1. Introduction
We are drowning in data, but starving for knowledge. (John Naisbitt, 1982)
Data mining draws ideas from machine learning, statistics, and database systems.
Methods
None of the data mining steps actually require a computer. But computers are scalability and they can help avoid human bias.
Basic process:
Apply data mining method -> Evaluate resulting model / patterns -> Iterate:
– Experiment with different parameter settings
– Experiment with different alternative methods
– Improve preprocessing and feature generation
– Combine different methods
2. Clustering
Intra-cluster distances are minimized: Data points in one cluster are similar to one another.
Inter–cluster distances are maximized: Data points in separate clusters are different from each other.
Application area: Market segmentation, Document Clustering
Types:
**Clustering algorithm: ** Partitional, Hierarchical, Density–based Algorithms
**Proximity (similarity, or dissimilarity) measure: ** Euclidean Distance, Cosine Similarity, Domain–specific Similarity Measures
Application area: Product Grouping, Social Network Analysis, Grouping Search Engine Results, Image Recognition
2.1 K-Means Clustering

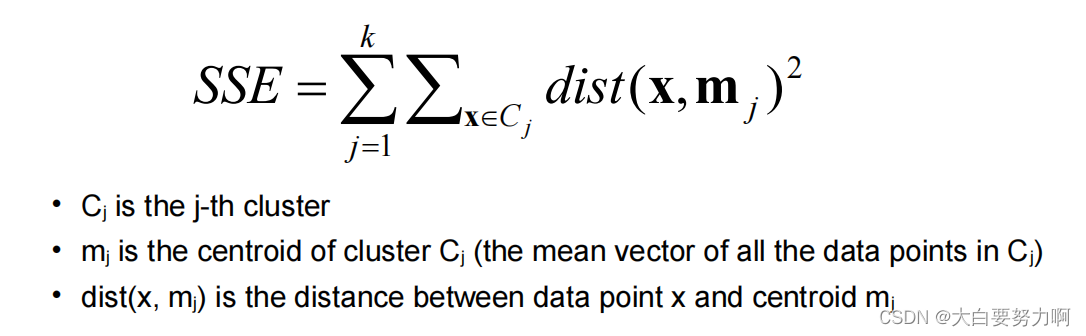
Weaknesses1: Initial Seeds
Results can vary significantly depending on the initial choice of seeds (number and position)
Improving: