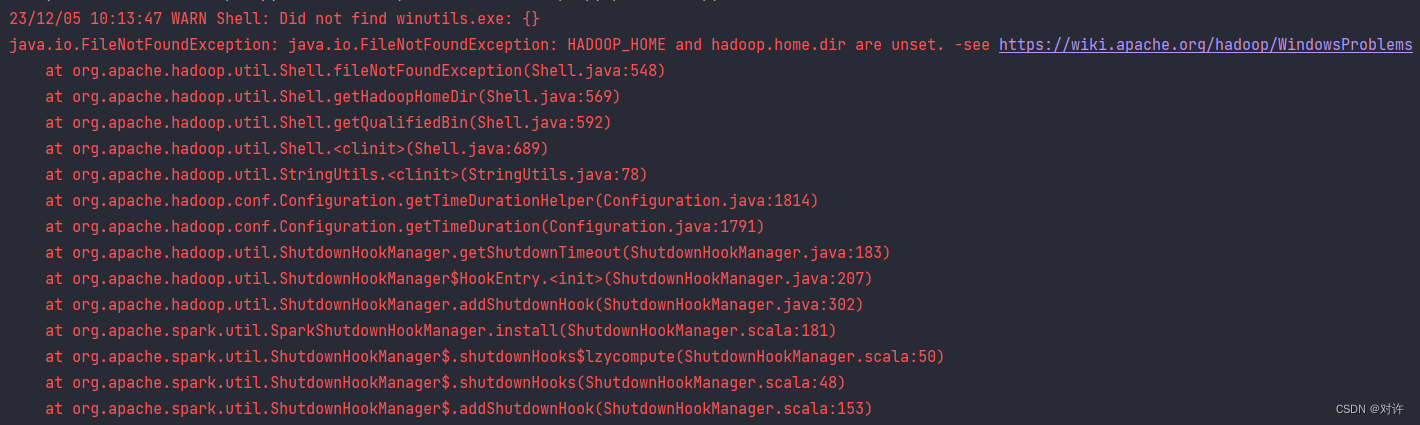
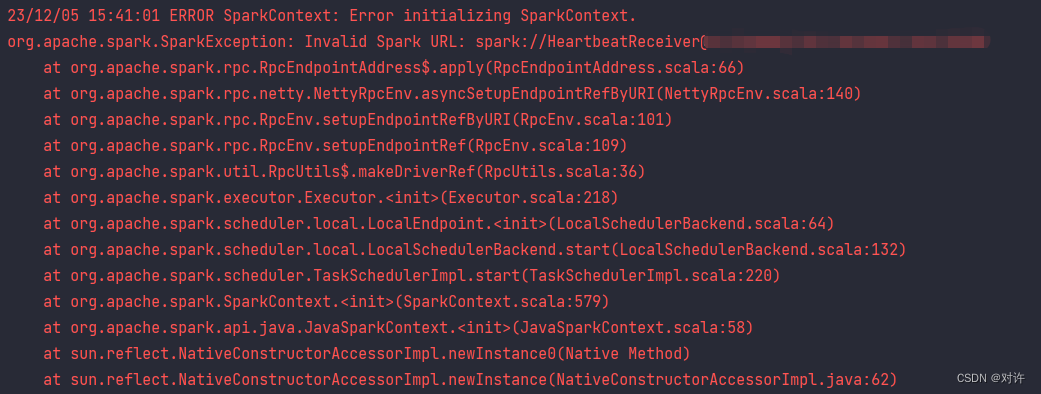
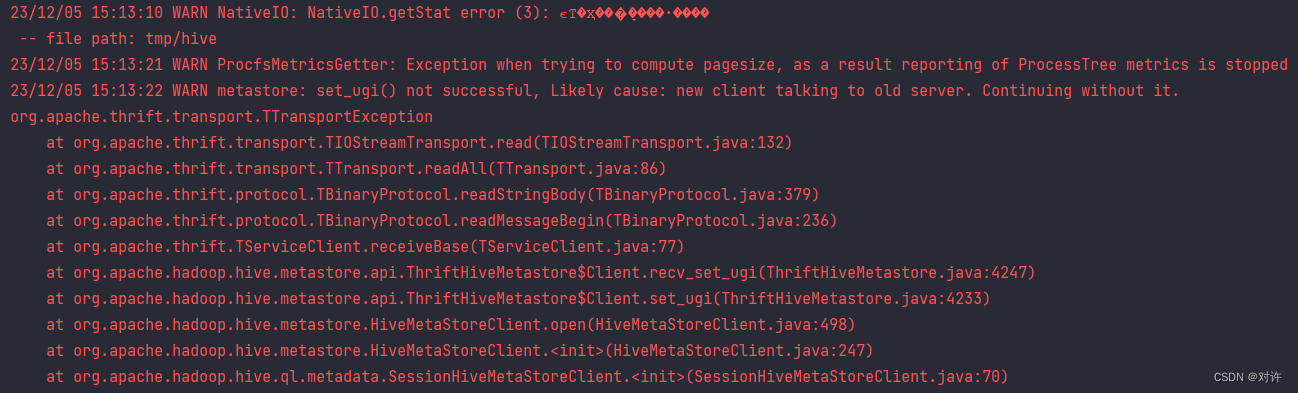
当前位置: 首页互联网正文 本文介绍: 版本与Hadoop集群版本不匹配。,并配置了环境变量,但未将。目录中(重启电脑才能生效)各版本下载链接见文末附录。,配置环境变量,并将。 PySpark环境搭建常见问题及解决 1、winutils.exe问题 2、SparkURL问题 3、set_ugi()问题 本文主要收录PySpark开发环境搭建时常见的一些问题及解决方案,并收集一些相关资源 1、winutils.exe问题 报错摘要: WARN Shell: Did not find winutils.exe: {} java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. ...... 原因1:缺少Hadoop的Windows支持环境:hadoop.dll和winutils.exe 详见官网:https://cwiki.apache.org/confluence/display/hadoop/WindowsProblems 原因2:已经下载hadoop.dll和winutils.exe,并配置了环境变量,但未将hadoop.dll和winutils.exe文件拷贝到C:WindowsSystem32目录中(重启电脑才能生效) 解决:下载Hadoop的Windows支持环境:hadoop.dll和winutils.exe,配置环境变量,并将hadoop.dll和winutils.exe文件拷贝到C:WindowsSystem32目录中,重启电脑 PS:hadoop.dll和winutils.exe各版本下载链接见文末附录 2、SparkURL问题 报错摘要: To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/12/05 14:50:09 ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Invalid Spark URL: spark://HeartbeatReceiver@*** ...... 原因:主机名带了下划线_或点.导致 解决: 方式1:添加配置:spark.driver.host=localhost 方式2:修改本机hosts文件:添加主机名与IP映射: 主机名 127.0.0.1 然后添加配置:spark.driver.bindAddress=127.0.0.1 Spark属性配置官方文档:https://spark.apache.org/docs/3.1.2/configuration.html 3、set_ugi()问题 报错摘要: 23/12/05 15:13:10 WARN NativeIO: NativeIO.getStat error (3): ϵͳ�Ҳ���ָ����·���� -- file path: tmp/hive 23/12/05 15:13:21 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped 23/12/05 15:13:22 WARN metastore: set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it. org.apache.thrift.transport.TTransportException ...... 可能原因:权限问题 解决:首先配置屏蔽:spark.executor.processTreeMetrics.enabled=false,然后尝试如下方式: 方式1:修改hdfs-site.xml # 在集群服务器的hdfs-site.xml文件中添加跳过权限验证 # 注意修改配置前先停止集群,配置结束之后,重启集群即可。经测试只需要修改NameNode上的配置文件即可 <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> 方式2:修改hive-site.xml # 新客户端与旧服务器通信,hive-site.xml与服务器不同步 # 在hive-site.xml中添加以下内容: <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> ================== 附录资源 ================== hadoop.dll和winutils.exe各版本下载:https://github.com/cdarlint/winutils/tree/master/hadoop-3.1.2 Hadoop各版本下载:https://archive.apache.org/dist/hadoop/common/ Spark各版本下载:http://archive.apache.org/dist/spark/ 原文地址:https://blog.csdn.net/weixin_55629186/article/details/134810156 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_48226.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。hadooppysparkwinutils 代码007普通 打赏 收藏 海报 链接