本文介绍: 1.文件的读取1.read() 读取整个文件2.readline() 每次读取一行文件3. readlines() 读取文件的所有行2.文件的写入1.以”x“方式打开文件2.以”a“方式打开文件3.以”w“方式打开文件3.文件的删除4.Excel表数据的读取1.直接读取2.通过pd.ExcelFile()读取3.通过pd.read_excel()读取pd.read_excel()方法的常用参数5.Excel表数据的写入
1.文件的读取
操作文件的第一步就是得打开要操作的文件,然后进行读取文件,最后关闭文件。在python中我们可以使用open函数来打开一个文件,然后读取文本文件。
读取文本文件内容有三种方法:read()、readline() 和 readlines()
2.with语句能自动处理上下文环境产生的异常并且关闭文件句柄
1.read() 读取整个文件
2.readline() 每次读取一行文件
3. readlines() 读取文件的所有行
2.文件的写入
1.以”x“方式打开文件
2.以”a”方式打开文件
3.以”w“方式打开文件
3.文件的删除
4.Excel表数据的读取
1.直接读取
2.通过pd.ExcelFile()读取

3.通过pd.read_excel()读取
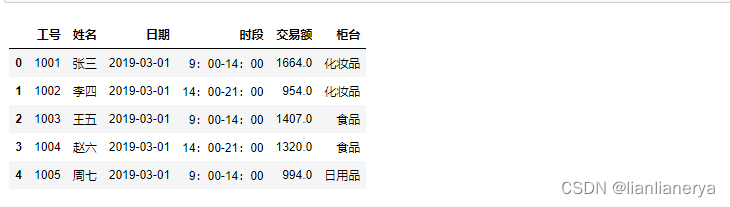
pd.read_excel()方法的常用参数

5.Excel表数据的写入
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。