导读
本文将主要介绍BEV+Transformer端到端感知与建模技术在高德各项业务中的应用,如高精地图中地面要素(包含线要素和地面标识)自动化上的具体方案及其演化过程。该方案使用BEV+Transformer技术来实现采集车上不同传感器(包含激光和相机)所得数据在空间和时间层面上信息的融合,以及对采集道路上各地面要素的感知与建模。这些技术手段很好地服务于地图中地面要素的产线需求,为高德地图提高地图制作效率,降低制作成本提供了坚实的技术保证。
一、业务分析
本文将以高精地图为例,分析其核心应用及其存在的挑战。高精地图作为自动驾驶技术发展的重要支撑和基础,可以提高自动驾驶车辆的感知能力、决策能力和控制能力,从而提升自动驾驶的安全性、可靠性和舒适性。目前高精地图中的地面要素主要包含线要素和地面标识两个大类,其中线要素包含车道线和道路边界,而地面标识则包含道路上的各类交通标识,如引导线,斑马线等。对于自动驾驶而言,线要素和地面标识均可用于自动驾驶车辆的定位,而线要素同时也可用于自动驾驶车辆的路径规划。在高精地图各地面要素的制作过程中主要面临两大挑战:更高的位置精度要求和地面要素本身的识别难点。下面本文将针对这两个挑战分别展开叙述。
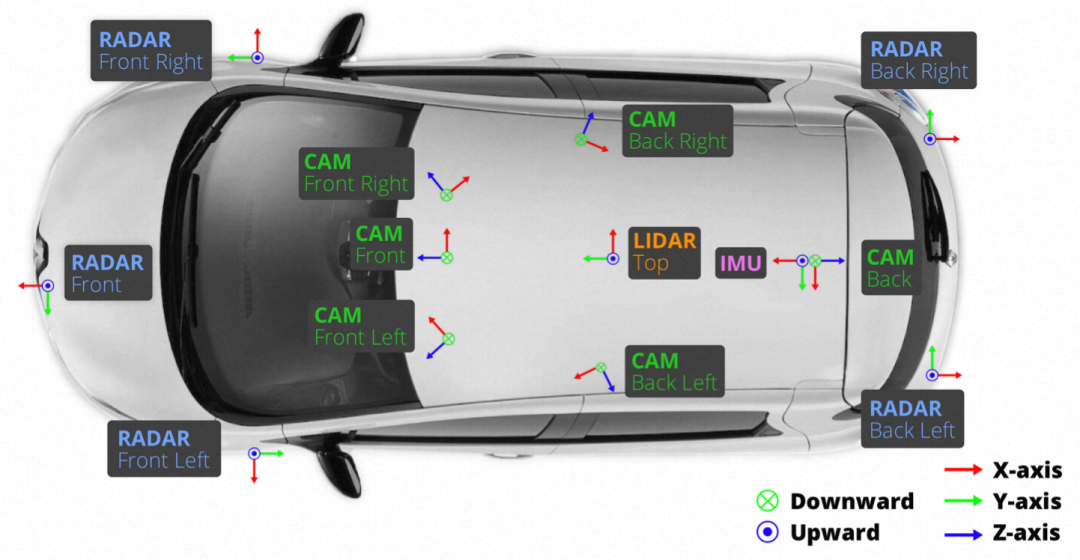
首先是高精地图自身所带来的位置精度挑战。近年来,随着自动驾驶技术从L2往L4方向的推进,对其安全性和可靠性的诉求也逐渐升高。高精地图作为自动驾驶中重要的一环,自动驾驶厂商对高精地图中各要素的位置精度均提出了极高的标准,各地面要素的精度都至少有着厘米级的要求。这种更高的位置精度要求,是高精地图相较于普通地图最大的区别,同时也使得其制作过程有着更大的困难和挑战。为了应对这一挑战,高精采集车配备了多种传感器,其中激光传感器用于采集道路上的点云数据,相机传感器用于采集道路上的图像数据。下图展示了Nuscenes数据集采集车设备安装方式以供参考,并非高精车设备实际安装方式:
其次是高精地图中地面要素本身的识别难点。正如上文所述,地面要素包含线要素和地面标识,它们自身种类繁多,且在内容,形状和尺寸上均存在较大差异,这为感知模型得到全而准的结果带来了识别难度。此外,采集所得数据中包含的地面要素往往存在较多磨损和遮挡的情形,主要原因有两个:一个是地面要素因长年未修,本身存在磨损,另一个是采集过程中,由于遮挡,环境改变等因素会导致激光的反射率存在差异或可见光不清晰等情形,进而导致采集得到的点云数据和图像数据的质量参差不齐。下图分别展示了激光采集过程中点云磨损的情形,以及相机在隧道里采集时图像不清晰的情形:

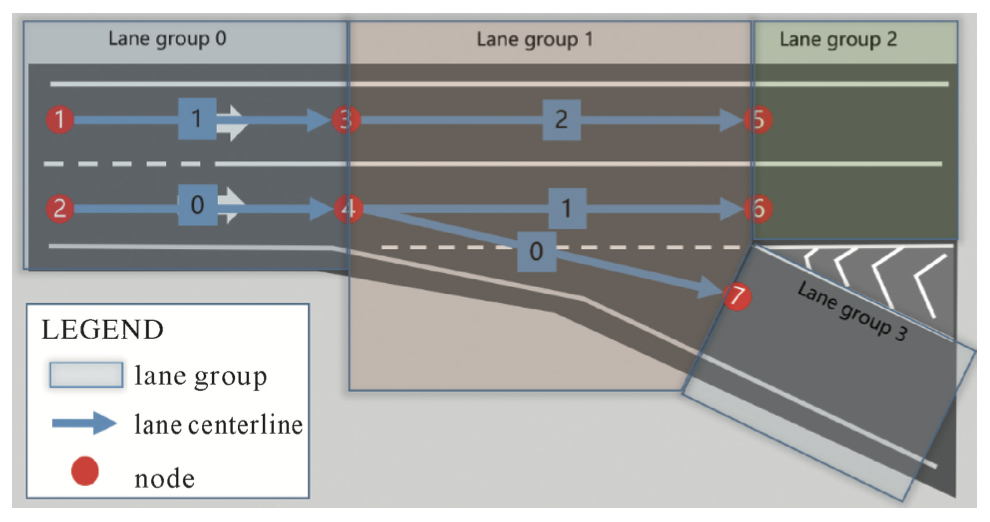
此外,不同于地面标识在局部区域内独立存在,线要素在跨局部区域之间还存在关联关系,高精地图需要构建线要素的全局拓扑,并对线要素属性变化以及几何变化处进行打断,如下图所示。因此如何保证线要素在跨局部区域之间的平滑性并获取线要素精确的属性变化位置是更好的构建全局拓扑的重要一环。
为了应对这些挑战,本文引入BEV+Transformer技术来融合多传感器的数据并实现采集道路上各地面要素更鲁棒的感知和建模,具体细节将在下文给出。
二、BEV+Transformer技术概述
高精地图中地面要素的制作需要准确的感知和建模采集车采集区域的道路信息和布局以及完整的车道结构,在人工作业的过程中,通常会在一种自上而下视图(鸟瞰图,BEV)上完成,因为高度信息不太重要。因此,对地面要素的感知和建模天然适合在BEV空间下进行,也能更好的保证所得感知结果的精度。本文将介绍一套基于BEV的地面要素感知方案,通过视角转换将图像数据和点云数据投影进一个统一的BEV空间内,完成对多传感器数据信息的融合和特征的提取,并得到高精度的地面要素感知结果。下图展示了将点云数据和图像数据投影进BEV空间后的效果图:

本文涉及的第二个主要技术叫做Transformer技术,它是一种基于注意力机制(Attention)的神经网络模型,通过Query向量与Key向量和Value向量的交互融合,来挖掘不同特征间的联系及相关性。
Transformer技术问世后,先在自然语言处理领域大放异彩,之后又被逐步移植到计算机视觉任务上,也取得了惊人的效果,在目前的大模型时代,逐渐实现了NLP和CV在建模结构上的大一统。在本文中,Transformer技术将被用于视角转换,特征融合和实例感知等多项任务,帮助构建一套统一的地面要素感知模型。
三、技术方案构建及演化
本文构建的地面要素感知+建模技术方案主要包含三个模块:局部地面要素感知模块,全局线拓扑建模模块和线要素属性变化点模块。局部地面要素感知模块用于得到线要素和地面标识的局部感知结果,其中线要素将进入下游的全局线拓扑建模模块和线要素属性变化点模块,得到最终的全局拓扑结果。
局部地面要素感知模块
为了通过采集车采集得到的点云数据和图像数据生成全而准的地面要素矢量结果,本文构建了一套基于BEV+Transformer的点图融合地面要素感知模型,其整体技术框架及其演化主要包含三部分:
1. GroundElement2Former
面向单传感器的地面要素感知模型主要针对单点云数据或单图像数据进行处理,来获取其中包含的地面要素矢量结果。具体流程如下:1. 对点云数据或图像数据进行空间转换和特征提取来获取其在BEV空间下的特征;2. BEV特征再通过下游的分割模型获取实例分割结果;3. 通过后处理方式将实例分割结果转化为矢量结果。
首先是空间转换和特征提取模块。单点云数据通过2D/正交投影得到点云栅格图来作为其在BEV空间内的表现形式,将点云栅格图作为模型的输入来得到BEV空间下的特征向量。单图像数据则通过IPM投影完成从透视空间(PV空间)到BEV空间的转换,并将转换后的数据作为模型的输入来得到BEV空间下的特征向量。然而不同于点云数据,图像数据在IPM投影的过程中,需要使用几何先验:地面平坦假设,即假设当前路面是平坦的,没有高度变化,但在现实世界里,这一条件往往很难满足。
因此GroundElement2Former模型中的PV2BEV模块使用Transformer技术和通过点云得到的地面高度值来弥补IPM投影过程中的这一问题,实现图像数据往BEV空间的精准映射。具体如下:设置BEV Queries作为Query向量,通过Deformable Attention机制交互融合PV特征,从而得到BEV特征。
在进行Deformable Attention的过程中,首先通过点云得到的地面高度值来作为更精准的初始地面高度值,其次学习初始地面高度值往真实地面高度值的偏移量,来完成更精准的IPM投影。最后,本文还使用了InternImage大模型和Adapter技术,来提取表征能力更强,更鲁棒的BEV特征。
其次是实例分割模块。在得到BEV特征后,本文使用Mask2Former结构来进行实例分割,通过instance queries在BEV特征上交互融合来提取各地面要素实例信息,具体结构如下所示:
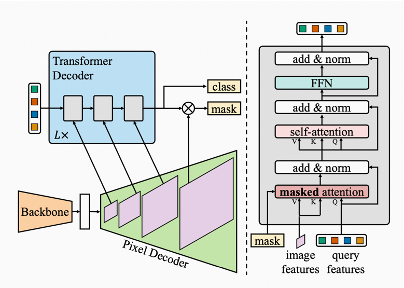
其中,Mask2Former中提出的Masked Attention机制可以很好的缓解Cross Attention上存在的搜索空间大,收敛慢的问题,帮助GroundElement2Former模型更好的分割出各地面要素实例。
最后是后处理模块。对于线要素,高精地图一般采用NDS格式存储,即将线要素保存成矢量点形式。因此,本文使用骨架提取算法,将得到的线要素实例分割结果骨架化为矢量点。对于地面标识,高精地图一般采用OBB格式存储,即将地面标识保存为包含地面标识的最小矩形框所对应的矢量点。因此,本文在使用cv2.minAreaRect获取实例分割对应的最小外接矩形后,通过cv2.boxPoints获取该矩形的四个顶点坐标作为存储的矢量点。下图从左到右分别展示了模型得到的实例分割结果和经过后处理后得到的矢量点结果:

本文提出的GroundElement2Former模型虽然可以有效的获取单传感器所得数据中的地面要素矢量,但正如上文所述,单传感器采集数据中由于环境因素,存在质量参差不齐的现象。而当前模型缺乏将多传感器信息融合的能力,这就导致模型的感知性能极度依赖单一传感器所采数据的质量。
2. Fusion-GroundElement2Former
为了缓解由于环境因素导致的单一传感器失灵的现象,本文将GroundElement2Former升级为面向多传感器融合+时序融合的感知模型Fusion-GroundElement2Former。通过融合多传感器所得数据和多帧数据中包含的信息,来保证模型可以更稳定的感知出地面要素结果。相比于GroundElement2Former,Fusion-GroundElement2Former新增了两个模块:Cross-Sensor Fusion和Offline Temporal Fusion,其中Cross-Sensor Fusion模块通过Deformable Attention机制来对齐和融合多传感器信息,Offline Temporal Fusion模块则通过仿射变换来实现多帧信息的融合。
对于Cross-Sensor Fusion模块,多传感器所得数据投影到BEV空间上后可能存在不对齐现象,因此本文类比PV2BEV模块,为点云数据和图像数据设置一个统一的BEV Queries ,通过Deformable Attention机制交互融合图像特征和点云特征,从而得到BEV特征,并使用Deformable Attention中学习offset的机制来实现两种数据的对齐。
对于Offline Temporal Fusion模块,融合当前帧的前后帧信息可以有效地缓解因遮挡场景导致的模型感知不稳定的问题。不同于继承式的时序融合方式,本文使用仿射变换和特征拼接策略来作为时序融合的方式,具体方法是:对于当前时刻的BEV特征,对于其周围时刻的BEV特征,先根据时刻到时刻的仿射变换矩阵来将其对齐进当前时刻上得到,然后把对齐后到多帧BEV特征和当前时刻的BEV特征在channel维度上进行拼接来作为时序融合后的BEV特征。
这种时序融合方式不仅可以融合更久远的信息防止遗忘,也可以为离线高精建图解除无法利用未来帧信息的限制。
通过上述新增的两个模块,Fusion-GroundElement2Former可以更好的应对单传感器单帧数据质量差的场景,得到更全更稳定的地面要素感知结果。
3. Fusion-SmoothGroundElement2Former
造成线要素全局关联不平滑的一个主要原因是线要素在局部区域的感知结果存在不稳定现象:对于某些磨损车道线,可能存在上一帧给出感知结果,但当前帧又丢失其感知结果的情形。为了得到更稳定的线要素感知结果,在关联局部区域的线要素后,可以得到更平滑且准确的线要素全局拓扑。本文在最后介绍一种时序感知一致性约束,将Fusion-GroundElement2Former进一步升级为Fusion-SmoothGroundElement2Former来提升线要素跨局部区域的平滑性,保障全局拓扑的顺利构建。
本文将线要素的全局拓扑构建视为一个一阶马尔可夫链的过程,第帧的感知结果需要依赖于帧的感知结果,从而保证两帧之间感知结果的一致性。因此,本文设计将上一帧的感知结果投影到当前BEV空间内,并编码为Mask Prompt ,与当前帧的BEV特征融合进入下游的Mask2Former分割模型中,获取当前帧感知结果:
通过这一约束来减少线要素在上一帧被感知出来,但当前帧丢失的情形。并通过上一帧线要素的感知结果约束当前帧线要素的感知,保证线要素在跨帧时的平滑性,防止其出现剧烈跳变。
全局线拓扑建模模块
为了构建线要素全局拓扑结果,本文构建了一套基于Attn-GNN的线要素关联模块和基于Diffusion Model的线要素平滑模块,其中线要素关联模块用于构建跨帧线要素之间的关联关系,构建完关联关系后通过线要素平滑模块提升关联合并后线要素的平滑性。下面做详细介绍。
1. 基于Attn-GNN的线要素关联模块
为了构建不同帧之间线要素的关联关系,本文将其视为了一个图匹配任务,使用图(Graph)结构对单帧线要素集合进行描述,其中每个线要素被编码为一个节点。因此线要素跨帧匹配可以被建模为输入两个Graph,输出节点间的匹配关系。
具体来说,对于上游Fusion-SmoothGroundElement2Former产生的线要素几何实例Queries和矢量结果。本文先对矢量信息进行编码并和几何实例Queries特征连接作为节点的特征向量,并通过Graph内部的Self Attention以及互相之间的Cross Attention获取各节点交互后的特征。其中Self Attention的目的是使得网络能够对同帧之间的矢量进行更好的区分,一个典型的场景是路面上包含密集的车道线,各自车道线位置差异较小,很容易造成匹配错误,Self Attention可以使模型编码出更具区分性的节点特征。Cross Attention的作用则是在将不同帧的线要素的特征进行交互,使关联的线要素特征具有更高的相似度。最后通过Skinhorn算法构建线要素之间的匹配关系。具体效果如下图所示:

2. 基于Diffusion Model的线要素平滑模块
完成上一步的局部线要素矢量匹配后,下一步需要将不同帧的矢量结果进行连接形成最终的线拓扑,常规的按照规则的连接方式在复杂场景难以起效,比如当局部感知存在偏差时连接后的线拓扑会存在不平滑问题等,如下图所示:

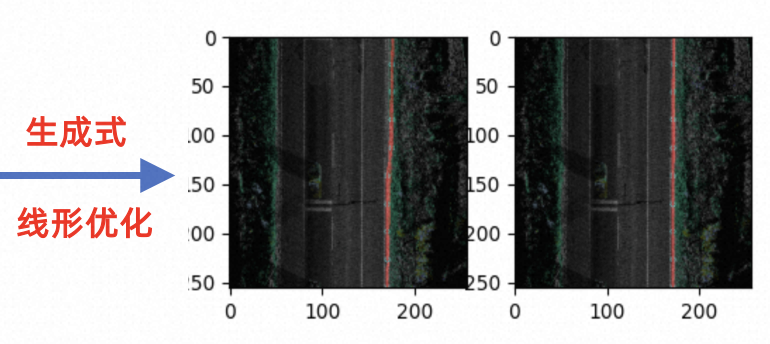
因此线要素平滑模块主要侧重于对连接后的线拓扑结果进行优化,本文使用PolyDiffuse算法针对潜在的错误场景进行重生成,以解决感知和连接阶段造成的歧义和逻辑问题。其核心思想为利用带监督的diffusion生成能力,结合语义特征对前序输出进行二次生成操作,解决复杂场景矢量逻辑问题。
具体来说,在diffuse阶段,扩散网络的加噪和降噪过程中充满不确定性,但HD矢量具备唯一性约束。为了达成这一约束,首先需要基于输入的矢量训练一个指导网络以使得其具备唯一表示且可以和其他矢量区分开,因此在指导网络中会将每个矢量作为一个独立高斯分布来作为目标分布进行学习。在reverse阶段,每个矢量会初始化为指导网络学习出的高斯分布,且结合该区域的语义特征进行降噪来重建得到优化后的结果。对于线要素拓扑的矫正效果如下所示:

线要素属性变化点模块
最后,为了获取线要素属性变化点的精准类别和位置,本文也构建了一套基于线要素局部感知和Deformable Attention的属性变化点检测模型。下面对该方案做简要介绍:
对于上游Fusion-SmoothGroundElement2Former产生的线要素几何实例Queries,使用全连接网络将每个几何实例Query拆分成多个属性变化点Queries,来预测对应线要素的属性变化点。通过这种方式可以构建属性变化点和线几何之间的对应关系,完成变化点与线之间的绑线操作。具体来说,将这些属性变化点Queries经过Deformable Attention来融合BEV特征,从而获取变化点坐标偏移量(每一层decoder layer迭代更新变化点坐标)和变化点上下类别。得益于变化点位置的迭代过程,端到端属性变化点回归方案可以实现20cm精度的属性变化点位置识别。
四、效果分析与结论
局部地面要素感知效果分析
本文给出简单场景和复杂场景两类情形下Fusion-SmoothGroundElement2Former的感知结果,来展示其拥有准确且鲁棒的感知能力:
在简单场景下,采集得到的点云数据和图像数据均比较清晰,且道路上遮挡物较少,感知模型对于地面各要素的识别难度较低,Fusion-SmoothGroundElement2Former给出了全而准的感知结果。
在复杂场景下,采集得到的点云数据存在磨损现象,且图像数据中存在大量被车辆遮挡的情况,感知模型对于地面各要素的识别难度较高,但Fusion-SmoothGroundElement2Former在结合了多传感器的信息后仍能给出全而准的感知结果。
全局线拓扑建模效果分析
其次,本文也给出了局部线要素在经过下游全局线要素拓扑建模模块后得到的全局拓扑结果,来展示本文提出的完整框架的建模能力,具体如下图所示:
可以发现在接入线要素关联和排重模块后,可以得到一个平滑且完整的全局线要素拓扑结果。此外,本文也测试了单图像源的全局建模结果,如下图所示:
受限于相机的拍摄范围,部分道路在相机上不可见,但即使在只使用纯图像信息的情况下,本文提出的框架也可以构建一个较为平滑且部分完整的拓扑结构。
多传感器融合定位效果分析
最后,本文也将Fusion-SmoothGroundElement2Former模型拓展进定位场景中,下图展示了本文提出的BEV感知方案在定位场景下的效果:
可以发现Fusion-SmoothGroundElement2Former也可以很好的服务于城市道路场景的定位相关的需求,在横向0.2m纵向1m的要求下,可以达到99%+的定位准确率,证明了其拥有着广泛的应用场景。
五、展望
目前这整套BEV地面要素感知模型不仅服务于高精地图的地面要素自动化上,还服务于多传感器融合定位等项目,结合目前已知的应用场景,现在的方案仍会遇到很多挑战,因此需要对现有方案进行能力扩展以应对这些未来的新挑战。具体来说,地图业务会涉及道路上的各类事项,其包含的道路任务十分多样,涉及的道路要素品类繁多,且几乎不可遍历。随着业务场景的不断拓宽,势必需要不断对新的道路品类构建感知能力且需要提供除感知外的其他能力,如定位&建图等。未来将会把Fusion-SmoothGroundElement2Former框架逐步扩展成面向通用道路场景的Uni-Road-Perceiver大模型,Uni-Road-Perceiver从业务诉求出发,通过感知大模型构建数据闭环,并系统解决道路场景下所有感知问题以及为下游各项任务,包括且不限于定位&建图,提供感知能力的支撑。
推荐阅读
原文地址:https://blog.csdn.net/amap_tech/article/details/134796988
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_#ID#.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




![[全连接神经网络]Transformer代餐,用MLP构建图像处理网络](https://img-blog.csdnimg.cn/direct/bde5b15bef464542b6efbbfb84b05d86.png)
