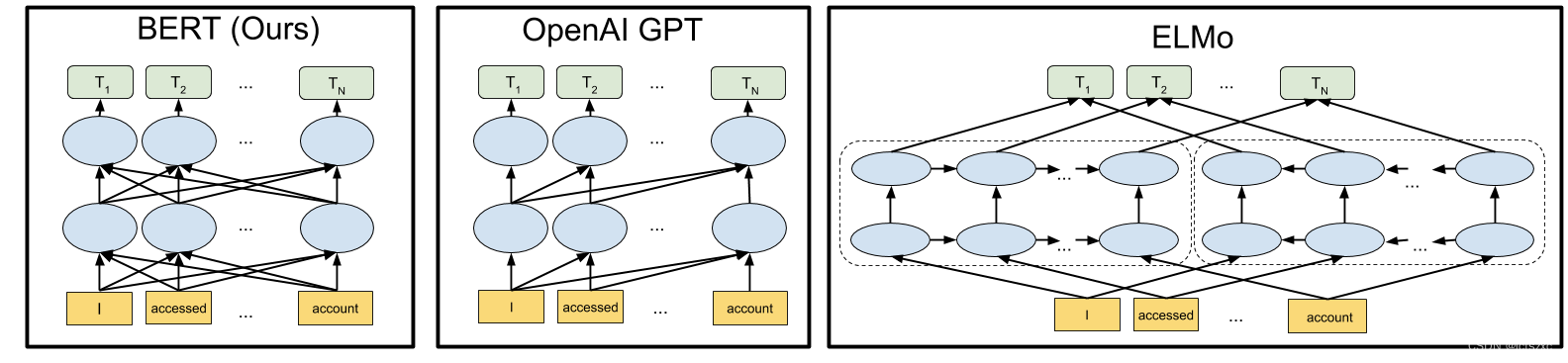
pytorch+huggingface+bert实现一个文本分类
bert模型的目前方便的有两种:一种是huggingface_hub以及/AutoModel.load, 一种torch.hub。
(1) 使用huggingface_hub或者下载模型。
# repo_id:模型名称or用户名/模型名称
from huggingface_hub import hf_hub_download
from transformers import AutoModel, AutoTokenizer
hf_hub_download(repo_id='bert-base-chinese', filename="pytorch_model.bin", local_dir='./bert-base-chinese') # 共下载五个:pytorch_model.bin, config.json,vocab.txt, tokenizer_config.json, tokenizer.json
# 直接下载/从~/.cache/huggingface/hub或者从指定文件夹
model = AutoModel.from_pretrain('bert-base-chinese')
tokenizer = AutoTokenizer.from_pretrain('bert-base-chinese')
# repo_or_dir:例如hugggingface/pytorch-transformers或者pytorch/vision, 或者本地目录
# source:github/local,默认是="github"
model = torch.hub.load('huggignface/pytorch-transformers', 'model', 'bert-base-chinese',source='github')
tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-chinese', source='github')
2, 使用模型
tokenizer(text):返回字典,包含:input_ids, token_type_ids,attention_mask。
tokenizer.encode(text):只返回input_dis。
两种方式都限定了text的方式,要么是单句,要么是列表。返回的结果也只有两种:[seq_length], [batch_size, seq_length]。
注意一,如果设定return_tensors=‘pt’,那么只会返回一种[batch_size, seq-length]。预训练模型只接受[batch_size, seq_length]形式输入。
注意二,bert模型返回两个结果,第一个是所有的最后一层hidden, 第二个是pooler_output,也就是所有最后一层hidden的加和平均值。models默认返回dict结果,使用mdoel().keys()返回变量值。使用values()返回结果。
from transformers import AutoModel, AutoTokenizer
import torch
model = AutoModel.from_pretrained('./bert-base-chinese')
tokenizer = AutoTokenizer.from_pretrained('./bert-base-chinese')
def bert_encode(line):
tokens = tokenizer(line, add_special_tokens=False, return_tensors='pt', padding=True, truncation=True, max_length=20)
with torch.no_grad():
last_hiddens, pooler_hidden = model(**tokens).values()
return last_hiddens, pooler_hidden
3,利用last_hidden通过rnn+dense进行文本分类。
rnn模型的本质只需要注意输入的形状:input:[seq_length, batch_size, feature_size] ,hidden_size:[num_layers, batch_size, hidden_size]。batch_size,都是放在中间,符合rnn处理的特点。
一个是所有token的最后一层hidden, [seq_length, batch_size, hidden_size]
一个是最后一个token的[num_layers, batch_size, hidden_size]
# 定义一个rnn模型
import torch
import torch.nn as nn
import torch.nn.functional as f
class myRNN(nn.Module):
def __init__(self, input_size, output_size, hidden_size, num_layers):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers=num_layers)
self.dense = nn.Linear(hidden_size * num_layers, output_size)
def forward(self, input_tokens):
"""
:param input_tokens: size()=[batch_size, seq_legnth, input_size]
:return: [batch_size, output_size]
"""
batch_size = input_tokens.size()[0]
hidden0 = self.init_hidden(batch_size)
input_tokens = input_tokens.transpose(0, 1)
all_hiddens, last_hiddens = self.rnn(input_tokens, hidden0) # last_hiddensize.size() = [num_layers, batch_szie, hidden_size]
last_hiddens = last_hiddens.transpose(0,1).reshape((batch_size, -1))
last_hiddens = f.relu(last_hiddens)
return self.dense(last_hiddens)
def init_hidden(self, batch_size):
return torch.zeros(size=(self.num_layers, batch_size, self.hidden_size))
4, 组装模型。
import torch.nn as nn
import torch
class Model(nn.Module):
def __init__(self):
super().__init__()
self.bert = bert_encode
self.rnn = myRNN(768,2, 768, 2)
def forward(self, lines):
tokens = self.bert(lines)[0]
return self.rnn(tokens)
from tqdm import tqdm
import torch
import time
import pickle
def train(epoches, model, dataloader, optim, criterion, model_save_path):
loss_mark = float('inf')
loss_store = [] # 收集每一轮的loss
acc_store = [] # 收集每一轮的acc率
model_num = 0
for epoch in tqdm(range(epoches)):
loss_sum = 0
acc_sum = 0
start = time.time()
for batch_num , (batch_line, batch_category) in tqdm(enumerate(dataloader)):
batch_pred = model(batch_line)
acc = (batch_pred.argmax(-1) == batch_category).sum().item()
acc_sum += acc
loss = criterion(batch_pred, batch_category)
loss_sum += loss.item()
optim.zero_grad()
loss.backward()
optim.step()
if batch_num % 100 == 0:
print(f"batch_num: {batch_num} | timesince: {time.time() - start}")
start = time.time()
print(f"loss: {loss} | acc: {acc/len(batch_category)}")
print(f"epoch {epoch} | loss: {loss_sum / len(dataloader)} | acc: {acc_sum}")
loss_store.append(loss_sum/len(dataloader))
acc_store.append(acc_sum)
if loss_sum < loss_mark:
loss_store = loss_sum
torch.save(f'{model_save_path}/{model_num}.pth', pickle_module=pickle, pickle_protocol=2)
model_num += 1
return loss_store, acc_store
def valid(model, dataloader, criterion):
loss_sum = 0
with torch.no_grad():
for batch_line, batch_category in dataloader:
batch_pred = model(batch_line)
loss = criterion(batch_pred, batch_category)
loss_sum += loss.item()
return loss_sum / len(dataloader)
7, 读取数据,进行训练。
import pandas as pd
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, lines, category):
super().__init__()
self.lines = lines
self.category = category
def __getitem__(self, item):
return self.lines[item], self.category[item]
def __len__(self):
return len(self.lines)
train_data = pd.read_csv('./train_data.csv', header=None, sep='t')
category, lines = train_data[0].tolist(), train_data[1].tolist()
datasets = MyDataset(lines, category)
dataloader = DataLoader(datasets, batch_size=10, shuffle=True)
model = Model()
optim = Adam(model.parameters(), lr=1e-3)
criterion = CrossEntropyLoss()
train(epoches=1, model=model, dataloader=dataloader, optim=optim, criterion=criterion, model_save_path='./models')
读取模型时注意,如果保存的是模型全模型,那么在当前文件内需要有模型的定义。如果是参数,那么需要实体化一类模型类,使用load_state_dict()方法。
import torch
import pickle
from bert_encode import bert_encode
from MyRnn import myRNN
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.bert = bert_encode
self.rnn = myRNN(768, 2, 768, 2)
def forward(self, lines):
tokens = self.bert(lines)[0]
return self.rnn(tokens)
model = torch.load('./models/1.pth', pickle_module=pickle)
def predict(batch_lines, model):
batch_output = model(batch_lines)
return batch_output.argmax(-1)
原文地址:https://blog.csdn.net/Akun_2217/article/details/134752061
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_49262.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!