本文介绍: 看到的这个开源的大模型,很牛,~关键让我们自己也可以部署体验一把了,虽然不知道具体内部怎么构造的但是,也可以自己使用也挺好.安装以后,是可以使用python代码进行提问,然后返回结果的,这样就可以实现我们自己的chat应用了,这个已经有这个模型了,自带的,当然也可以自己去下载最新的安装,这个模型其实就是62亿的训练数据.可以看到安装的需求,如果自己没有那么高的显卡配置可以,用CPU安装,但是配置也需要高一些。当然也可以使用我们自己的数据集,让这个算法进行自动学习和微调,然后来做预测,但是。
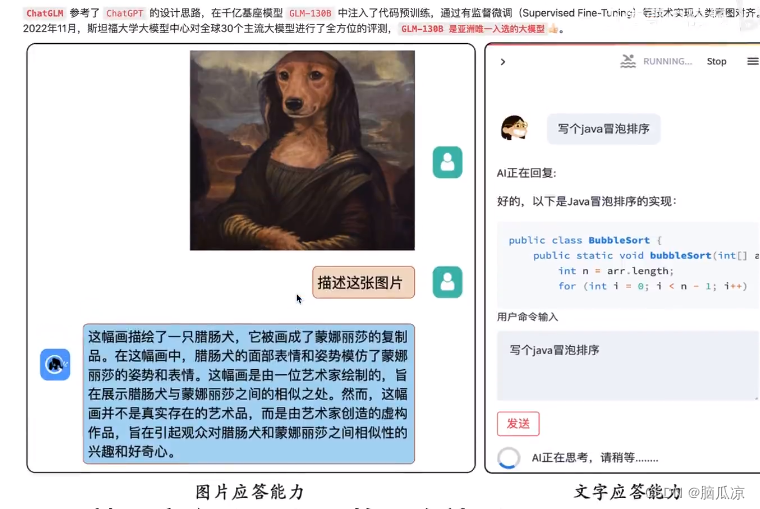
看到的这个开源的大模型,很牛,~关键让我们自己也可以部署体验一把了,虽然不知道具体内部怎么构造的但是,也可以自己使用也挺好.
安装以后,是可以使用python代码进行提问,然后返回结果的,这样就可以实现我们自己的chat应用了,
非常不错.但是毕竟是6B 现在已经是130B了,但是那个模型是不开源的
当然也可以使用我们自己的数据集,让这个算法进行自动学习和微调,然后来做预测,但是
这样的话需要我们自己去整理数据集,这部分需要看相关的部署和微调的教程.
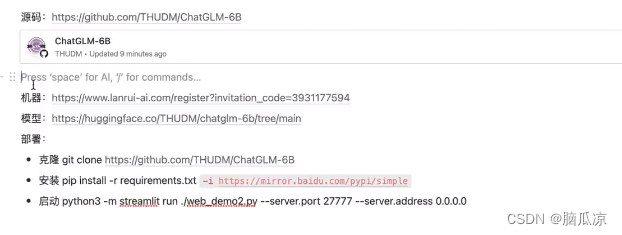
https://chatglm.cn/bloghttps://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e这里也有详细的部署和微调

原文地址:https://blog.csdn.net/lidew521/article/details/134661442
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_4969.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。