pandas是基于Numpy构建的,提供了众多比NumPy更高级、更直观的数据处理功能,尤其是它的DataFrame数据结构,可以用处理数据库或电子表格的方式来处理分析数据。
使用Pandas前,需导入以下内容:
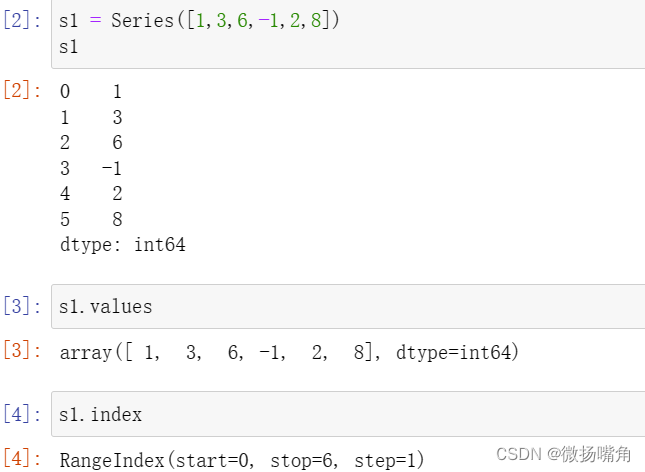
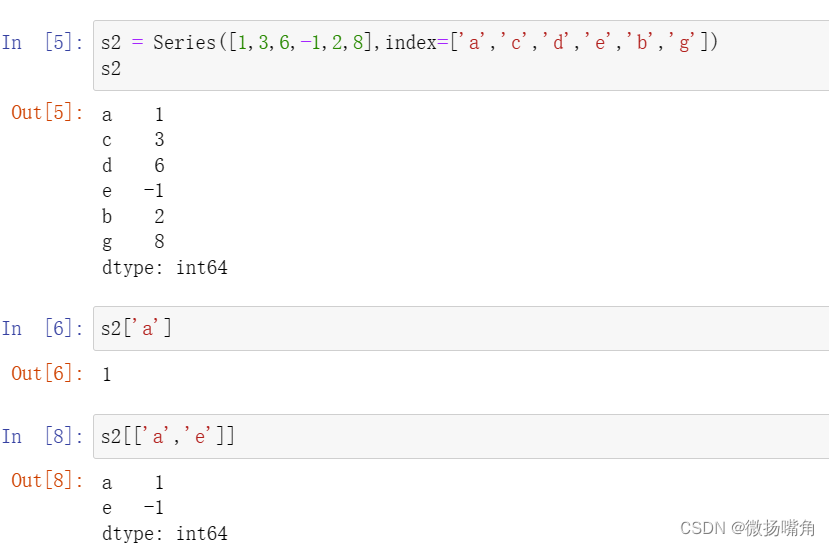
一、Pandas中两个最常用的对象是Series和DataFrame(最常用的两种数据结构)。1.Series是一种类似一维数据的数据结构,由数据(valus)及索引(indexs)组成。Series一个最大特点就是可以使用标签索引,Series的标签索引(它位置索引自然保留),定位也更精确,不会产生歧义。
例如:
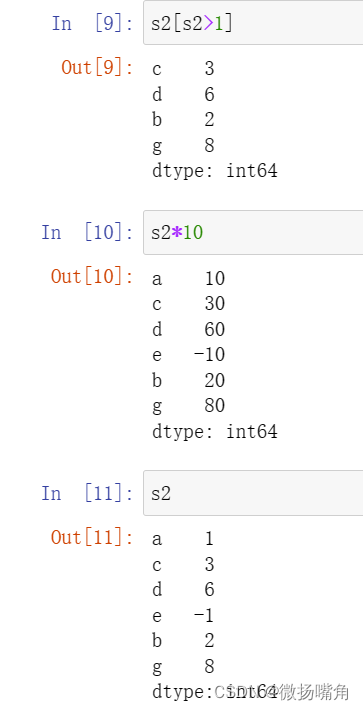
当然,Series除了标签索引外,还有其它很多优点,如运算的简洁.
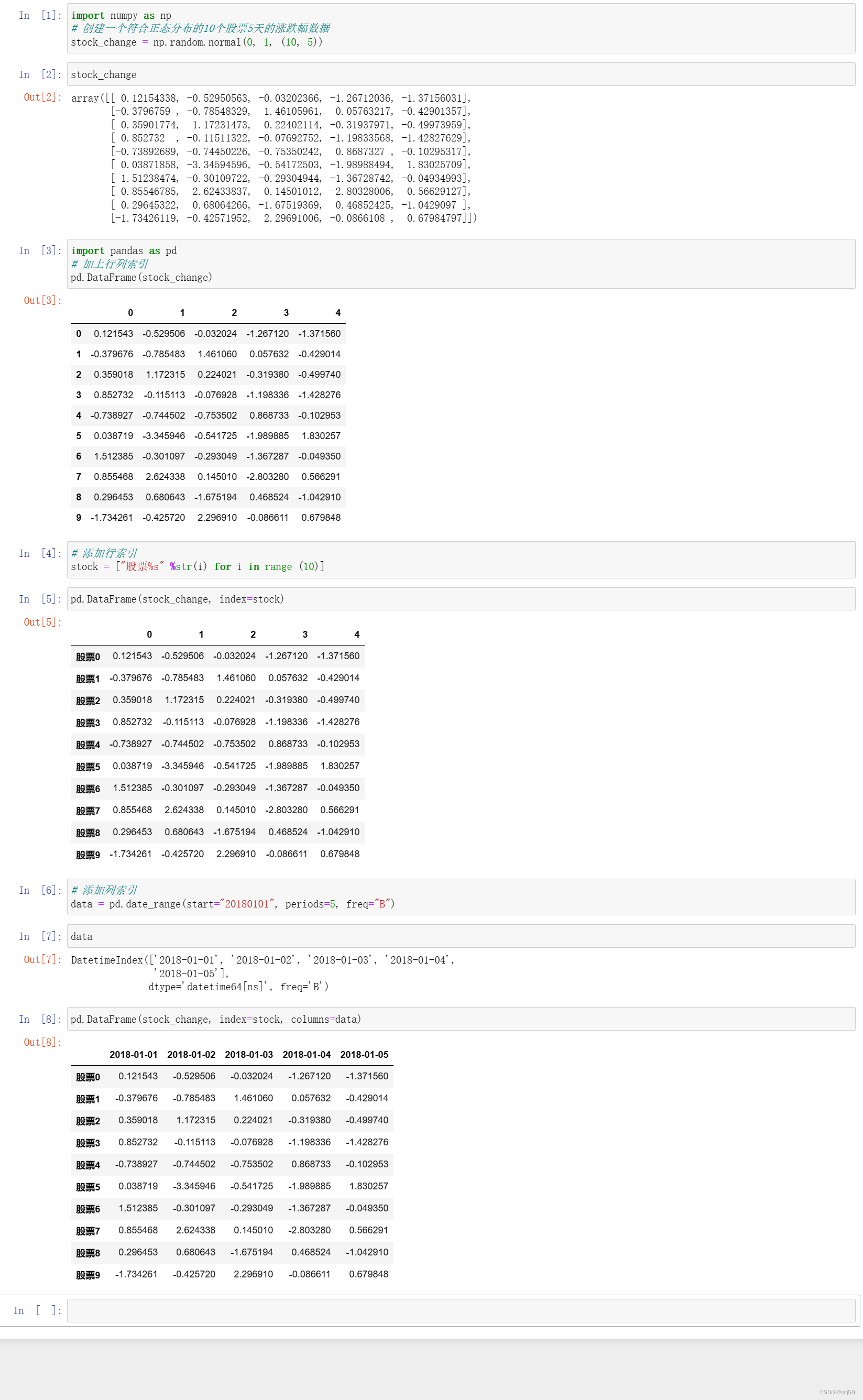
2.DataFrame是一个表格型的数据结构,它有一组有序列,每列的数据可以为不同类型,它既有行索引,也有列索引。DataFrame除了索引有位置索引也有标签索引,而且其数据组织方式与MySQL的表极为相似,除了形式相似,很多操作也类似,这就给我们操作DataFrame带来极大方便它还有比数据库表更强大的功能,如强大统计、可视化等等。
DataFrame几要素:index、columns、values等,columns就像数据库表的列表(列索引),index是索引(行索引),当然values就是值了。


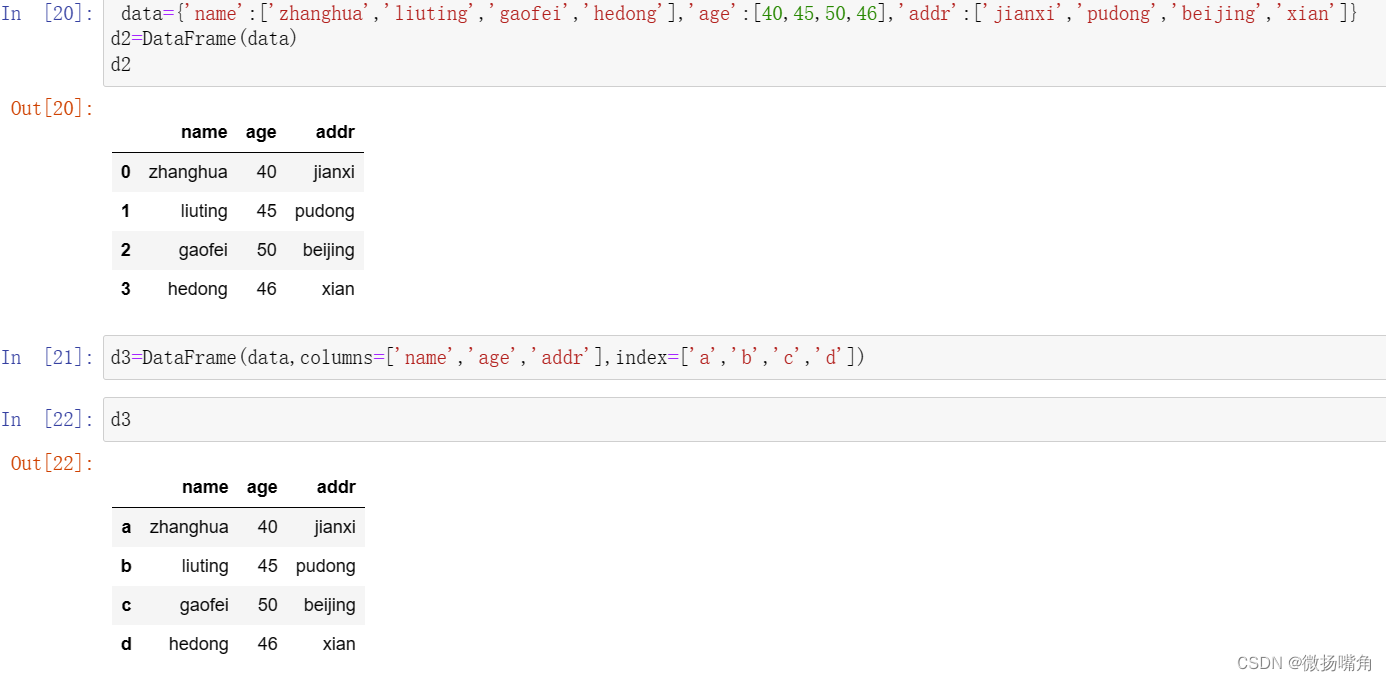
(1)生成DataFrame有很多,比较常用的有导入等长列表、字典、numpy数组、数据文件等。
导入字典:
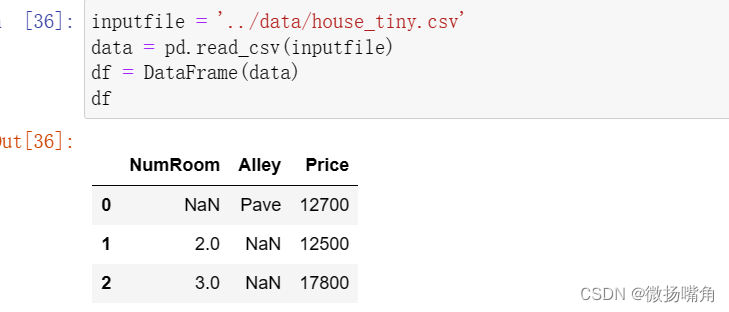
导入数据文件:
(2)获取DataFrame结构中数据


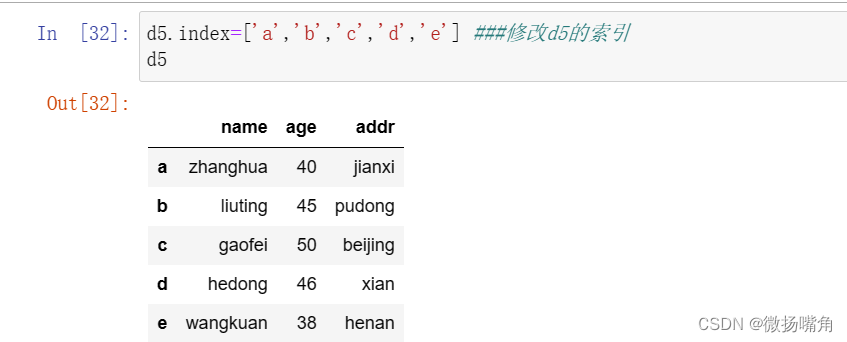
(3)修改DataFrame的数据
添加一行:

删除一行:
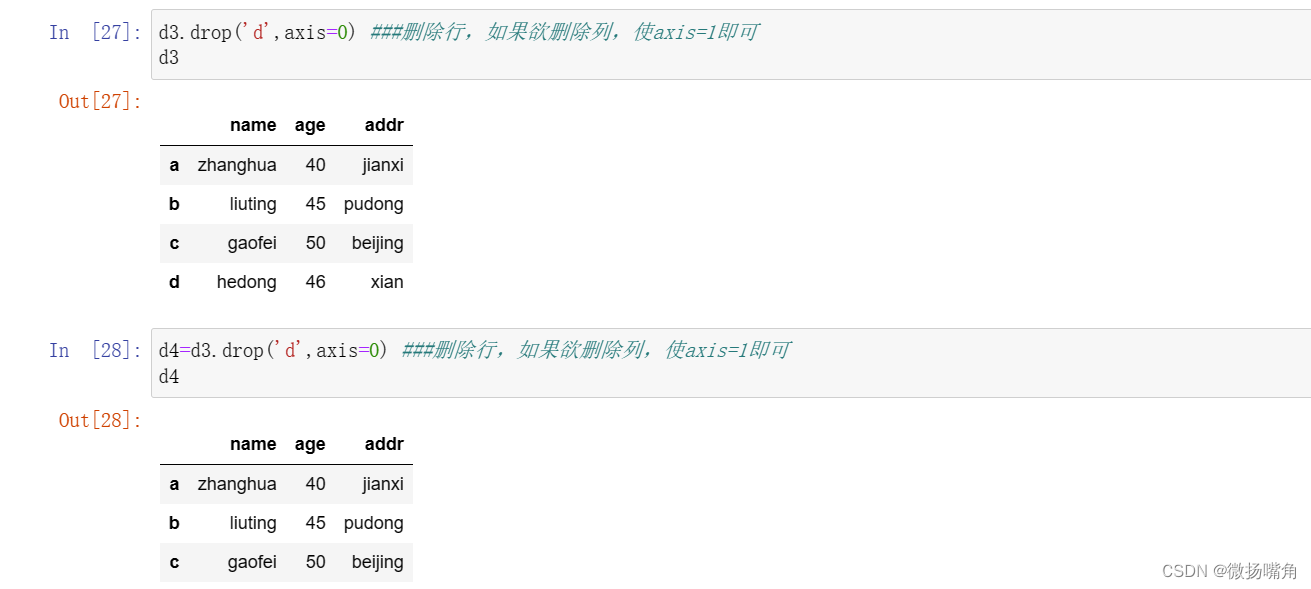
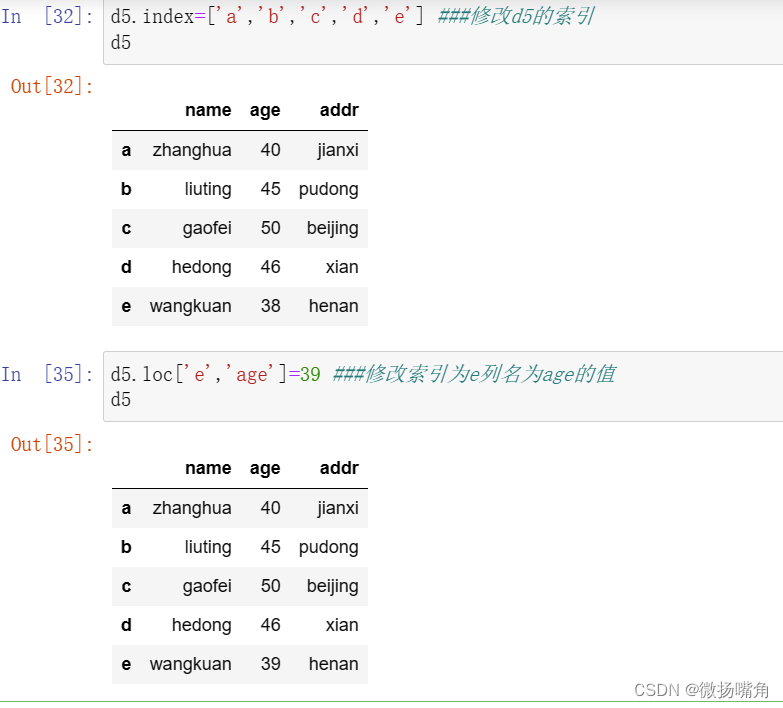
修改指定位置元素 :
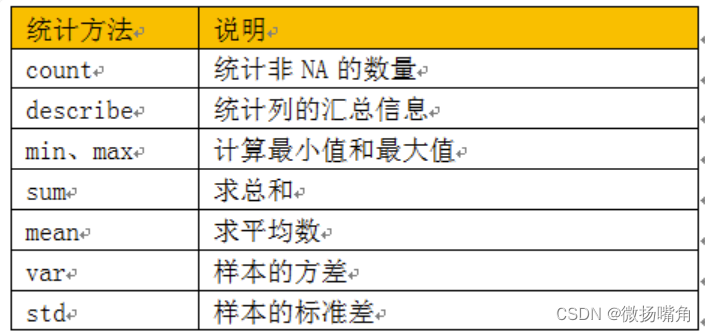
(4)汇总统计方法
Pandas有一组常用的统计方法,可以根据不同轴方向进行统计,当然也可按不同的列或行进行统计,非常方便。
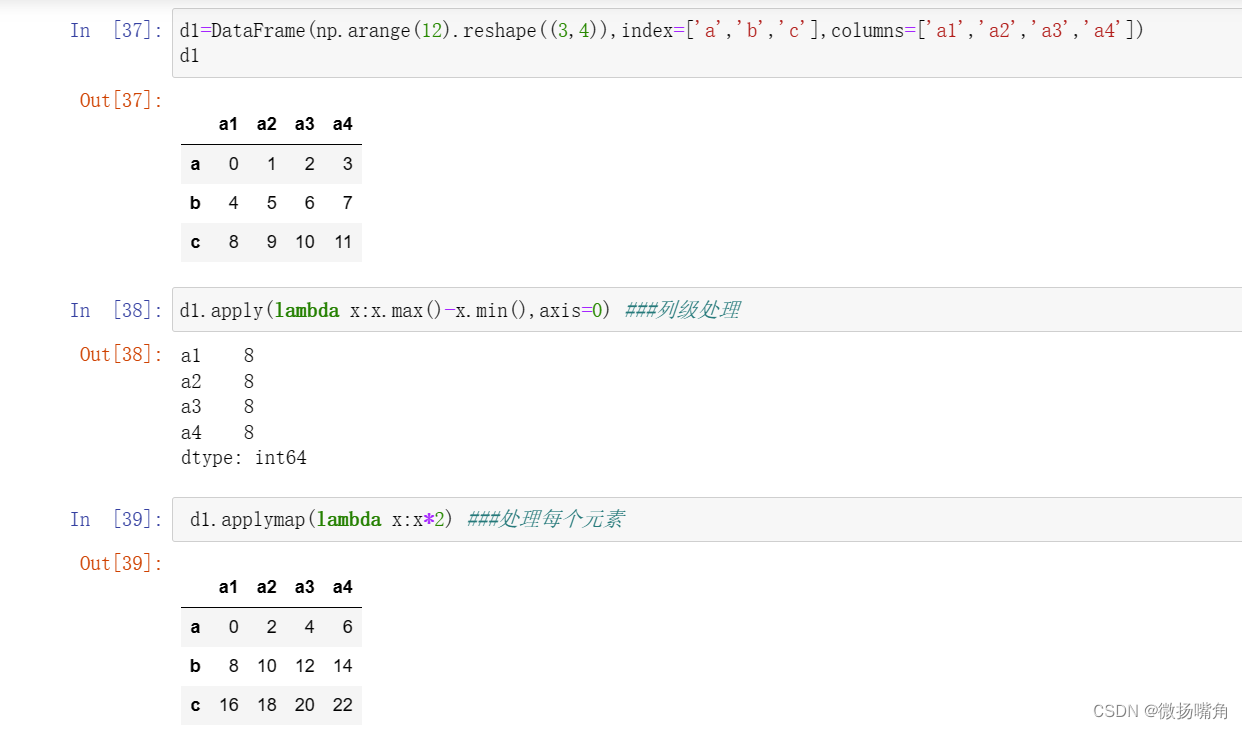
(5)应用函数及映射
我们知道数据库中有很多函数可用作用于表中元素,DataFrame也可将函数(内置或自定义)应用到各列或行上,而且非常方便和简洁,具体可用通过DataFrame的apply,使或applymap或map,也可以作用到元素级。以下通过实例说明具体使用。