个hash值可以判断到底应该存储到哪一个哈希槽中,取的时候也是这么取的,这就是我了解的redis集群
6、除了redis,还了解哪些别的非关系型数据库
有memacache,MongoDB这些,以及redis这几个都是非关系型数据库
memacache是纯内存型的,只支持简单的字符串数据,并且value值最大只能是1MB,而且所有的数据都只能存储在内存中,如果服务宕机或者关机重启,数据就会丢失,没有持久化功能
MongoDB的话是存储的数据都在磁盘上,功能比较多,不过性能没有其他两种好
而redis呢,支持的数据类型比较多,而且速度也非常快,value最大可以支持到512MB,而且既可以把数据存储在内存里,也可以持久化到磁盘上,重启之后还可以把磁盘中的数据重新加载到内存里,从性能以及数据安全上来说,都比memacache和MongoDB好一些
7、redis数据同步
这一块主要是跟mysql数据同步吧,mysql数据可能会发生变动,那么redis就要跟数据库的数据保持一致我们实际去使用的时候,是在数据发生变动的地方,比如增删改的时候,新奇一个线程,然后将变动的数据更新到redis中,根据不同的场景需求,也可以在数据变动时,把redis里的数据删掉,下一次用户查询的时候,发现redis中没有数据,就会重新去数据库加载一遍,这样也可以实现同步的效果
8、介绍一下redis的pipeline
我们都知道redis是单线程的,在执行命令的时候,其他客户端是阻塞状态的,如果在高并发的时候,其实是会影响一定效率的,所以redis提供了pipeline,可以让我们批量执行命令,大大的减少了IO阻塞以及访问效率
因为pipeline是批量执行命令,我们一般会结合redis的事物去使用,它也符合事务的ACID特性,MULTI开启事物,EXEC执行,DISCARD清除事物状态,回到非事物状态,在使用前,还可以结合WATCH监控来使用,如果我们在执行一组命令的过程中,不想让其中的某个值被其他客户端改动,就可以使用WATCH,使用了之后,如果被改动,事务会自动回滚,可以很好的保证我们批量执行命令的时候,数据的准确性,在使用完成之后,可以使用UNWATCH解除监控。
9、介绍下redis中key的过期策略
定时删除:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
惰性删除:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null
定期删除:每隔一段时间执行一次删除过期key操作
所谓定期删除,指的是 redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
工作流
1、工作流话术
工作流这块儿。嗯,实际在工作中使用的时候,activiti用的居多,当然还有一些其他的工作流引擎,嗯,在网上看了也大概看了一下,其他的像JBPM以及workflow等用的情况来讲不是很多,所以说activity目前来讲用的比较多的,它最新的版本是5.0,那他在用的时候在数据库里边儿需要,嗯,有23张表,然后在23张表里边儿会记录着所有的这些工作都是相关流程相关所有的数据。
在用的时候呢,首先就是要配置它的23张表,在数据库先创建了一下这些表。然后呢,去加载activity的配置文件。这里加载那会有两种方式,嗯,我在写这个demo的时候,而写的是用spring去加载他的一个xml配置文件,这配置文件里边儿,他就跟spring去整合其他的一些框架的时候是一样的,这个xml里边儿配置了一些这个它的的一个核心的引擎的管理器ProcessEngineConfiguration,还有一些它的数据库连接啊等等。然后给他放到了spring的配置文件中。
然后就是需要去定义一个流程。这里呢,我使用的是一个eclipse的插件,通过画流程图的方式去定义了一个简单的理由请假的流程。然后生成了一个zip的压缩包。
接下来呢,需要把这个流程部署到Activity中。通过processEngine获取到Deployment部署的类,定义一个流程名称,然后将这个压缩包,部署到activity中。这时会返回一个流程id
然后需要去启动流程实例。流程部署好了呢,如果说实际有人去发起一个请假流程,这时候需要去启动一个新的流程实例,每个流程实例会有一个独立的id。这个流程上还可以设计一些流程变量。可以是全局的,也可以是局部的。这些变量会在整个流程当中。根据它的性质去向下传递。它后台会有一个taskservice会去数据库检索待处理的任务。然后去处理就就行。处理完成之后,嗯,后边儿这个流程示例会继续向下一个节点去进行。下一个节点收到任务之后,同样通过taskservice去处理。最终直到这个任务被执行完。
总结来看呢,这个activity通过代码的方式简化了实际工作当中一些流程性的问题。当然它这里边儿还会有一些复杂的流程。包括,如何去呃多人同时处理任务呀,以及一些复杂的节点等等,大致这就是我了解的activity工作流。
Spring
1、介绍一下spring
关于Spring的话,我们平时做项目一直都在用,不管是使用ssh还是使用ssm,都可以整合。Spring里面主要的就三点,也就是核心思想,IOC控制反转,DI依赖注入,AOP切面编程
我先来说说IOC吧,IOC就是spring里的控制反转,把类的控制权呢交给spring来管理,我们在使用的时候,在spring的配置文件中,配置好bean标签,以及类的全路径,如果有参数,然后在配置上相应的参数。这样的话,spring就会给我们通过反射的机制实例化这个类,同时放到spring容器当中去。
我们在使用的时候,需要结合DI依赖注入使用,把我们想使用的类注入到需要的地方就可以,依赖注入的方式有构造器注入、getset注入还有注解注入。我们现在都使用@autowired或者@Resource注解的方式注入。
然后就是AOP切面编程,他可以在不改变源代码的情况下对代码功能的一个增强。我们在配置文件中配置好切点,然后去实现切面的逻辑就可以实现代码增强,这个代码增强,包括在切点的执行前,执行中,执行后都可以进行增强逻辑处理,不用改变源代码,这块我们项目中一般用于权限认证、日志、事务处理这几个地方。
2、AOP的实现原理
这块呢,我看过spring的源码,底层就是动态代理来实现的,所谓的动态代理就是说 AOP 框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个 AOP 对象,这个 AOP 对象包含了 ,目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP 中的动态代理主要有两种方式,JDK 动态代理和 CGLIB 动态代理:
-
JDK 动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler 接口和 Proxy 类,InvocationHandler 通过 invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy 利用InvocationHandler 动态创建一个符合接口的的实例,生成目标类的代理对象。
-
如果代理类没有实现 InvocationHandler 接口,那么 Spring AOP 会选择使用 CGLIB 来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现 AOP。CGLIB 是通过继承的方式做的动态代理,因此如果某个类被标记为 final,那么它是无法使用 CGLIB 做动态代理的。不过在我们的业务场景中没有代理过final的类,基本上都代理的controller层实现权限以及日志,还有就是service层实现事务统一管理
3、详细介绍下IOC容器
Spring 提供了两种 IoC 容器,分别为 BeanFactory 和 ApplicationContext
BeanFactory 是基础类型的 IoC 容器,提供了完整的 IoC 服务支持。简单来说,BeanFactory 就是一个管理 Bean 的工厂,它主要负责初始化各种 Bean,并调用它们的生命周期方法。
ApplicationContext 是 BeanFactory 的子接口,也被称为应用上下文。它不仅提供了 BeanFactory 的所有功能,还添加了对 i18n(国际化)、资源访问、事件传播等方面的良好支持。
他俩的主要区别在于,如果 Bean 的某一个属性没有注入,则使用 BeanFacotry 加载后,在第一次调用 getBean() 方法时会抛出异常,但是呢ApplicationContext 会在初始化时自检,这样有利于检查所依赖的属性是否注入。
因此,在实际开发中,通常都选择使用 ApplicationContext
4、@Autowired 和 @Resource的区别
@Autowired 默认是按照类型注入的,如果这个类型没找到,会根据名称去注入,如果在用的时候需要指定名称,可以加注解@Qualifier("指定名称的类")
@Resource注解也可以从容器中注入bean,默认是按照名称注入的,如果这个名称的没找到,就会按照类型去找,也可以在注解里直接指定名称@Resource(name="类的名称")
5、springbean的生命周期
spring容器可以管理 singleton 作用域 Bean 的生命周期,在此作用域下,Spring 能够精确地知道该 Bean 何时被创建,何时初始化完成,以及何时被销毁。
而对于 prototype 作用域的 Bean,Spring 只负责创建,当容器创建了 Bean 的实例后,Bean 的实例就交给客户端代码管理,Spring 容器将不再跟踪其生命周期。每次客户端请求 prototype 作用域的 Bean 时,Spring 容器都会创建一个新的实例,并且不会管那些被配置成 prototype 作用域的 Bean 的生命周期。
整体来说就4个步骤:实例化bean,属性赋值,初始化bean,销毁bean
6、springbean的作用域
(1)singleton:单例模式,使用 singleton 定义的 Bean 在 Spring 容器中只有一个实例,这也是 Bean 默认的作用域。 controller、service、dao层基本都是singleton的
(2)prototype:原型模式,每次通过 Spring 容器获取 prototype 定义的 Bean 时,容器都将创建一个新的 Bean 实例。
(3)request:在一次 HTTP 请求中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Request 内有效。
(4)session:在一次 HTTP Session 中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Session 内有效。
(5)global–session:全局作用域,在一个全局的 HTTP Session 中,容器会返回该 Bean 的同一个实例。
7、事务的传播特性
解读:事务的传播特性发生在事务方法与非事物方法之间相互调用的时候,在事务管理过程中,传播行为可以控制是否需要创建事务以及如何创建事务
| 属性名称 | 值 | 描 述 |
|---|---|---|
| PROPAGATION_REQUIRED | required | 支持当前事务。如果 A 方法已经在事务中,则 B 事务将直接使用。否则将创建新事务,默认就是这个 |
| PROPAGATION_SUPPORTS | supports | 支持当前事务。如果 A 方法已经在事务中,则 B 事务将直接使用。否则将以非事务状态执行 |
| PROPAGATION_MANDATORY | mandatory | 支持当前事务。如果 A 方法没有事务,则抛出异常 |
| PROPAGATION_REQUIRES_NEW | requires_new | 将创建新的事务,如果 A 方法已经在事务中,则将 A 事务挂起 |
| PROPAGATION_NOT_SUPPORTED | not_supported | 不支持当前事务,总是以非事务状态执行。如果 A 方法已经在事务中,则将其挂起 |
| PROPAGATION_NEVER | never | 不支持当前事务,如果 A 方法在事务中,则抛出异常 |
| PROPAGATION.NESTED | nested | 嵌套事务,底层将使用 Savepoint 形成嵌套事务 |
8、事务的隔离级别
Spring 事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。真正的数据库层的事务提交和回滚是通过 binlog实现的。隔离级别有四种
-
Read uncommitted (读未提交):读未提交,允许另外一个事务可以看到这个事务未提交的数据,最低级别,任何情况都无法保证。
-
Read committed (读已提交):保证一个事务修改的数据提交后才能被另一事务读取,而且能看到该事务对已有记录的更新,可避免脏读的发生。
-
Repeatable read (可重复读):保证一个事务修改的数据提交后才能被另一事务读取,但是不能看到该事务对已有记录的更新,可避免脏读、不可重复读的发生。
-
Serializable (串行化):一个事务在执行的过程中完全看不到其他事务对数据库所做的更新,可避免脏读、不可重复读、幻读的发生。
9、spring中都用了哪些设计模式
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
(4)模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现–ApplicationListener。
10、spring中如何处理bean在线程并发时线程安全问题
在一般情况下,只有无状态的 Bean 才可以在多线程环境下共享,在 Spring 中,绝大部分 Bean 都可以声明为 singleton 作用域,因为 Spring 对一些 Bean 中非线程安全状态采用 ThreadLocal 进行处理,解决线程安全问题。
ThreadLocal 和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而 ThreadLocal 采用了“空间换时间”的方式。
ThreadLocal 会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal 提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进 ThreadLocal。
我们项目中的拦截器里就有这样的逻辑,在我们微服务中,网关进行登录以及鉴权操作,具体的微服务中需要用到token去解析用户信息,我们就在拦截器的preHandler里定义了threadlocal,通过token解析出user的信息,后续controller以及service使用的时候,直接从threadlocal中取出用户信息的,在拦截器的afterCompletion方法中清理threadlocal中的变量,避免变量堆积消耗内存
SpringMvc
1、介绍一下springMVC
springmvc是一个视图层框架,通过MVC模型让我们很方便的接收和处理请求和响应。我给你说说他里边的几个核心组件吧
它的核心控制器是DispatcherServlet,他的作用是接收用户请求,然后给用户反馈结果。它的作用相当于一个转发器或中央处理器,控制整个流程的执行,对各个组件进行统一调度,以降低组件之间的耦合性,有利于组件之间的拓展
接着就是处理器映射器(HandlerMapping):他的作用是根据请求的URL路径,通过注解或者XML配置,寻找匹配的处理器信息
还有就是处理器适配器(HandlerAdapter):他的作用是根据映射器处理器找到的处理器信息,按照特定执行链路规则执行相关的处理器,返回ModelAndView
最后是视图解析器(ViewResolver):他就是进行解析操作,通过ModelAndView对象中的View信息将逻辑视图名解析成真正的视图View返回给用户
接下来我给你说下springmvc的执行流程吧
2、springMVC的执行流程
(1)用户发送请求至前端控制器 DispatcherServlet;
(2) DispatcherServlet 收到请求后,调用 HandlerMapping 处理器映射器,请求获取 Handle;
(3)处理器映射器根据请求 url 找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给 DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter 处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
(6)Handler 执行完成返回 ModelAndView;
(7) HandlerAdapter 将 Handler 执 行 结 果 ModelAndView 返 回 给DispatcherServlet;
(8)DispatcherServlet 将 ModelAndView 传给 ViewResolver 视图解析器进行解析;
(10)DispatcherServlet 对 View 进行渲染视图(即将模型数据填充至视图中)
3、springMVC接收前台参数的几种方式
4、springMVC中的常用注解
@RequestMapping:指定类或者方法的请求路径,可以使用method字段指定请求方式
@GetMapping、@PostMapping:规定了请求方式的方法的请求路径
@RequestBody:用于接收js对象的,将js对象转换为Java对象
@RestController:用在类上,等于@Controller+@ResourceBody两个注解的和,一般在前后端分离的项目中只写接口时经常使用,标明整个类都返回json格式的数据
等等
5、spring如何整合springMVC
简单的说 springMVC在ssm中整合 就是 在 web.xml 里边配置springMVC的核心控制器:DispatcherServlet; 它就是对指定后缀进行拦截;然后在springMVC.xml里边配置扫描器,可以扫描到带@controller注解的这些类,现在用springMVC都是基与注解式开发, 像@service,@Repository @Requestmapping,@responsebody 啦这些注解标签 等等 都是开发时用的,每个注解标签都有自己的作用;它还配置一个视图解析器,主要就是对处理之后的跳转进行统一配置,有页面的路径前缀和文件后缀 ,如果有上传相关的设置,还需要配置上multpart的一些配置,比如单个文件最大的大小,以及最大请求的大小,大致就是这些
Mybatis
1、介绍一下mybatis,说一下它的优点和缺点是什么?
Mybatis是一个半ORM(对象关系映射)的持久层框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程,使用时直接编写原生态sql。
优点:
1:基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML 里,解除sql与程序代码的耦合,便于统一管理,提供XML标签,支持编写动态SQL语句,并可重用;
2:很好的与各种数据库兼容;
3:提供映射标签,支持对象与数据库的ORM字段关系映射,提供对象关系映射标签,支持对象关系组件维护。
4:与JDBC相比,消除了JDBC大量冗余的代码,不需要手动开关连接,能够与Spring很好的集成
缺点:
1:SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求;
2:SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库;
2、MyBatis与Hibernate有哪些不同?
首先Hibernate是一个完全面向对象的持久层框架,mybatis是一个半自动化的持久层框架。
开发方面: hibernate开发中,sql语句已经被封装,直接可以使用,加快系统开发, Mybatis 属于半自动化,sql需要手工完成,稍微繁琐,但是如果对于庞大复杂的系统项目来说,复杂的sql语句较多,选择hibernate 就不是一个好方案。
sql优化方面:Hibernate 自动生成sql,有些语句较为繁琐,会多消耗一些性能, Mybatis 手动编写sql,可以避免不需要的查询,提高系统性能;
对象管理方面:Hibernate 是完整的对象-关系映射的框架,开发工程中,无需过多关注底层实现,只要去管理对象即可;Mybatis 需要自行管理 映射关系。
缓存方面:Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存,MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。
总之:Mybatis 小巧、方便、高效、简单、直接、半自动化;Hibernate 强大、方便、高效、复杂、间接、全自动化
3、#{}和${}的区别是什么?
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
4、当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
第一种方法:通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致;
第二种方法:通过<resultMap>来映射字段名和实体类属性名的一一对应的关系;
5、通常一个Xml映射文件,都会写一个Dao接口与之对应,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口即Mapper接口。接口的全限名,就是映射文件中的namespace的值;接口的方法名,就是映射文件中Mapper的Statement的id值;接口方法内的参数,就是传递给sql的参数。
Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MapperStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MapperStatement对象。
Mapper接口里的方法,是不能重载的,因为是使用 全限名+方法名 的保存和寻找策略。Mapper 接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象proxy,代理对象会拦截接口方法,转而执行MapperStatement所代表的sql,然后将sql执行结果返回。
6、mybatis 如何执行批量插入?
有两种方式,第一种就是普通的xml中insert语句可以写成单条插入,在调用方循环N次;第二种是xml中insert语句写成一次性插入一个N条的list,举例下面的list标签
<insert id="insertBatch" >
insert into person ( <include refid="Base_Column_List" /> )
values
<foreach collection="list" item="item" index="index" separator=",">
(null,#{item.name},#{item.sex},#{item.address})
</foreach>
</insert>
7、mybatis 如何获取自动生成的(主)键值?
insert 方法总是返回一个int值 ,这个值代表的是插入的行数,不是插入返回的主键id值;如果采用自增长策略,自动生成的键值在 insert 方法执行完后可以被设置到传入的参数对象中,需要增加两个属性,usegeneratedkeys=”true” keyproperty=”id”
<insert id=”insertname” usegeneratedkeys=”true” keyproperty=”id”>
insert into names (name) values (#{name})
</insert>
8、在mapper中如何传递多个参数?
(1)第一种:
//DAO层的函数
Public UserselectUser(String name,String area);
//对应的xml,#{0}代表接收的是dao层中的第一个参数,#{1}代表dao层中第二参数,更多参数一致往后加即可。
<select id="selectUser"resultMap="BaseResultMap">
select * fromuser_user_t whereuser_name = #{0} anduser_area=#{1}
</select>
(2)第二种: 使用 @param 注解:
public interface usermapper {
user selectuser(@param(“username”) string username,@param(“hashedpassword”) string hashedpassword);
}
然后,就可以在xml像下面这样使用(推荐封装为一个map,作为单个参数传递给mapper):
<select id=”selectuser” resulttype=”user”>
select id, username, hashedpassword
from some_table
where username = #{username}
and hashedpassword = #{hashedpassword}
9、Mybatis有哪些动态sql?
Mybatis动态sql可以在Xml映射文件内,以标签的形式编写动态sql,执行原理是根据表达式的值 完成逻辑判断并动态拼接sql的功能。Mybatis提供了9种动态sql标签:trim | where | set | foreach | if | choose | when | otherwise | bind
10、Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态sql的9个标签,其中<sql>为sql片段标签,通过<include>标签引入sql片段,<selectKey>为不支持自增的主键生成策略标签。
11、Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;
原因就是namespace+id是作为Map<String, MapperStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
但是,在以前的Mybatis版本的namespace是可选的,不过新版本的namespace已经是必须的了。
12、Mybatis的一级、二级缓存?
一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置<cache/>
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear 掉并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新。
13、使用MyBatis的mapper接口调用时有哪些要求?
1:Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
2:Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
3:Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
4:Mapper.xml文件中的namespace即是mapper接口的类路径。
14、mybatis plus 了解过么?和mybatis有啥区别?
Mybatis-Plus是一个Mybatis的增强工具,它在Mybatis的基础上只做增强,却不做改变。我们在使用Mybatis-Plus之后既可以使用Mybatis-Plus的特有功能,又能够正常使用Mybatis的原生功能。Mybatis-Plus(简称MP)是为简化开发、提高开发效率而生,自带通用mapper的单表操作。
15、MyBatis框架及原理?
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架,其主要就完成2件事情:
MyBatis的主要设计目的就是让我们对执行SQL语句时对输入输出的数据管理更加方便,所以方便地写出SQL和方便地获取SQL的执行结果才是MyBatis的核心竞争力;
他的执行流程包括
1.读取配置文件,配置文件包含数据库连接信息和Mapper映射文件或者Mapper包路径。
2.有了这些信息就能创建SqlSessionFactory,SqlSessionFactory的生命周期是程序级,程序运行的时候建立起来,程序结束的时候消亡
3.SqlSessionFactory建立SqlSession,目的执行sql语句,SqlSession是过程级,一个方法中建立,方法结束应该关闭
4.当用户使用mapper.xml文件中配置的的方法时,mybatis首先会解析sql动态标签为对应数据库sql语句的形式,并将其封装进MapperStatement对象,然后通过executor将sql注入数据库执行,并返回结果。
线程
1、创建线程的方式
首先呢,Thread 类本质上是实现了 Runnable 接口,代表一个线程的实例。所以我们可以编写一个类,继承Thread类,或者直接实现Runnable接口,然后再重写下run方法就行了。启动线程的方式就是调用类里边的 start方法。start()方法是一个 native 方法,它的作用就是启动线程,线程会去执行 run()方法中的代码。
还有就是实现 Callable 接口,这个接口相当于是Runnable接口的增强版,他的执行代码的方法不是run方法了,是call方法,这个call方法可以有返回值,我们可以创建一个 FutureTask 类的实例对象,通过他的get()方法得到执行结果,不过这里定的执行结果需要跟FutureTask的泛型一致才行,并且call方法还可以抛出异常,通过这些,我们就能很明确的知道线程内部的执行状态
还有就是通过线程池来实现,线程池就是事先将多个线程对象放到一个容器中,当使用的时候就不用 new 线程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高的代码执行效率。 一般创建线程池的话,都是使用个的Executors 类中提供的创建线程池的静态方法。他可以创建4种线程池,有
FixedThreadPool,创建固定大小的线程池,比如线程池容量是10,最多可以同时执行10个线程。
CachedThreadPool,创建一个可缓存的线程池,此线程池不会对线程池大小做限制,线程池大小完全依赖于JVM能够创建的最大线程大小,当然线程池里的线程是可以复用的,但是如果在高并发的情况下,这个线程池在会导致运行时内存溢出问题
ScheduledThreadPool,创建一个定时执行的线程池,里边提供了两个方法,FixRate和fixDelay,fixRate就是以固定时间周期执行任务,不管上一个线程是否执行完,fixDelay的话就是以固定的延迟执行任务,就是在上一个任务执行完成之后,延迟一定时间执行。
SingleThreadExecutor,创建一个单线程的线程池,这个线程池同时只能执行一个线程,可以保证线程按顺序执行,保证数据安全。
2、线程都有哪些方法
wait方法呢就是线程等待,调用这个方法之后,线程进入 waiting 状态,只有等待通知notify或者notifyAll才会继续执行,这个时候 会释放对象的锁。因此呢,wait 方法一般用在同步方法或同步代码块中。
sleep线程睡眠,让当前线程休眠,此时线程处于阻塞的状态,当前线程进入timed-waiting状态
yield线程让步,我看源代码的意思是释放CPU资源,让其他线程抢夺CPU资源,实际用的时候,大概就是让当前线程先暂停,让其他线程先运行
join线程插队,我理解的呢就是让当前线程先运行,其他线程先等待,等运行完在执行其他线程
3、sleep和wait的区别
我之前写代码的时候也一直会用到这两个方法,我总结的区别大致分了三个方面
接着呢就是sleep不会解除cpu占用,wait会释放cpu资源
然后还有就是sleep会导致线程阻塞,时间到了之后,线程继续向下执行,但是wait必须配合notify或者notifyAll来唤醒
4、介绍下你理解的线程中的锁
我理解的锁的话,就是在多个线程同时访问一个数据的时候,为了保证数据的安全性,我们需要对数据操作的代码进行加锁处理,一般来说这个锁需要是对所有线程是一致的,一般可以用静态变量来作为锁,这个锁用synchronized关键字来包裹着,当这段代码块执行完之后,释放锁,然后其他线程获取到这个锁之后,才能执行这段代码,通过锁的机制很好的保护了多线程下的数据安全
但是在用锁的时候,如果使用不当的话会导致死锁的问题,就是A线程等待B释放锁,B线程同时在等待A释放锁,这样的话就会导致两个线程相互等待,造成死锁,所以在使用的时候尽量避免多线程之间相互依赖锁的情况发生
乐观锁的话就是比较乐观,每次去拿数据的时候,认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制或者CAS 算法实现。乐观锁在读操作比较多的场景比较适用,这样可以提高吞吐量,就像数据库提供的write_condition机制,其实都是乐观锁
悲观锁的话就是每次去拿数据的时候,也认为别人会修改数据,这个时候就会加上锁,这就导致其他线程想拿数据的话,就会阻塞,直到这个线程修改完成才会释放锁,让其他线程获取数据。在数据库里的行级锁、表级锁都是在操作之前就先锁住数据再操作数据 ,都属于悲观锁。Java中的 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现
5、线程池的原理
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线 程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。他的主要特点为:线程复用;控制最大并发数;管理线程。
6、线程池的核心参数都有哪些
-
corePoolSize(核心线程数)
(1)核心线程会一直存在,即使没有任务执行;
(2)当线程数小于核心线程数的时候,即使有空闲线程,也会一直创建线程直到达到核心线程数;
-
(1)也叫阻塞队列,当核心线程都在运行,此时再有任务进来,会进入任务队列,排队等待线程执行。
-
maxPoolSize(最大线程数)
(1)线程池里允许存在的最大线程数量;
锁
1、介绍一下乐观锁和悲观锁
乐观锁的话就是比较乐观,每次去拿数据的时候,认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制或者CAS 算法实现。乐观锁在读操作比较多的场景比较适用,这样可以提高吞吐量,就像数据库提供的write_condition机制,其实都是乐观锁
悲观锁的话就是每次去拿数据的时候,也认为别人会修改数据,这个时候就会加上锁,这就导致其他线程想拿数据的话,就会阻塞,直到这个线程修改完成才会释放锁,让其他线程获取数据。在数据库里的行级锁、表级锁都是在操作之前就先锁住数据再操作数据 ,都属于悲观锁。Java中的 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现
Java中各种锁其实都是悲观锁的实现,在操作数据的时候,数据都会被当前线程锁住。
2、介绍一下公平锁和非公平锁
公平锁:指线程在等待获取同一个锁的时候,是严格按照申请锁的时间顺序来进行的,这就意味着在程序正常运行的时候,不会有线程执行不到的情况,但是也需要额外的机制来维护这种顺序,所以效率相对于非公平锁会差点
非公平锁:概念跟“公平锁”恰恰相反,随机线程获取锁,效率相对高,可能会导致某些线程一直获取不到CPU资源而执行不到
创建一个ReentrantLock默认就是非公平锁,当然也可以传入参数让他变成公平锁
new ReentrantLock(); //默认非公平锁
new ReentrantLock(true); //公平锁
3、重入锁(递归锁)和不可重入锁(自旋锁)
//demo不用记忆,理解代码
public class Demo {
private Lock lockA;//这是个锁
public Demo(Lock Lock) {
this.lockA = lock;
}
public void methodA() {//业务逻辑A
lockA.lock();//获取锁,加锁
methodB();//执行业务逻辑B
lockA.unlock();//解锁
}
public void methodB() {//业务逻辑B
lockA.lock();//同样获取锁,加锁操作
//dosm
lockA.unlock();//解锁
}
}
重入锁:当我们运行methodA()的时候,线程获取了lockA,然后调用methodB()的时候发现也需要lockA,由于这是一个可重入锁,所以当前线程也是可以直接进入的。在java中,synchronized跟ReetrantLock都是可重入锁。
不可重入锁:methodA进入methodB的时候不能直接获取锁,必须先调用unLock释放锁。才能执行下去
4、共享锁和独占锁
独占锁
独占锁模式下,每次只能有一个线程能持有锁,ReentrantLock 就是以独占方式实现的互斥锁。独占锁是一种悲观保守的加锁策略,它避免了线程之间读取数据发生冲突,如果某个只读线程获取锁,则其他读线程都只能等待
共享锁
共享锁则允许多个线程同时获取锁,并发访问 共享资源,比如说:ReadWriteLock。共享锁则是一种乐观锁,它放宽了加锁策略,允许多个执行读操作的线程同时访问共享资源。
5、synchronized和threadlocal的区别
synchronized关键字主要解决多线程共享数据的同步问题。
ThreadLocal使用场合主要解决多线程中数据因并发产生不一致问题。
ThreadLocal和Synchonized都用于解决多线程并发访问,但是ThreadLocal与synchronized有本质的区别:
synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal是为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。在使用完成后需要注意的是,需要把threadlocal里的数据移除。
而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
6、ConcurrentHashMap如何实现线程安全
他的内部采用了的”分段锁”策略,ConcurrentHashMap的主干是个Segment数组。Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,默认有16 个 Segment,所以理论上,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。
Mysql
1、解释一下单列索引和联合索引
单列索引是指在表的某一列上创建索引,联合索引是在多个列上联合创建索引。单列索引可以出现在where条件的任何位置,而联合索引需要按照一定的顺序来写。在多条件查询的时候,联合索引的效率更高,我们联合索引也最多创建两列。
我们创建索引的时候也得考虑到我们这张表的更新频率,如果表里索引比较多的话是比较影响更新速度的,因为创建索引的过程其实就是构建一个二叉树,而每次更新完数据都得重新计算二叉树,所以就影响更新速度。
索引并不是时时都会生效的,比如以下几种情况就能导致索引失效:
- 如果条件中有or,即使其中有条件带索引也不会使用,这也是为什么尽量少用or的原因,如果要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- like查询是以%开头,会导致索引失效
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则索引失效
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
所以呢,我们创建索引的话,也不是随便创建的,我给您说下一些常用的创建索引的原则吧(接着背第四题)
2、使用索引查询的优缺点
使用索引优点第一:可以保证数据库表中每一行的数据的唯一性,第二:可以大大加快数据的索引速度,在使用分组和排序语句
缺点:创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
3、mysql存储引擎都有哪些,有什么区别
我了解到的数据库搜索引擎有MyISAM、InnoDB、BDB、MEMORY等,对于 MySQL 5.5 及更高版本,默认的存储引擎是 InnoDB。在 5.5 版本之前,MySQL 的默认存储引擎是 MyISAM,我主要给您介绍下这两个的区别吧
-
InnoDB 存储引擎:
优缺点:InnoDB的优势在于提供了良好的事务处理、崩溃修复能力和并发控制。缺点是读写效率较差,占用的数据空间相对较大。
-
MyISAM 存储引擎
不支持事务、支持表级锁
支持全文搜索
缓冲池只缓存索引文件,
我们项目中常用到的是innoDB,InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,但是对比Myisam的存储引擎InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
4、创建索引的原则
-
在经常使用 WHERE 语句的列上创建索引,加快条件的判断速度。
5、如何查看查询语句索引是否生效
使用 explain 执行计划查看 在sql前面加入关键字explain 查询出的结果查看type类型检查是否有执行索引
举例:EXPLAIN select * from table where id=2;我们一般优化sql语句的话,type级别都要至少达到ref级别,就是每次查询必须要使用索引
| 列 | 说明 |
|---|---|
id |
在一个大的查询语句中每个SELECT关键字都对应一个唯一的id |
select_type |
SIMPLE(simple):简单SELECT(不使用UNION或子查询)。 PRIMARY(primary):子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY。 UNION(union):UNION中的第二个或后面的SELECT语句。 DEPENDENT UNION(dependent union):UNION中的第二个或后面的SELECT语句,取决于外面的查询。 UNION RESULT(union result):UNION的结果,union语句中第二个select开始后面所有select。 SUBQUERY(subquery):子查询中的第一个SELECT,结果不依赖于外部查询。 DEPENDENT SUBQUERY(dependent subquery):子查询中的第一个SELECT,依赖于外部查询。 DERIVED(derived):派生表的SELECT (FROM子句的子查询)。 UNCACHEABLE SUBQUERY(uncacheable subquery):(一个子查询的结果不能被缓存,必须重新评估外链接的第一行) |
table |
表名 |
partitions |
匹配的分区信息 |
type |
针对单表的访问方法,参考下面的说明 |
possible_keys |
可能用到的索引 |
key |
实际上使用的索引 |
key_len |
实际使用到的索引长度 |
ref |
当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
rows |
预估的需要读取的记录条数 |
filtered |
某个表经过搜索条件过滤后剩余记录条数的百分比 |
Extra |
一些额外的信息 |
- type说明
| 类型 | 说明 |
|---|---|
| All | 最坏的情况,全表扫描 |
| index | 和全表扫描一样。只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。如在Extra列看到Using index,说明正在使用覆盖索引,只扫描索引的数据,它比按索引次序全表扫描的开销要小很多 |
| range | 范围扫描,一个有限制的索引扫描。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range |
| ref | 一种索引访问,它返回所有匹配某个单个值的行。此类索引访问只有当使用非唯一性索引或唯一性索引非唯一性前缀时才会发生。这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。 |
| eq_ref | 最多只返回一条符合条件的记录。使用唯一性索引或主键查找时会发生 (高效) |
| const | 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。当主键放入where子句时,mysql把这个查询转为一个常量(高效) |
| system | 这是const连接类型的一种特例,表仅有一行满足条件。 |
| Null | 意味说mysql能在优化阶段分解查询语句,在执行阶段甚至用不到访问表或索引(高效) |
6、有没有做过数据库建模,自己是设计表和模块
数据库建模就是使用PowerDesigner工具,先分析项目需求,前端先出相应的原型,根据原型,我开始做相应的表,设计初期的时候表会有些小浮动修改等,再根据需求设计详细字段。如果后期客户需求改变时,表结构后期跟着调整,就是这样使用工具不断完善过程就是建模,不过一些小的项目的话,简单的通过Navicat里的模型工具就可以实现了
7、左连接、右连接、内连接的区别
内连接的话,就是两表关联的数据才能查出来,关联不到的就查询不到。左连接就是以左表为主,左表数据全查,右表数据没有就显示null,右连接相反
我给您举个例子吧,比如员工和部门表,如果要查询出每个员工的信息以及他的部门信息,那么这个时候用内连接最合适。如果要查询出每个部门下对应的员工信息,那么就需要以部门表为左表,进行左连接查询。这样的话,没有员工的部门也可以被查询出来。
8、 count(1)和count(*) 有什么区别
从执行结果来看count(*)和count(1)没有区别,因为他们都不过滤空值
从执行效率来看MySQL会对count(*)做优化
(1)如果列为主键,count(列名)效率优于count(1)
(2)如果列不为主键,count(1)效率优于count(列名)
(4)如果表中只有一列,则count(*)效率最优
9、mysql查询语句的优化?
-
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用 索引而进行全表扫描,如:
select id from t where num is null可以在 num 上设置默认值 0,确保表中 num 列没有 null 值,然后这样查询:select id from t where num=0 -
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引 而进行全表扫描,如:
select id from t where num=10 or num=20,可以使用可以这样查询:select id from t where num=10 union all select id from t where num=20 -
以%开头的模糊查询也会导致全表扫描:
select id from t where name like '%abc%',如果要提高效率的话,可以考虑全文检索来解决。 -
in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3 -
应尽量避免在 where 子句中对字段进行表达式操作,这将导致放弃使用索引 而进行全表扫描。如:
select id from t where num/2=100应改为:select id from t where num=100*2 -
应尽量避免在 where 子句中对字段进行函数操作,这将导致引擎放弃使用索引而 进行全表扫描。
比如说查询name以abc开头的数据:
select id from t where substring(name,1,3)='abc',可以改为select id from t where name like 'abc%' -
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中 的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可 能的让字段顺序与索引顺序相一致。
-
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)用下面的语句替换:select num from a where exists(select 1 from b where num=a.num) -
并不是所有索引对查询都有效,SQL 是根据表中数据来进行查询优化的,当索引 列有大量数据重复时,SQL 查询可能不会去利用索引,如一表中有字段 sex,男、女的值 几乎各一半,那么即使在 sex 上建了索引也对查询效率起不了作用。
-
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低 了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索 引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过 6 个
10、mysql批量插入5000条数据如何优化?
- 第一种方法:
合并sql插入语句,合并后日志量减少,降低日志刷盘的数据量和频率,从而提高效率,通过合并SQL语句,
同时也能减少SQL语句解析的次数,减少网络传输的IO
比如:INSERT INTO table(uid,content, type) VALUES ('userid_0', 'content_0', 0);
改为:
INSERT INTO table (uid,content, type) VALUES ('userid_0', 'content_0', 0), ('userid_1','content_1', 1);
- 第二种方法:
这是因为进行一个INSERT操作时,MySQL内部会建立一个事务,在事务内才进行真正插入处理操作。通过使用同一个事务可以减少创建事务所消耗的时间,所有插入都在执行后才统一进行提交操作。
11、mysql查询重复数据?
查询重复数据:select * from A
where pid in (select pid from A group by pid having count(pid) > 1);
12、了解过MySQL存储过程和视图吗,介绍一下
- 存储过程
存储程序是被存储在服务器中的组合SQL语句,经过创建编译并保存在数据库中,用户可通过存储过程的名字调用执行。存储过程核心思想就是数据库SQL语言层面的封装与复用。使用存储过程可以较少应对系统的业务复杂性,但是会增加数据库服务器系统的负荷,所以在使用的时候需要综合业务考虑。
对应存储过程的名字使用call调用 ,把对应的参数传递进去,输出参数使用@声明
-- 创建存储过程
DROP PROCEDURE IF EXISTS p01_discount; //如果存在先删掉再创建
CREATE PROCEDURE p01_discount(IN consume NUMERIC(5,2),OUT payfee NUMERIC(5,2)) //声明存储过程,in输入参数 out输出参数
BEGIN
--判断收费方式
IF(consume>100.00AND consume<=300.00) THEN
SET payfee=consume*0.8;
ELSEIF(consume>300.00) THEN
SET payfee=consume*0.6;
ELSE
SET payfee = consume;
END IF;
SELECT payfee AS result;
END ;
-- 调用存储过程
CALL p01_discount(100.0,@discount);
- 视图
视图本身是一张虚拟表,不存放任何数据。在使用SQL语句访问视图的时候,获取的数据是MySQL从其它表中生成的,视图和表在同一个命名空间(因为表和视图共享数据库中相同的名称空间,因此,数据库不能包含具有相同名称的表和视图)。视图查询数据相对安全,视图可以隐藏一些数据和结构,只让用户看见权限内的数据,使复杂的查询易于理解和使用。
原来我们公司做过一个项目的时候,用的是5张表的联查,然后用sql语句来写的话,比较慢,比较麻烦,然后我们把这5张表的联查创建了一个视图,然后就直接查找的是视图,查询速度快,这个视图就是只能做查询,而不能做增删改操作
-- 创建视图
CREATE OR REPLACE VIEW user_order_view AS
SELECT
t1.id,t1.user_name,t2.order_no,t2.good_id,
t2.good_name,t2.num,t2.total_price
FROM v01_user t1
LEFT JOIN v02_order t2 ON t2.user_id =t1.id;
-- 视图调用
SELECT * FROM user_order_view WHERE user_name='Cicada';
13、where和having的区别
这两个都是添加查询条件用的。where的话就是拼接普通字段的查询条件,having后边跟上聚合之后数据的查询条件。
比如计算平均薪资在10k以上的部门信息,这会儿的话就要用select xx from table group by deptId having avg(salary)>10000
常用的聚合函数有:count、sum、avg、min、max
14、数据库三范式介绍一下
第二范式的话要满足第一范式,并且不可以把多种数据保存在同一张表中,即一张表只能保存一类数据,否则可能导致插入数据异常。
第三范式,直接性,不存在传递依赖,他要在满足第二范式的条件上,在每一列都和主键直接相关,而不能间接相关。
15、select语句的执行顺序
from—>where—>group by—>having—>计算所有的表达式—>order by– ->select 输出
大致上是这么个顺序,如果sql里有子查询的话,也会按照这个方式来执行的
16、mysql分库分表介绍下
分库分表的话,是解决MySQL数据量多了之后,单表单库存储量多了之后查询效率低下等问题的,主要分为两种方式,一个是水平拆分,另一个是垂直拆分
垂直拆分的话就是单个表中比如30个字段,拆分为两个表,一个表20个字段,一个表10个字段这样,或者按照其他方式拆分成3个表,这样的拆分原则呢就是将大字段或者不经常修改的或者经常查询的字段拆分出来,作为单独的表存储,然后跟主表一对一的关系存储,这样的话水平扩展了表,并且对功能也做了分离,高并发场景下,垂直拆分一定程度的提升IO性能,不过依然存在单表数据量过大的问题
水平拆分的话就是按照数据量来拆分,比如我们的表里,每个表最多存储200W条数据,然后每个表命名方式为user_0001、user_0002的方式,在查询的时候,用逻辑代码来控制数据查询。这样的话不存在单表单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力。不过水平拆分会导致跨分片的事务一致性难以保证,跨库的join关联查询性能较差,要根据具体的业务来判断具体适用那种分表方式
我们都是结合读写分离和mysql集群做的,读写分离以及集群的话,读写分离话保证了数据的安全性,集群的话其实就相当于水平拆分。这个我们项目中使用MyCat来做的,在mycat里配置好主库和从库,做增删改的时候是对主库进行操作,查询的时候是对从库进行操作,其实mysql本身从5.6以后的版本就带主从复制的功能了,他们是利用mysql里的log文件进行的数据同步
linux
1、linux常用命令
| 命令 | 解释 | 备注 |
|---|---|---|
| rm -rf | 删除服务器所有的文件 | -r 代表递归删除;-f代表强制删除;rm -rf /* |
| mkdir 文件夹名称 | 创建文件夹 | mkdir -p a/b/c;可以创建多级目录 |
| pwd | 显示当前绝对路径 | |
| tail -f xxx.log | 监控并输出最后几行内容 | 一般用于查看日志 |
| echo | 输出内容到控制台,或者文本 | echo "xxx" > a.txt 覆盖原有文本;echo "xxx" >> a.txt追加到原有文本最后一行touch xxx.txt 创建文件 |
| ps -ef / ps aux | 查看系统进程 | 一般跟grep结合使用,查找某个进程用; 例如:`ps -ef |
| grep | 查找内容 | 可以查找文件中的内容 |
| yum install -y xxx | 使用yum安装应用 | -y代表要输入yes或者no的时候,自动输入yes |
| curl | 控制台访问某个链接 | curl ifconfig.me 可以查看本机公网ip |
| wget | 一般用于下载文件 | |
| uname -r | 显示正在使用的内核版本 | |
| top | 实时监控系统使用情况 | 包括线程、内存、cpu等详细信息,curl+c退出监控 |
| find 路径 -name 关键字 | 查找路径下的某些文件 | 例如:find / -name a.log从根目录开始查找叫a.log的文件关键字可以用*作为通配符, 例如: find / -name *.log查找以log即为的文件 |
| chmod | 给文件或者文件夹授权 | chmod -R 777 文件夹或者文件 |
| df -h | 查看磁盘分区列表以及使用情况 | |
| du -sh 文件夹或者文件 | 查看文件或者文件夹占用的磁盘空间 | |
| cat 文件 | 输出文件内容到控制台 | 如果是大文件,会导致控制台输出过多,可以使用more或者less替代 more是从前往后一页一页的输入文件内容 按空格下一页,b上一页,q退出, more -n 文件从第n行开始查看;使用more查看文件时,会先加载整个文件,再按照条件显示less也是一页一页查看文件内容个,less不会一次性加载整个文件内容,查看多少,加载多少 |
| nohup | 后台运行进程 | 例如后台运行springboot的jar项目:nouhp java -jar xxx.jar > /dev/null 2>&1 & |
2、服务器CPU一直100%,如何定位问题谈谈你能想到的思路
1、通过top -c 命令找出当前的进程列表,接着按P(大写)可以按照CPU使用率排序,然后找到进程对应使用率高的进程ID
2、然后通过top -Hp 进程PID列举出当前进程的所有线程,按P(大写)排序,找到对应线程的PID,转为16进制备用
3、然后通过jstack -l 线程PID > 文件,导出线程快照到这个文件里
4、然后通过grep命令查找文件中这个16进制的线程PID的行为进行分析
原文地址:https://blog.csdn.net/leader_song/article/details/132459697
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_47264.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
![[MFC] MFC消息机制的补充](https://img-blog.csdnimg.cn/direct/4e6d632d6c144126a691d901337a1749.png)