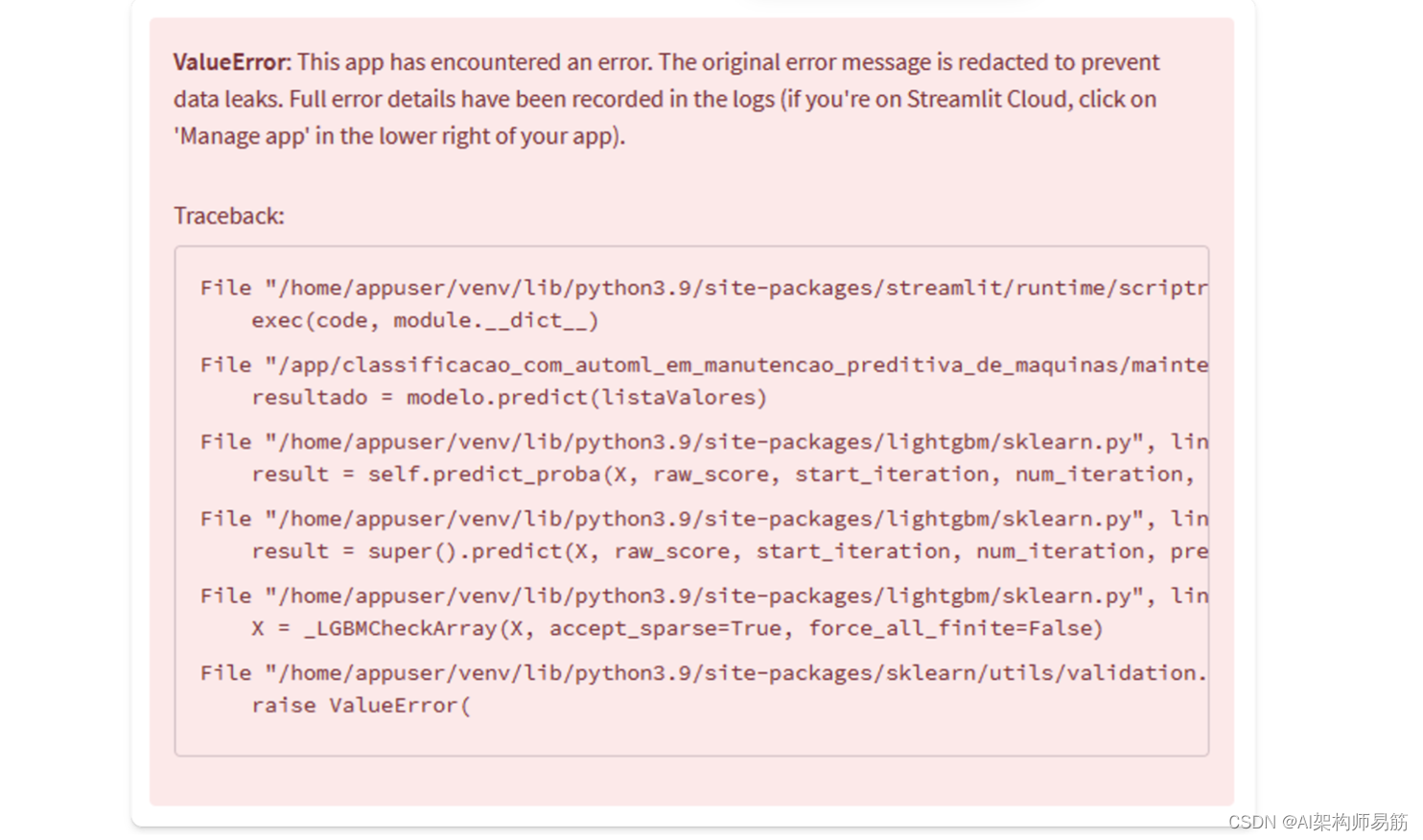
本文介绍: input经过矩阵计算得到权重att后,经过masked_fill掩码处理,得到了掩码的att权重,然后经过softmax归一化处理,最后的v乘积得到了每个output字符用前面input字符权重加权的表示,最后经过矩阵变换成voc_size大小的输出,就是我们要求的output输出,最后把我们计算得到output和target进行交叉熵损失函数计算,得到最终的loss,从而进行梯度下降优化整个模型。是的你没有看错,输入输出就是一个字符的错位。sentence:如何理解gpt的原理。
原理
gpt就是一个类似于成语接龙的游戏,根据之前的n个字符,预测下一个字符,那么gpt的输入和输出是如何构造的呢?比如给一个句子如下:
sentence:如何理解gpt的原理。
构造gpt输入输入:
input:如何理解gpt的原
output:何理解gpt的原理
是的你没有看错,输入输出就是一个字符的错位。
那么输入时如何经过self–mask–attention来得到输出的呢?
input经过矩阵计算得到权重att后,经过masked_fill掩码处理,得到了掩码的att权重,然后经过softmax归一化处理,最后的v乘积得到了每个output字符用前面input字符权重加权的表示,最后经过矩阵变换成voc_size大小的输出,就是我们要求的output输出,最后把我们计算得到output和target进行交叉熵损失函数计算,得到最终的loss,从而进行梯度下降优化整个模型。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。