一键抠图1:Python实现人像抠图 (Portrait Matting)
一键抠图1:Python实现人像抠图 (Portrait Matting)
1. 项目介绍
抠图算法(英文中,一般称为Matting)有多种实现方式,一种是基于辅助信息输入的,加入一些先验信息(如Trimap,背景图,用户交互信息,深度等信息)提供抠图效果,如比较经典的Deep Image Matting和Semantic Image Matting这些算法加入Trimap; Background Matting算法需要提供背景图等;另一种是无需辅助信息,输入RGB图像,直接预测matte的方法,其效果相对第一种方法,会差很多。而对Portrait Matting(人像抠图),现在有很多方案在无需Trimap条件下,也可以获得不错的抠图效果,比如MODNet,Fast Deep Matting等算法,真正实现一健抠图的效果。

本篇博客是一键抠图项目系列之《Python实现人像抠图 (Portrait Matting)》,项目将在MODNet人像抠图算法基础上进行模型压缩和优化,开发一个效果相当不错的Matting算法,可以达到头发细致级别的人像抠图效果,为了方便后续模型工程化和Android平台部署,项目提供高精度版本人像抠图和轻量化快速版人像抠图,并提供Python/C++/Android多个版本;
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/134784803
Android Demo APP下载地址:https://download.csdn.net/download/guyuealian/63228759

- 一键抠图1:Python实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134784803
- 一键抠图2:C/C++实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134790532
- 一键抠图3:Android实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134801795

2. 抠图算法
第一种方法,需要加入辅助信息,而辅助信息一般较难获取,这也限制其应用,为了提升Matting的应用性,针对Portrait Matting领域MODNet摒弃了辅助信息,直接实现Alpha预测,实现了实时Matting,极大提升了基于深度学习Matting的应用价值。
更多抠图算法(Matting),请参考我的一篇博客《图像抠图Image Matting算法调研》:
图像抠图Image Matting算法调研_image matting调研-CSDN博客文章浏览阅读4.3k次,点赞8次,收藏68次。1.Trimap和StrokesTrimap和Strokes都是一种静态图像抠图算法,现有静态图像抠图算法均需对给定图像添加手工标记以增加抠图问题的额外约束。Trimap,三元图,是对给定图像的一种粗略划分,即将给定图像划分为前景、背景和待求未知区域Strokes则采用涂鸦的方式在图像上随意标记前景和背景区域,剩余未标记部分则为待求的未知区域Trimap是最常用的先验知识,多数抠图算法采用了Trimap作为先验知识,顾名思义Trimap是一个三元图,每个像素取值为{0,128,…_image matting调研https://blog.csdn.net/guyuealian/article/details/119648686可能,有小伙伴搞不清楚分割(segmentation)和抠图(matting)有什么区别,我这里简单说明一下:
- 分割(segmentation):从深度学习的角度来说,分割本质是像素级别的分类任务,其损失函数最简单的莫过于是交叉熵CrossEntropyLoss(当然也可以是Focal Loss,IOU Loss,Dice Loss等);对于前景和背景分割任务,输出Mask的每个像素要么是0,要么是1。如果拿去直接做图像融合,就很不自然,Mask边界很生硬,这时就需要使用抠图算法了
- 抠图(matting): 而抠图本质是一种回归任务,其损失函数可以是MSE Loss,L1 Loss,L2 Loss等,对于前景和背景抠图任务,输出Mask的每个像素是0~1之间的连续值,可看作是对图像透明通道(Alpha)的回归预测。可以用公式表示为C = αF + (1-α)B ,其中α(不透明度)、F(前景色)和B(背景色),alpha是[0, 1]之间的连续值,可以理解为像素属于前景的概率。在人像分割任务中,alpha只能取0或1,而抠图任务中,alpha可取[0, 1]之间的连续值,
- 本质上就是一句话:分割是分类任务,而抠图是回归任务。
3. Matting数据集
其他的:
- VideoMatte240K
- PhotoMatte85
- GitHub – thuyngch/Human-Segmentation-PyTorch: Human segmentation models, training/inference code, and trained weights, implemented in PyTorch
- Automatic Portrait Segmentation for Image Stylization: 1800 images
- Supervisely Person: 5711 images
4. MODNet模型
(1) 项目安装

项目依赖python包请参考requirements.txt,使用pip安装即可:
numpy==1.21.6
matplotlib==3.2.2
Pillow==8.4.0
bcolz==1.2.1
easydict==1.9
onnx==1.8.1
onnx-simplifier==0.2.28
onnxoptimizer==0.2.0
onnxruntime==1.6.0
opencv-contrib-python==4.5.2.52
opencv-python==4.5.1.48
pandas==1.1.5
PyYAML==5.3.1
scikit-image==0.17.2
scikit-learn==0.24.0
scipy==1.5.4
seaborn==0.11.2
sklearn==0.0
tensorboard==2.5.0
tensorboardX==2.1
torch==1.7.1+cu110
torchvision==0.8.2+cu110
tqdm==4.55.1
xmltodict==0.12.0
pycocotools==2.0.2
pybaseutils==0.9.4
basetrainer项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
(2) 数据集说明
- 原论文MODNet使用了PPM-100数据集+私有的数据集,并合成了大部分训练数据
- 鄙人复现时,先使用matting_human_datasets数据集训练base–model当作pretrained模型;然后合并多个数据集(PPM-100 + RealWorldPortrait-636 + Deep Image Matting),采用背景图来自VOC+COCO+BG-20k ,一共合成了5W+的训练数据和500+的测试数据
- 合成的方法有两种:方法1:利用公式:合成图 = 前景*alpha+背景*(1-alpha) ;方法二:前景+mask+背景通过GAN生成;
这是Python实现的背景合成,需要提供原始图像image,以及image的前景图像alpha,和需要合成的背景图像bg_img:
def image_fusion(image: np.ndarray, alpha: np.ndarray, bg_img=(219, 142, 67)):
"""
图像融合:合成图 = 前景*alpha+背景*(1-alpha)
:param image: RGB图像(uint8)
:param alpha: 单通道的alpha图像(uint8)
:param bg_img: 背景图像,可以是任意的分辨率图像,也可以指定指定纯色的背景
:return: 返回与背景合成的图像
"""
if isinstance(bg_img, tuple) or isinstance(bg_img, list):
bg = np.zeros_like(image, dtype=np.uint8)
bg_img = np.asarray(bg[:, :, 0:3] + bg_img, dtype=np.uint8)
if len(alpha.shape) == 2:
# alpha = cv2.cvtColor(alpha, cv2.COLOR_GRAY2BGR)
alpha = alpha[:, :, np.newaxis]
if alpha.dtype == np.uint8:
alpha = np.asarray(alpha / 255.0, dtype=np.float32)
sh, sw, d = image.shape
bh, bw, d = bg_img.shape
ratio = [sw / bw, sh / bh]
ratio = max(ratio)
if ratio > 1:
bg_img = cv2.resize(bg_img, dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio)))
bg_img = bg_img[0: sh, 0: sw]
image = image * alpha + bg_img * (1 - alpha)
image = np.asarray(np.clip(image, 0, 255), dtype=np.uint8)
return image当然,为了方便JNI调用,我这里还实现C++版本图像合成算法,这部分图像处理的基本工具,都放在我的base-utils中
/***
* 实现图像融合:out = imgBGR * matte + bg * (1 - matte)
* Fix a Bug: 1-alpha实质上仅有B通道参与计算,多通道时(B,G,R),需改Scalar(1.0, 1.0, 1.0)-alpha
* @param imgBGR 输入原始图像
* @param matte 输入原始图像的Mask,或者alpha,matte
* @param out 输出融合图像
* @param bg 输入背景图像Mat(可任意大小),也可以通过Scalar指定纯色的背景
*/
void image_fusion(cv::Mat &imgBGR, cv::Mat matte, cv::Mat &out, cv::Mat bg) {
assert(matte.channels() == 1);
out.create(imgBGR.size(), CV_8UC3);
vector<float> ratio{(float) imgBGR.cols / bg.cols, (float) imgBGR.rows / bg.rows};
float max_ratio = *max_element(ratio.begin(), ratio.end());
if (max_ratio > 1.0) {
cv::resize(bg, bg, cv::Size(int(bg.cols * max_ratio), int(bg.rows * max_ratio)));
}
bg = image_center_crop(bg, imgBGR.cols, imgBGR.rows);
int n = imgBGR.channels();
int h = imgBGR.rows;
int w = imgBGR.cols * n;
// 循环体外进行乘法和除法运算
matte.convertTo(matte, CV_32FC1, 1.0 / 255, 0);
for (int i = 0; i < h; ++i) {
uchar *sptr = imgBGR.ptr<uchar>(i);
uchar *dptr = out.ptr<uchar>(i);
float *mptr = matte.ptr<float>(i);
uchar *bptr = bg.ptr<uchar>(i);
for (int j = 0; j < w; j += n) {
//float alpha = mptr[j] / 255; //循环体尽量减少乘法和除法运算
float alpha = mptr[j / 3];
float _alpha = 1.f - alpha;
dptr[j] = uchar(sptr[j] * alpha + bptr[j] * _alpha);
dptr[j + 1] = uchar(sptr[j + 1] * alpha + bptr[j + 1] * _alpha);
dptr[j + 2] = uchar(sptr[j + 2] * alpha + bptr[j + 2] * _alpha);
}
}
}(3) MODNet模型
本文主要在MODNet人像抠图算法基础上进行模型压缩和优化,关于《MODNet: Trimap-Free Portrait Matting in Real Time》,请参考:
- Paper: https://arxiv.org/pdf/2011.11961.pdf
- 官方Github: GitHub – ZHKKKe/MODNet: A Trimap-Free Solution for Portrait Matting in Real Time
MODNet模型学习分为三个部分,分别为:语义部分(S),细节部分(D)和融合部分(F)。
- 在语义估计中,对high-level的特征结果进行监督学习,标签使用的是下采样及高斯模糊后的GT,损失函数用的L2-Loss,用L2loss应该可以学到更soft的语义特征;
- 在细节预测中,结合了输入图像的信息和语义部分的输出特征,通过encoder–decoder对人像边缘进行单独地约束学习,用的是交叉熵损失函数。为了减小计算量,encoder–decoder结构较为shallow,同时处理的是原图下采样后的尺度。
- 在融合部分,把语义输出和细节输出结果拼起来后得到最终的alpha结果,这部分约束用的是L1损失函数。
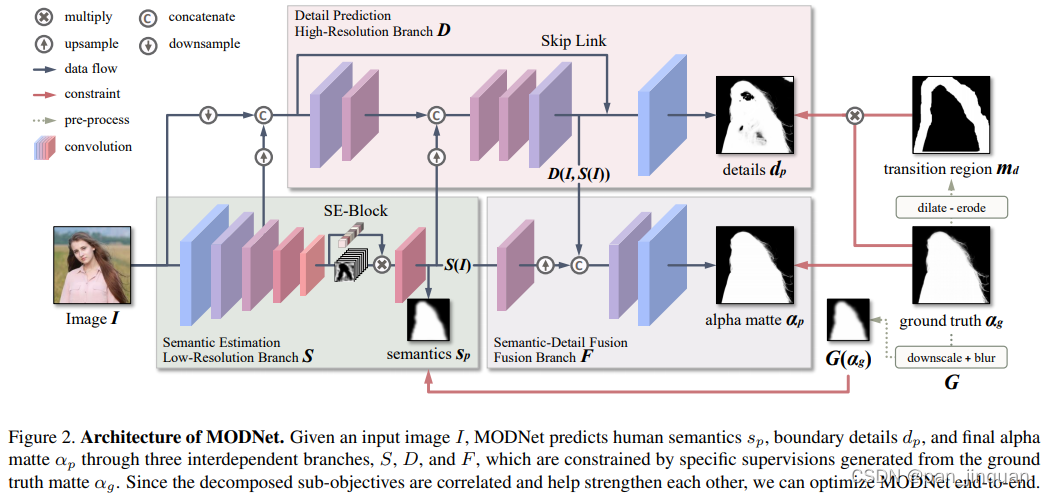
官方GitHub仅仅放出推理代码,并未提供训练代码和数据处理代码 ;鄙人参考原论文花了几个星期的时间,总算复现了其基本效果,并做了一些轻量化和优化的工作,主要有:
- 复现Pytorch版本的MODNet训练过程和数据处理
- 增加了数据增强方法:如多尺度随机裁剪,Mosaic(拼图),随机背景融合等方法,提高模型泛化性
- 对MODNet骨干网络backbone进行轻量化,减少计算量
- 模型压缩,目前提供三个版本:高精度人像抠图modnet+快速人像抠图modnet0.75+超快人像抠图modnet0.5
- 转写模型推理过程,实现C++版本人像抠图算法
- 实现Android版本人像抠图算法,支持CPU和GPU
- 提供高精度版本人像抠图,可以达到精细到发丝级别的抠图效果(Android GPU 150ms, CPU 500ms左右)
- 提供轻量化快速版人像抠图,满足基本的人像抠图效果,可以在Android达到实时的抠图效果(Android GPU 60ms, CPU 140ms左右)
高精度人像抠图modnet+快速人像抠图modnet0.75+超快人像抠图modnet0.5的模型参数量和计算量:
| 模型 | input size | FLOPs and Params |
| modnet | 416×416 | Model FLOPs 10210.24M, Params 6.44M |
| modnet0.75 | 320×320 | Model FLOPs 3486.23M, Params 3.64M |
| modnet0.5 | 320×320 | Model FLOPs 1559.07M, Params 1.63M |
最近发现,百度PaddleSeg团队也复现了MODNet算法(基于PaddlePaddle框架,非Pytorch版本),提供了更丰富的backbone模型选择,如MobileNetV2,ResNet50,HRNet_W18,可适用边缘端、服务端等多种任务场景,有兴趣的可以看看:
PaddlePaddle版本:https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.3/contrib/Matting
5. Demo测试效果
- 测试图片
# 测试图片
python demo.py --model_type "modnet" --model_file "work_space/modnet_416/model/best_model.pth" --image_dir "data/test_images"
# 测试视频文件
python demo.py --model_type "modnet" --model_file "work_space/modnet_416/model/best_model.pth" --video_file "data/video/video-test1.mp4"
- 测试摄像头
# 测试摄像头
python demo.py --model_type "modnet" --model_file "work_space/modnet_416/model/best_model.pth" --video_file 0


- 背景越单一,抠图的效果越好,背景越复杂,抠图效果越差;建议你实际使用中,找一比较单一的背景,如墙面,天空等
- 上半身抠图的效果越好,下半身或者全身抠图效果较差;本质上这是数据的问题,因为训练数据70%都是只有上半身的
- 白种人抠图的效果越好,黑人和黄种人抠图效果较差;这也是数据的问题,因为训练数据大部分都是隔壁的老外
下图是高精度版本人像抠图和快速人像抠图的测试效果,相对而言,高精度版本人像抠图可以精细到发丝级别的抠图效果;而快速人像构图目前仅能实现基本的抠图效果
| 高精度版本人像抠图 | 快速人像抠图 |
 |
 |
 |
 |
 |
 |
6. 源码下载(Python)
项目源码下载地址:Python实现人像抠图 (Portrait Matting)
- 提供Python的推理代码(不含训练代码和不含数据集)
- 提供高精度版本人像抠图模型(modnet_416),可以达到精细到发丝级别的抠图效果
- 提供轻量化快速版人像抠图模型(modnet0.75_320和modnet0.5_320),满足基本的人像抠图效果,
- Demo支持图片抠图,视频抠图,摄像头抠图
7.人像抠图C++版本
一键抠图2:C/C++实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134790532
8.人像抠图Android版本
一键抠图3:Android实现人像抠图 (Portrait Matting)https://blog.csdn.net/guyuealian/article/details/134801795


原文地址:https://blog.csdn.net/guyuealian/article/details/134784803
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_49204.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





