神经网络 模型表示
模型表示一
为了构建神经网络模型,我们需要首先思考大脑中的神经网络是怎样的?每一个神经元都可以被认为是一个处理单元/神经核(processing unit/Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
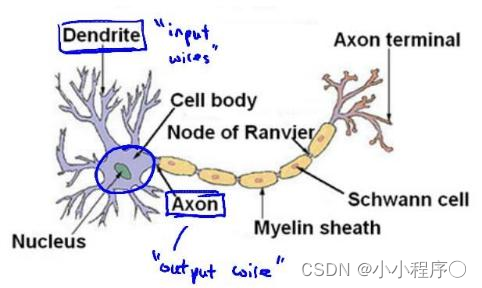
下面是一组神经元的示意图,神经元利用微弱的电流进行沟通。这些弱电流也称作动作电位,其实就是一些微弱的电流。所以如果神经元想要传递一个消息,它就会就通过它的轴突,发送一段微弱电流给其他神经元,这就是轴突。
这里是一条连接到输入神经,或者连接另一个神经元树突的神经,接下来这个神经元接收这条消息,做一些计算,它有可能会反过来将在轴突上的自己的消息传给其他神经元。这就是所有人类思考的模型:我们的神经元把自己的收到的消息进行计算,并向其他神经元传递消息。这也是我们的感觉和肌肉运转的原理。如果你想活动一块肌肉,就会触发一个神经元给你的肌肉发送脉冲,并引起你的肌肉收缩。如果一些感官:比如说眼睛想要给大脑传递一个消息,那么它就像这样发送电脉冲给大脑的。
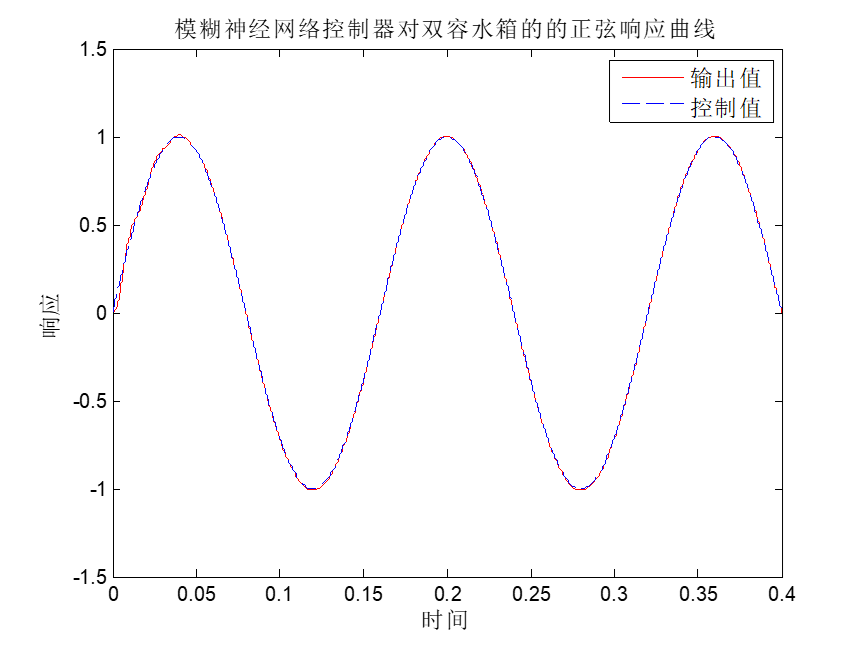
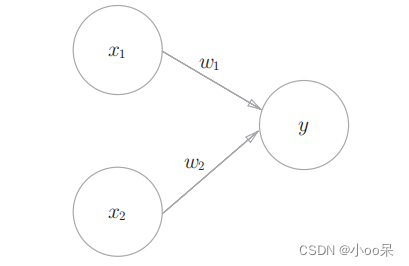
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。

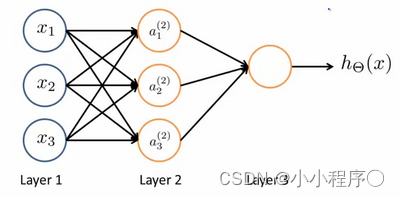
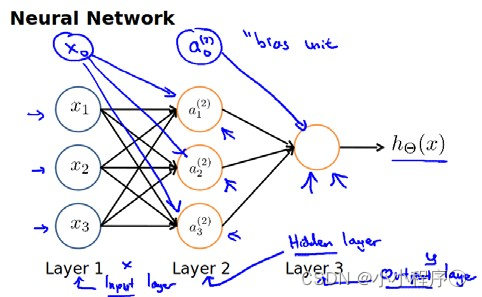
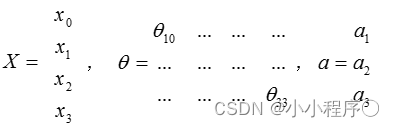
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。