一、调度中心
首先下载XXL-JOB
GitHub:https://github.com/xuxueli/xxl–job
GitEE:https://gitee.com/xuxueli0323/xxl-job 项目使用2.3.1版本:
https://github.com/xuxueli/xxl-job/releases/tag/2.3.1
xxl-job-admin:调度中心 xxl-job-core:公共依赖
xxj-job-executor–samples:执行器Sample示例
xxl-job-executor–sample–springboot:SpringBoot版本,通过SpringBoot管理执行器
xxl-job-executor–sample–frameless:无框架版本
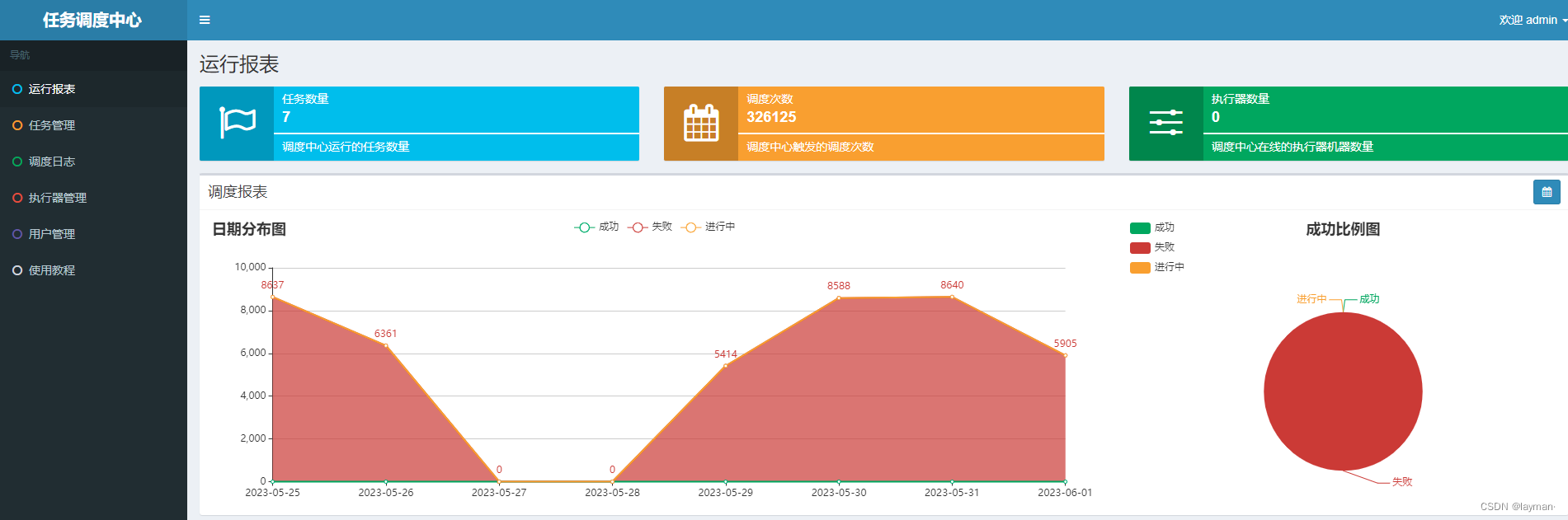
根据数据库脚本创建数据库,修改数据库连接信息和端口,启动xxl-job-admin,访问http://192.168.101.65:8088/xxl-job-admin/ 账号密码:admin/123456
二、执行器
下面配置执行器,执行器负责与调度中心通信,接收调度中心发起的任务调度请求
1.首先在media–service工程中添加依赖(父工程中完成了版本控制,这里的版本是2.3.1)
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
2. 在nacos下的media–service–dev.yaml下配置xxl-job
注意这里配置的appname是执行器的应用名,稍后会在调度中心配置执行器的时候使用
xxl:
job:
admin:
addresses: http://192.168.101.65:8088/xxl-job-admin/
executor:
appname: media-process-service
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job-jobhandler
logretentiondays: 30
accessToken: default_token
3.配置xxl-job的执行器
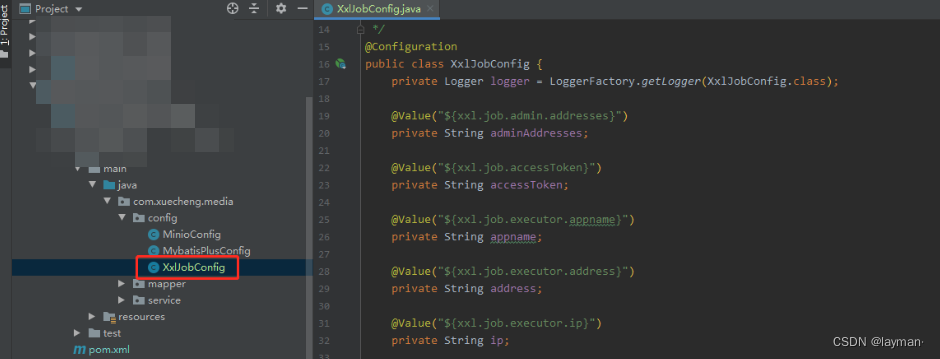
将示例工程下的配置类拷贝到media-service工程的config路径下,该类中的属性就是获取配置文件中的配置得到的,同时提供了一个执行器的Bean
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
4. 进入调度中心,添加执行器
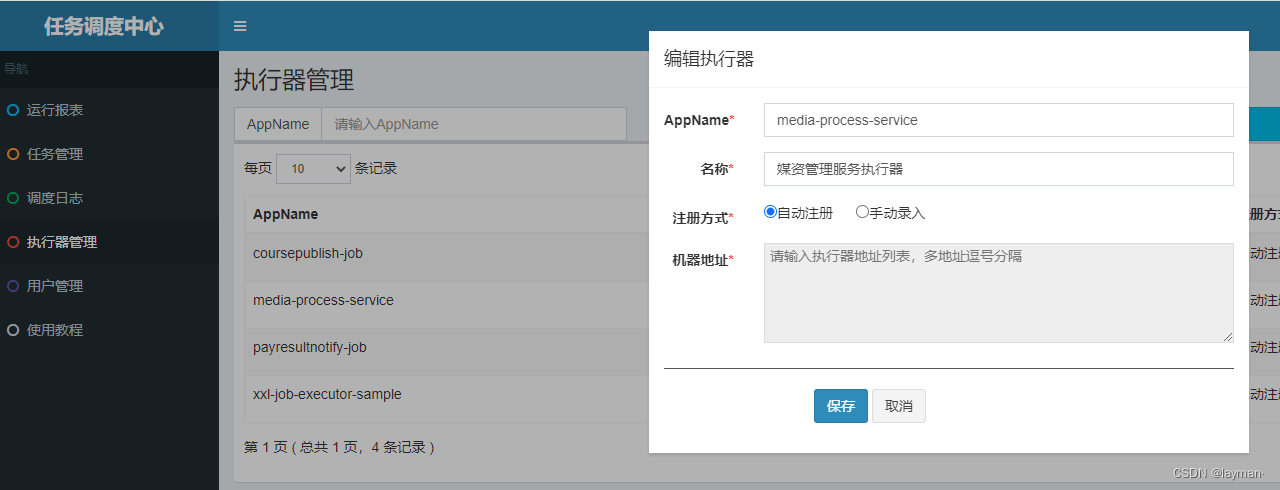
5. 重启媒资管理服务模块,可以看到执行器在调入中心注册成功
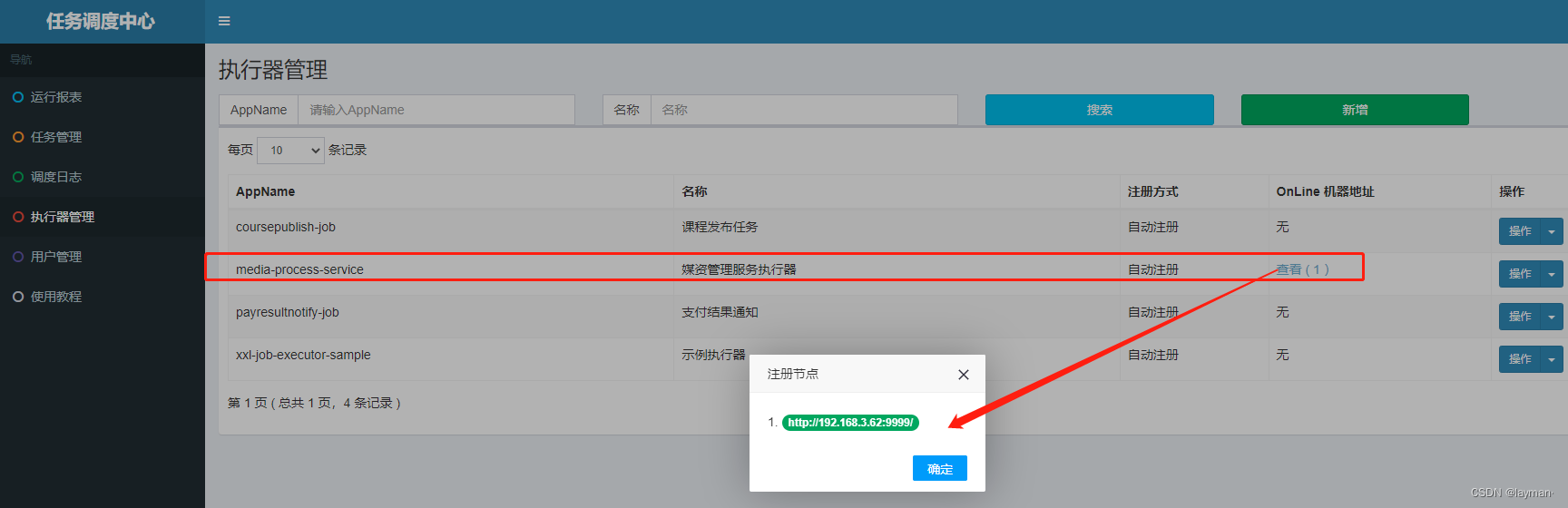
三、执行任务
在media-service下新建包com.xxxx.media.service.jobhandler,在该包下定义我们的任务类(创建任务类,编写任务方法)
package com.xxxx.media.jobhandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author layman
* @version 1.0
* @description TODO
* @date 2023/6/1 16:57
*/
@Slf4j
@Component
public class SimpleJob {
@XxlJob("testJob")
public void testJob() {
log.debug("开始执行.......");
}
}
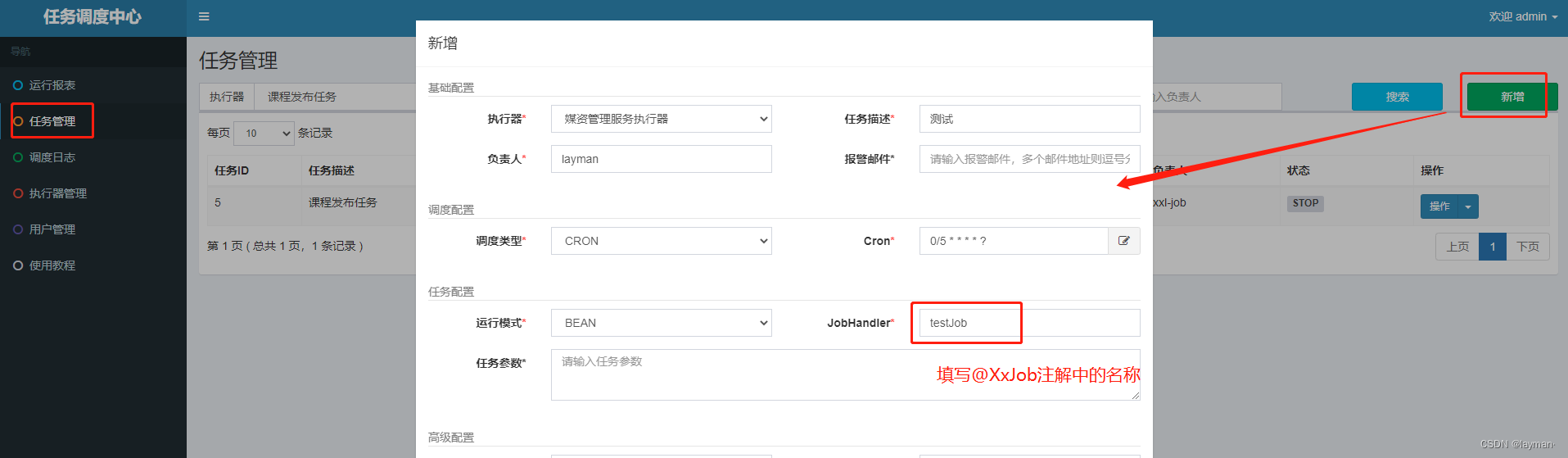
其中JobHandler中填写@XxlJob注解中的名称
随后重新启动media服务,并在任务管理中启动任务
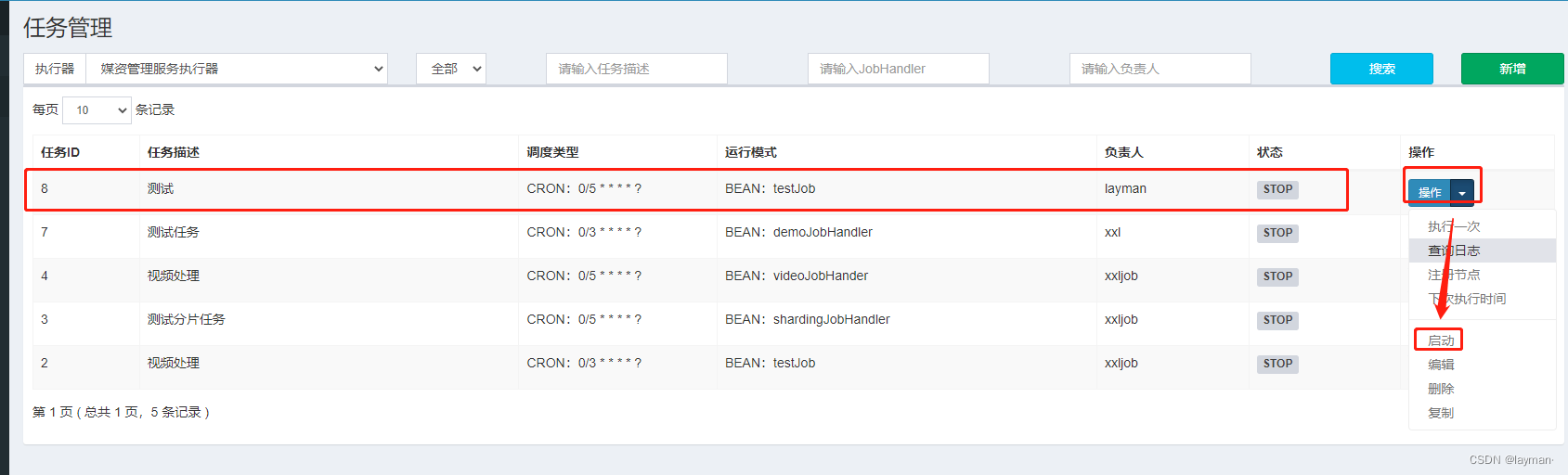
控制台可以看到执行器的方法执行

四、分片广播
前面我们了解了一下xxl-job的基本使用,下面思考如何进行分布式任务处理呢?
我们需要启动多个执行器组成一个集群,去执行任务
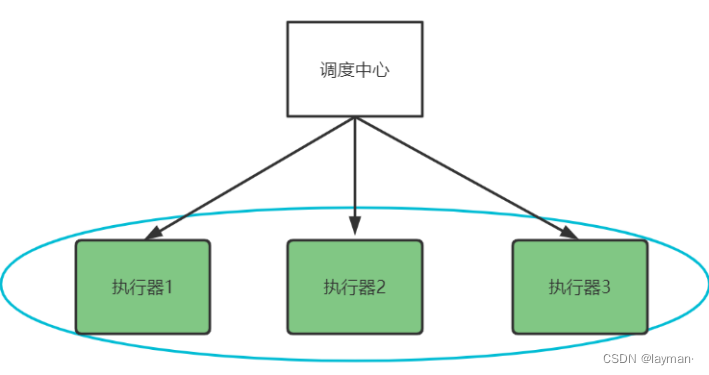
执行器在集群部署下调度中心有哪些调度策略呢?
查看xxl-job官方文档
- 高级配置:
– 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
– FIRST(第一个):固定选择第一个机器;
– LAST(最后一个):固定选择最后一个机器;
– ROUND(轮询):;
– RANDOM(随机):随机选择在线的机器;
– CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
– LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
– LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
– FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
– BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
– SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
我们这里重点要说的是SHARDING_BROADCAST(分片广播),分片是指调度中心将集群汇总的执行器标上序号:0、1、2、3…,广播是指每次调度会向集群中的所有执行器发送调度请求,请求中携带分片参数
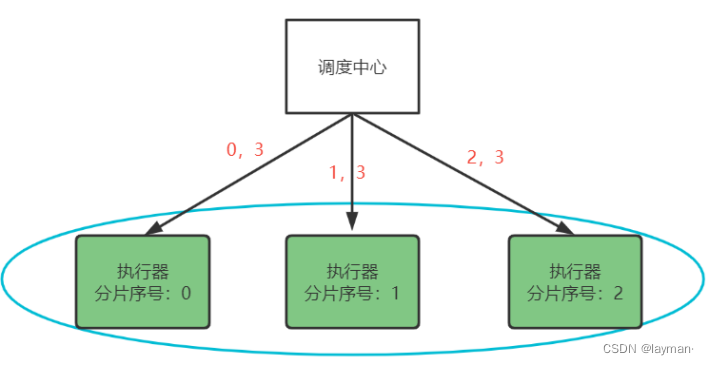
每个执行器收到调度请求,根据分片参数自行决定是否执行任务;另外xxl-job还支持动态分片,当执行器数量有变更时,调度中心会动态修改分片的数量
所以广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群的分布式处理任务。
使用说明
分片广播和普通任务开发流程一致,不同之处在于可以获取分片参数进行分片业务处理
获取分片参数方式,参考示例代码
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
// 业务逻辑
for (int i = 0; i < shardTotal; i++) {
if (i == shardIndex) {
XxlJobHelper.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobHelper.log("第 {} 片, 忽略", i);
}
}
}
@XxlJob("shardingJobHandler")
public void shardingJob() {
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
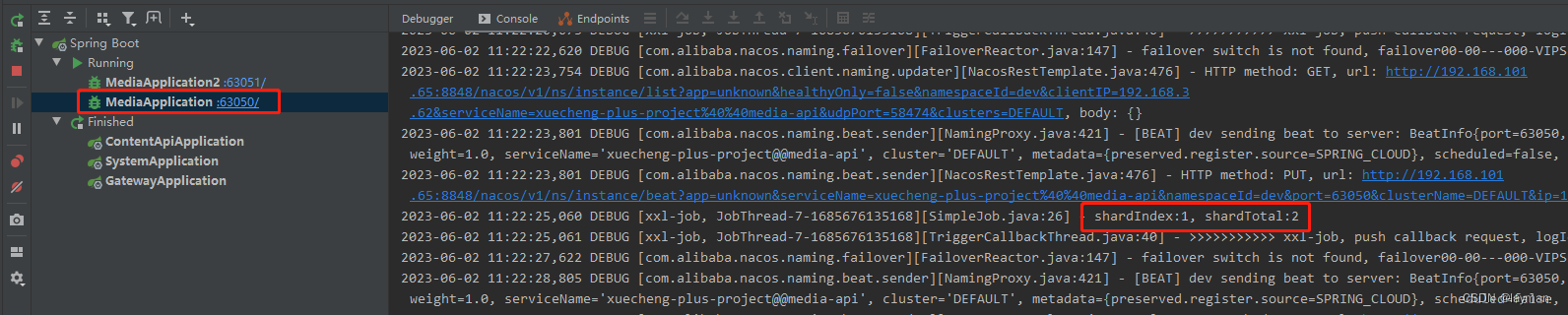
log.debug("shardIndex:{}, shardTotal:{}", shardIndex, shardTotal);
}
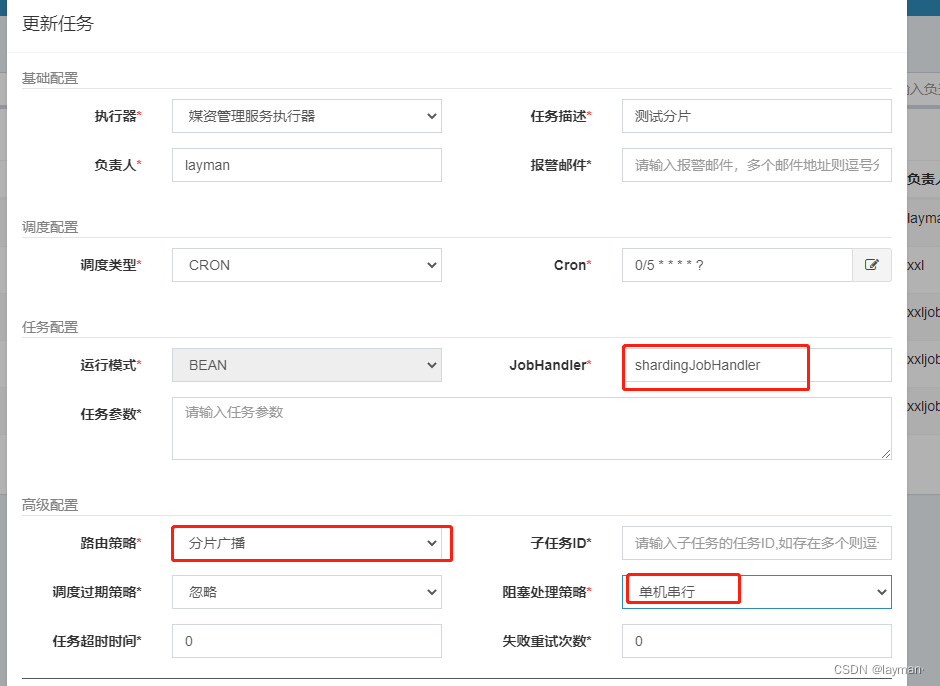
高级配置说明 :
子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度,通过子任务可以实现一个任务执行完成去执行另一个任务。调度过期策略: 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
spring:
cloud:
config:
override-none: true
将media-service启动两个实例,添加的vm选项就是用本地配置覆盖nacos中的配置,主要是修改端口号和xxl执行器端口
具体操作参见:https://blog.csdn.net/weixin_54514751/article/details/131002436?spm=1001.2014.3001.5501
将两个服务启动,观察任务调度中心,可以看到有两个执行器
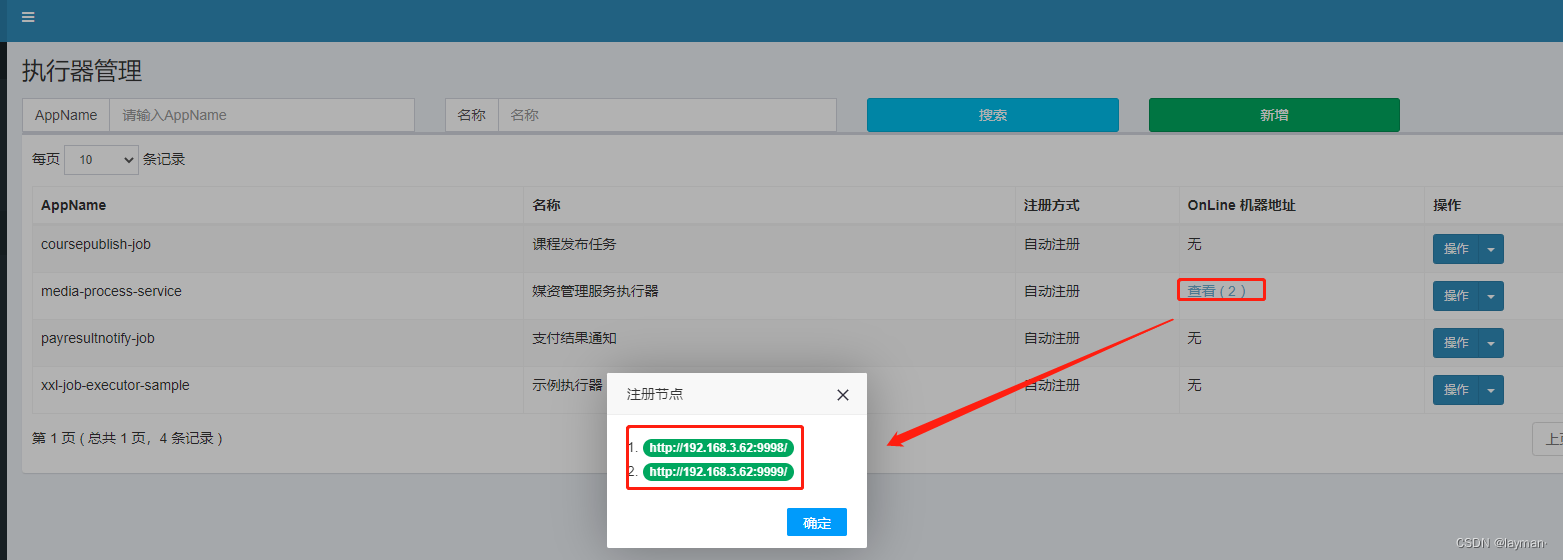
在控制台查看运行情况

原文地址:https://blog.csdn.net/weixin_54514751/article/details/130992453
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_48442.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!