在 Azure AI 搜索中,搜索索引是可搜索的内容,可供搜索引擎用于索引编制、全文搜索和筛选后查询。 索引由架构定义并保存到搜索服务中,第二步是数据导入。 除了在主数据存储中,此内容也存在于搜索服务中,这是在新式应用程序中实现预期的毫秒级响应时间所必需的。 除了特定的索引场景,搜索服务永远不会连接到本地数据或对其进行查询。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

搜索索引的内容
在 Azure AI 搜索中,索引包含搜索文档。 从概念上讲,文档是索引中的一个可搜索数据单元。 例如,零售商可能为每件商品都创建了文档,新闻机构可能为每篇报道都创建了文档,旅游网站可能为每家酒店和每个目的地都创建了文档。 将这些概念对应到更为熟悉的数据库等效对象:搜索索引等同于表,文档大致相当于表中的行 。
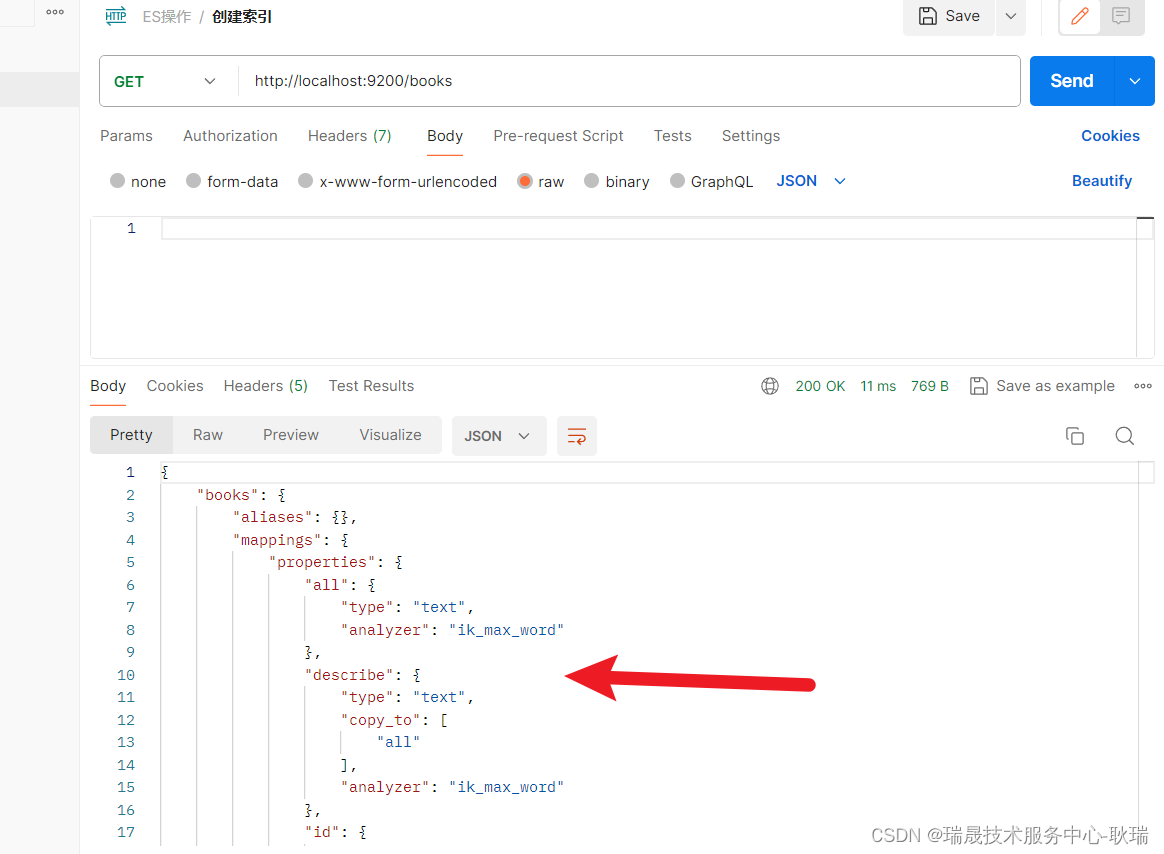
文档的结构由索引架构确定,如下所示。 通常,索引中大部分都是“字段”集合,其中每个字段都已命名、分配了[数据类型],并具有允许行为的属性(确定该字段的用法)。
{
"name": "name_of_index, unique across the service",
"fields": [
{
"name": "name_of_field",
"type": "Edm.String | Collection(Edm.String) | Edm.Int32 | Edm.Int64 | Edm.Double | Edm.Boolean | Edm.DateTimeOffset | Edm.GeographyPoint",
"searchable": true (default where applicable) | false (only Edm.String and Collection(Edm.String) fields can be searchable),
"filterable": true (default) | false,
"sortable": true (default where applicable) | false (Collection(Edm.String) fields cannot be sortable),
"facetable": true (default where applicable) | false (Edm.GeographyPoint fields cannot be facetable),
"key": true | false (default, only Edm.String fields can be keys),
"retrievable": true (default) | false,
"analyzer": "name_of_analyzer_for_search_and_indexing", (only if 'searchAnalyzer' and 'indexAnalyzer' are not set)
"searchAnalyzer": "name_of_search_analyzer", (only if 'indexAnalyzer' is set and 'analyzer' is not set)
"indexAnalyzer": "name_of_indexing_analyzer", (only if 'searchAnalyzer' is set and 'analyzer' is not set)
"synonymMaps": [ "name_of_synonym_map" ] (optional, only one synonym map per field is currently supported)
}
],
"suggesters": [ ],
"scoringProfiles": [ ],
"analyzers":(optional)[ ... ],
"charFilters":(optional)[ ... ],
"tokenizers":(optional)[ ... ],
"tokenFilters":(optional)[ ... ],
"defaultScoringProfile": (optional) "...",
"corsOptions": (optional) { },
"encryptionKey":(optional){ }
}
}
字段定义
[创建索引请求]主体中的“fields”集合定义了一个搜索文档。 你需要用于文档标识、存储可搜索文本的字段(键),以及用于支持筛选器、各个方面和排序的字段。 你可能还需要为某个用户永远看不到的数据设置字段。 例如,你可能希望设置用于修改搜索排名的利润率或市场促销活动的字段。
如果传入的数据在本质上已分层,就可在索引中将其表示为[复杂类型],用于表示嵌套结构。 内置的示例数据集 Hotels 演示的复杂类型使用一个 Address(包含多个子字段),其中有与每个酒店的一对一关系,并且有一个 Rooms 复杂集合,其中有多个房间与每个酒店相关联。
字段属性
字段属性决定了字段的使用方式,例如,是否用于全文搜索、分面导航和排序等操作中。
字符串字段通常标记为“searchable”和“retrievable”。 用来缩小搜索结果范围的字段包括“sortable”、“filterable”和“facetable”。
| Attribute | 描述 |
|---|---|
| “searchable” | 可全文搜索,在编制索引期间遵从语法分析,例如分词。 如果将某个可搜索字段设置为“sunny day”之类的值,在内部它将拆分为单独的标记“sunny”和“day”。 有关详细信息,请参阅[全文搜索工作原理]。 |
| “filterable” | 在
f i l t e ‘ E d m . S t r i n g ‘ 或 ‘ C o l l e t i o n ( E d m . S t r i n g ) ‘ 类型的可筛选字段不进行分词,因此,比较仅用于查找完全匹配项。例如,如果将此类字段 f 设置为“ s u n n y d a y ”,则 ‘ filter 查询中引用。 `Edm.String` 或 `Collection(Edm.String)` 类型的可筛选字段不进行分词,因此,比较仅用于查找完全匹配项。 例如,如果将此类字段 f 设置为“sunny day”,则 ` filter查询中引用。‘Edm.String‘或‘Collection(Edm.String)‘类型的可筛选字段不进行分词,因此,比较仅用于查找完全匹配项。例如,如果将此类字段f设置为“sunnyday”,则‘filter=f eq ‘sunny’ 找不到任何匹配项,但$filter=f eq ‘sunny day’` 可找到。 |
| “sortable” | 默认情况下,系统按分数对结果进行排序,但可以配置基于文档中字段的排序。 Collection(Edm.String) 类型的字段不能为“sortable”。 |
| “facetable” | 通常用于包括了按类别(例如特定城市中的宾馆)的命中次数的搜索结果呈现中。 此选项无法与 Edm.GeographyPoint 类型的字段一起使用。 Edm.String 类型的字段为可筛选,“sortable”或“facetable”字段的长度最多可以是 32 千字节。 有关详细信息,请参阅[创建索引 (REST API)]。 |
| “key” | 文档在索引内的唯一标识符。 必须仅选择单个字段作为键字段,并且它必须是 Edm.String 类型的。 |
| “retrievable” | 决定了是否可以在搜索结果中返回此字段。 当希望将某个字段(例如_利润_)用作筛选器、排序或评分机制,但不希望该字段显示给最终用户时,这很有用。 对于 key 字段,此属性必须为 true。 |
尽管可以随时添加新字段,但在索引的生存期内现有字段定义将被锁定。 因此,开发人员通常使用门户创建简单索引、测试创意,或者使用门户页面来查找设置。 如果采用基于代码的方式以便可以轻松重新生成索引,那么对索引进行频繁迭代的设计就更为高效。
用于生成索引的 API 具有不同的默认行为。 对于 [REST API],大多数属性在默认情况下处于启用状态(例如,“searchable”和“retrievable”对于字符串字段为 true),并且通常只需要在要关闭它们时设置它们。 对于 .NET SDK,情况恰恰相反。 对于未显式设置的任何属性,默认情况下禁用相应的搜索行为,除非你特别启用它。
物理结构和大小
在 Azure AI 搜索中,索引的物理结构主要是内部实现。 你可以访问其架构、查询其内容、监视其大小并管理容量,但群集本身(索引、分片以及其他文件和文件夹)是由 Microsoft 在内部管理。
可在 Azure 门户的“索引”选项卡中监视索引大小,针对搜索服务发出 [GET INDEX 请求]也可实现此目的。 还可以发出[服务统计信息请求]并检查存储大小的值。
索引的大小由以下内容决定:
文档的撰写和数量将由你选择导入的内容决定。 请记住,搜索索引应该只包含可搜索的内容。 如果源数据包含二进制字段,则忽略这些字段(除非使用 AI 扩充功能来破解和分析内容,以创建文本可搜索信息)。
字段属性可确定行为。 为了支持这些行为,索引过程将创建必要的数据结构。 例如,“可搜索”属性将调用[全文搜索],从而扫描切分后的字词的反转索引。 相比之下,“可筛选”或“可排序”属性将支持对未修改的字符串进行迭代。 下一节中的示例显示了基于所选属性的索引大小的变化。
[建议器]是支持预先输入或自动完成查询的构造。 因此,在包含建议器时,索引过程将创建逐字字符匹配所需的数据结构。 建议器是在字段级别实现的,因此请仅选择对预先输入而言合理的字段。
演示属性和建议器的存储意义的示例
以下屏幕截图演示了各种属性组合产生的索引存储模式。 该索引基于“房地产示例索引”,你可使用“导入数据”向导和内置的示例数据轻松创建该索引。 尽管未显示索引架构,但可以基于索引名称推断属性。 例如,只选择了 realestate-searchable 索引中的“searchable”属性,只选择了 realestate-retrievable 索引中的“retrievable”属性,等等 。
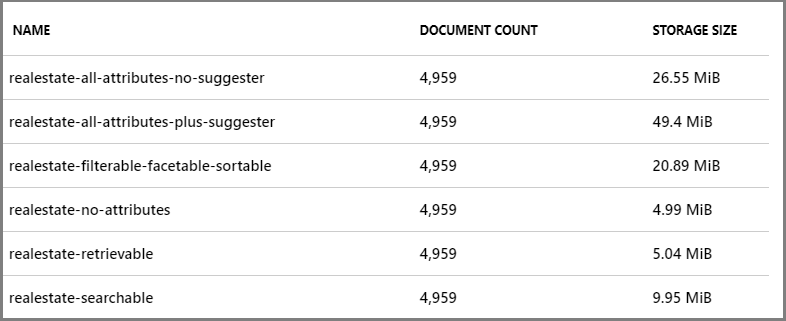
尽管这些索引变体是伪造的,但我们可以参考这些变体来对属性影响存储的方式进行大致比较:
- “可检索”不影响索引大小。
- “可筛选”、“可排序”、“可具面化”使用更多存储。
- 建议器极可能增加索引大小,但并不会像屏幕截图所示那么大(所有能感知建议器的字段都被选中,大多数索引中不太可能出现这种情况)。
未在上表中反映出的还有分析器的影响。 如果使用 edgeNgram 分词器来存储逐字字符序列 (a, ab, abc, abcd),则索引大小将大于使用标准分析器时的大小。
基本操作和交互
现在,你已对索引有了更好的了解,本部分接下来将介绍索引运行时操作,包括连接到单个索引并保护其安全。
备注
管理索引时,请注意,没有用于移动或复制索引的门户或 API 支持。 相反,客户通常将其应用程序部署解决方案指向不同的搜索服务(如果使用相同的索引名称),或者修改名称以在当前的搜索服务上创建副本,然后再生成它。
索引隔离
在 Azure AI 搜索中,将一次处理一个索引,其中与索引相关的所有操作都面向单个索引。 无论是编制索引还是查询,都不存在“相关索引”的概念或独立索引的联接。
持续可用
索引在第一个文档编制索引后可立即用于查询,但在所有文档编制索引后才能完全运行。 在内部,搜索索引[跨分区分布,并针对副本执行]。 物理索引在内部管理。 逻辑索引由你管理。
索引将持续可用,无法暂停或脱机。 由于它专为连续操作而设计,因此针对其内容的任何更新或向索引本身添加内容的操作都实时发生。 因此,如果请求与文档更新一致,查询可能会暂时返回不完整的结果。
注意,对于文档操作(刷新或删除)和不影响现有结构或当前索引完整性的修改(例如添加新的字段),存在查询连续性。 如需更新结构(更改现有字段),通常可在开发环境中使用“丢弃并重新生成”工作流进行管理,也可在生产服务上创建新版索引。
为了避免[索引重新生成],一些只进行细小改动的客户会选择创建与以前版本共存的新字段,以对字段进行“版本控制”。 随着时间的推移,这会导致出现孤立内容(采用过时字段或过时的自定义分析器定义形式),特别是在复制成本很高的生产索引中。 可在索引生命周期管理过程中,通过计划更新中处理这些问题。
终结点连接和安全性
所有索引和查询请求都以索引为目标。 终结点通常是以下其中一项:
| 终结点 | 连接和访问控制 |
|---|---|
<your-service>.search.windows.net/indexes |
以索引集合为目标。 在创建、列出或删除索引时使用。 这些操作需要管理员权限,通过管理员 [API 密钥]或[搜索参与者角色]可获得该权限。 |
<your-service>.search.windows.net/indexes/<your-index>/docs |
以单个索引的文档集合为目标。 在查询索引或数据刷新时使用。 对于查询,读取权限就已足够,通过查询 API 密钥或“数据读取者”角色可获得该权限。 对于数据刷新,需要管理员权限。 |
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
原文地址:https://blog.csdn.net/magicyangjay111/article/details/134756826
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_49156.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!