诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:How Can We Know What Language Models Know?
ArXiv网址:https://arxiv.org/abs/1911.12543
官方GitHub项目(prompt之类的都有):https://github.com/jzbjyb/LPAQA
本文是2020年TACL论文,作者来自卡耐基梅隆大学和博世北美研究所。
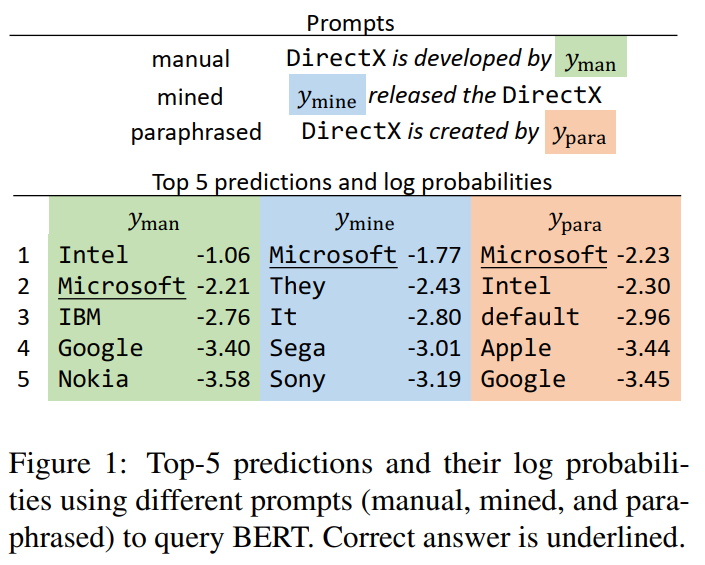
本文关注探索LM中蕴含的知识。以前已经有工作用完形填空的方式来探查知识(Obama is a __ by profession),但是这些填空模版(prompt)都是手工做的,因此可能是sub-optimal的(在上一篇论文最后也提及了),不能充分发挥LM的能力。
本文的解决方案是自动挖掘prompt(远程监督、回译、集成)
1. 探查知识的方案

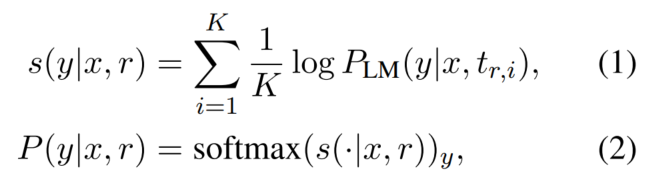
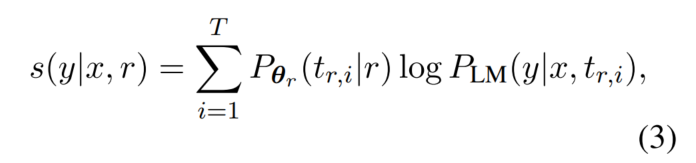
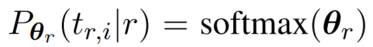

2. 实验
1. 数据集
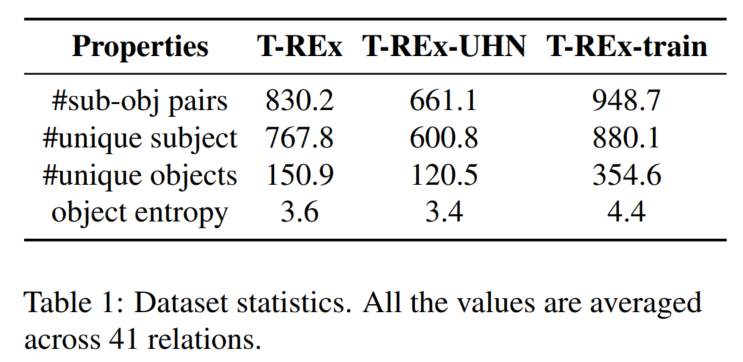
2. LM
3. baseline
4. 实验设置
5. 主实验结果
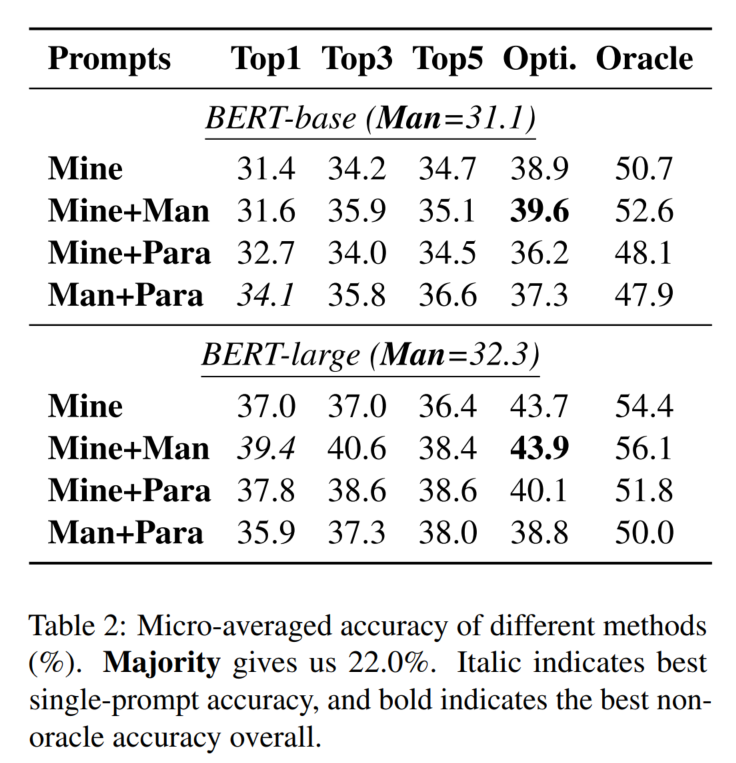
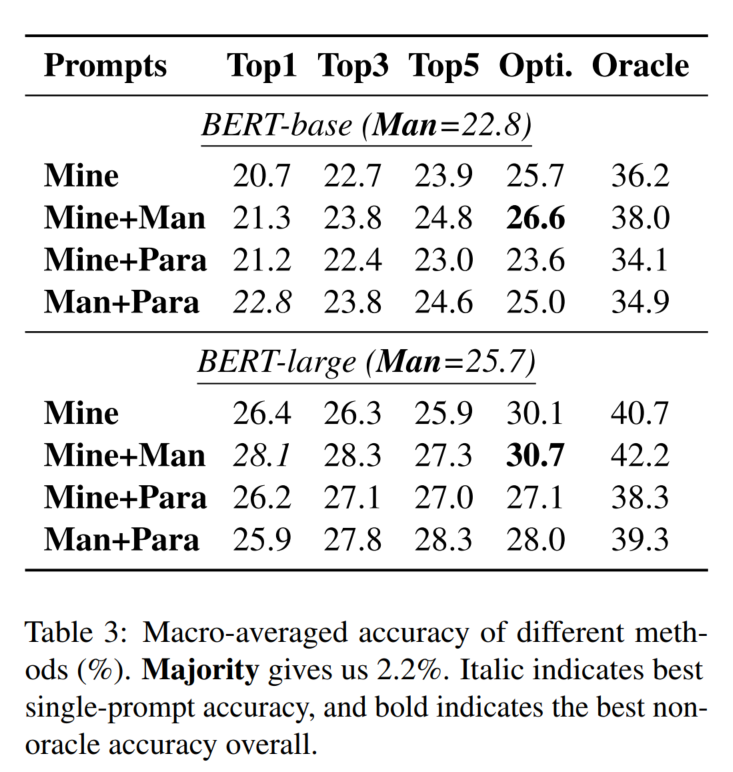


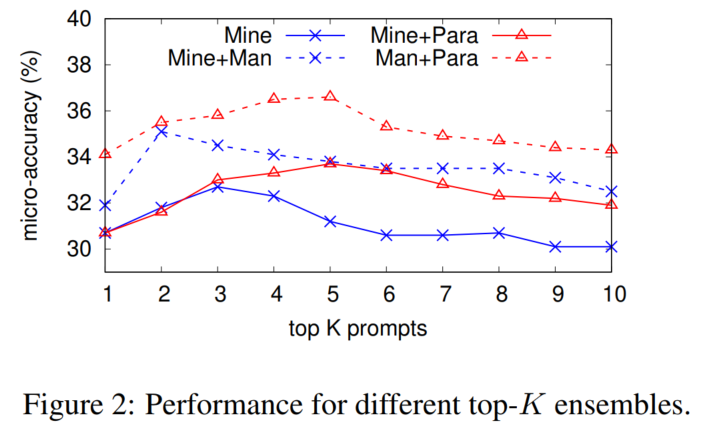

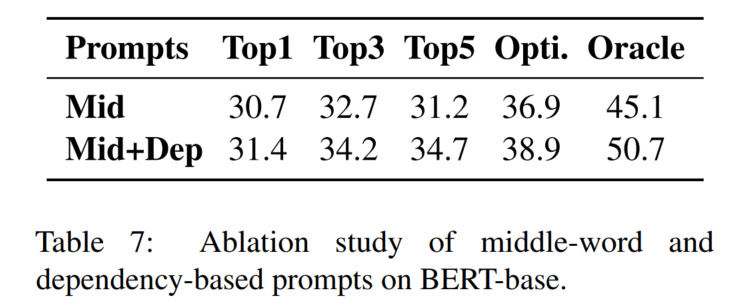
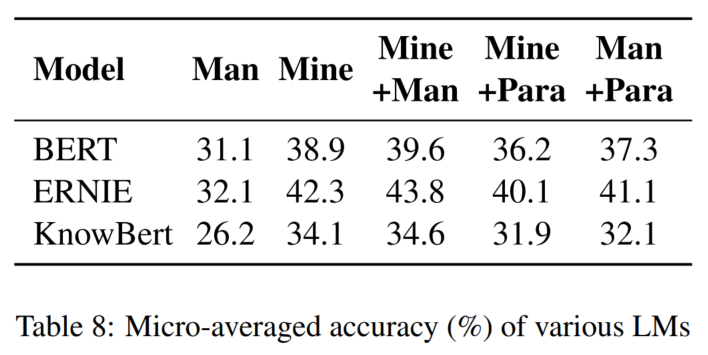
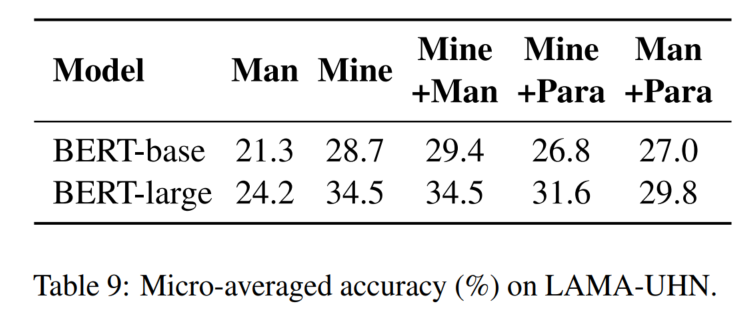
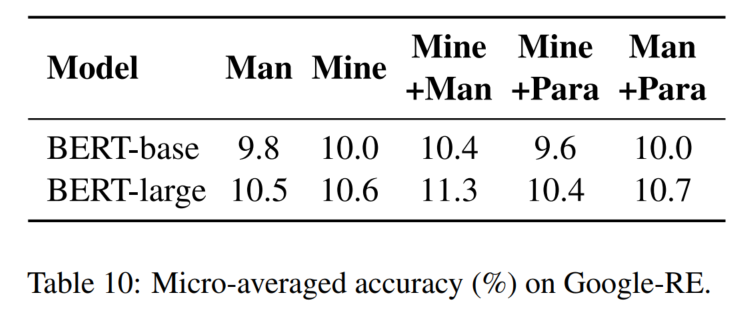
6. 实验分析
Prediction Consistency by Prompt
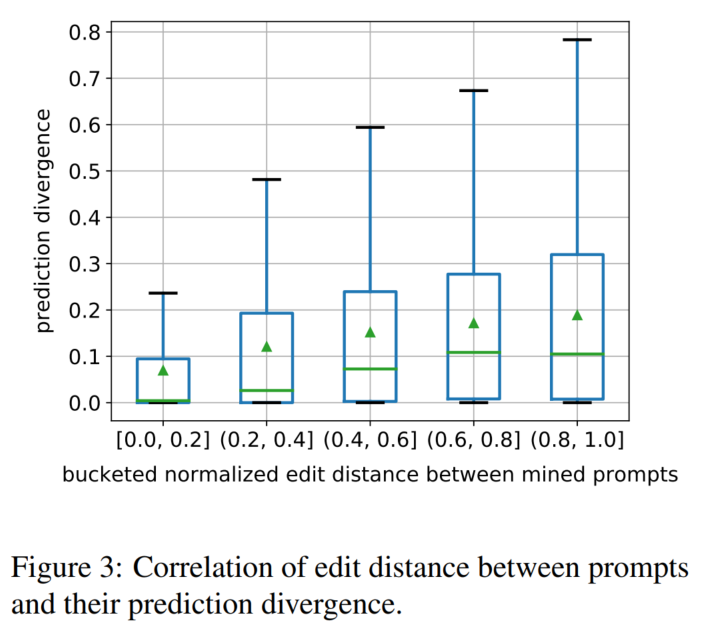
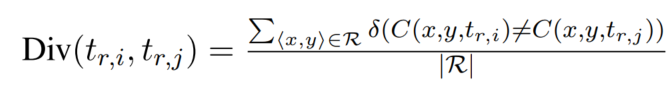
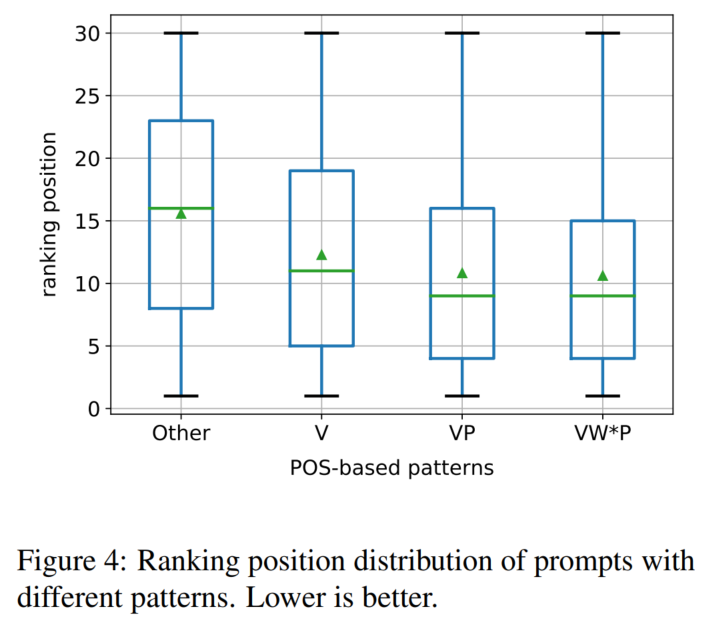
POS-based Analysis

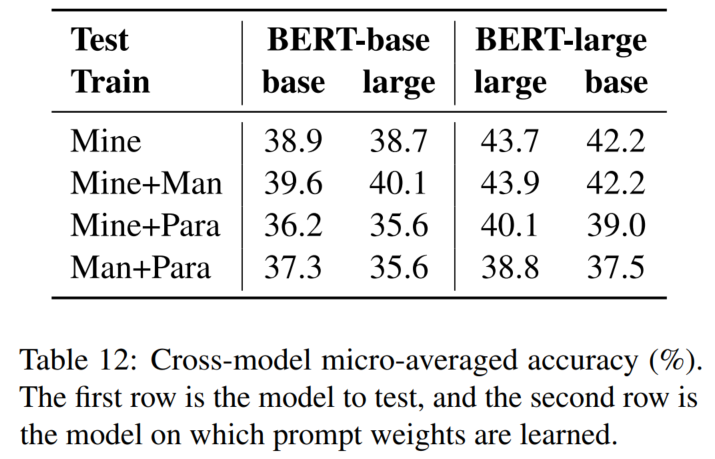
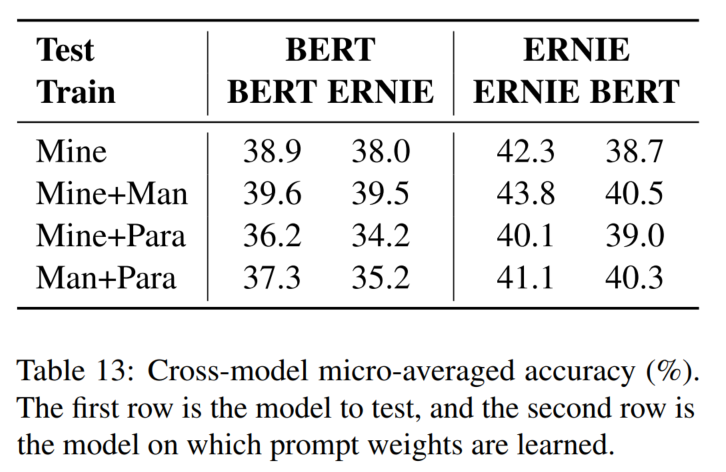
Cross-model Consistency
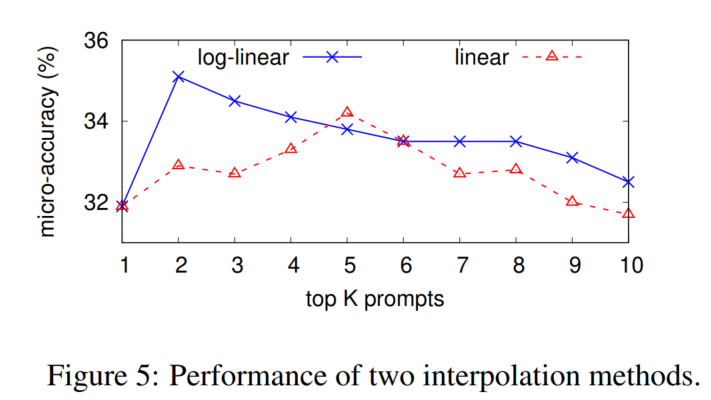
Linear vs. Log-linear Combination
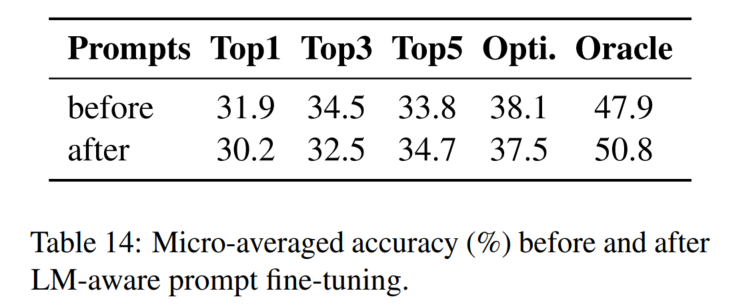
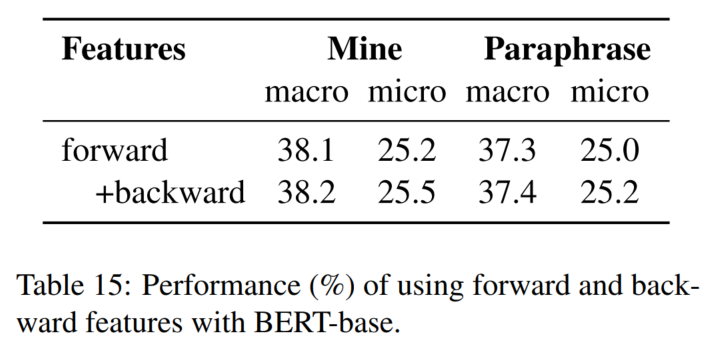
7. 失败trick集合
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





