本文介绍: 输出:将更新时间在2022年10月1日到31日之间的文件下载到本地目录(可配置),并将下载的标题列表逐行打印在控制台console中。输入:用户输入下载时间范围,格式为2022-10。要求:获取下图指定网站的指定数据。
要求:获取下图指定网站的指定数据
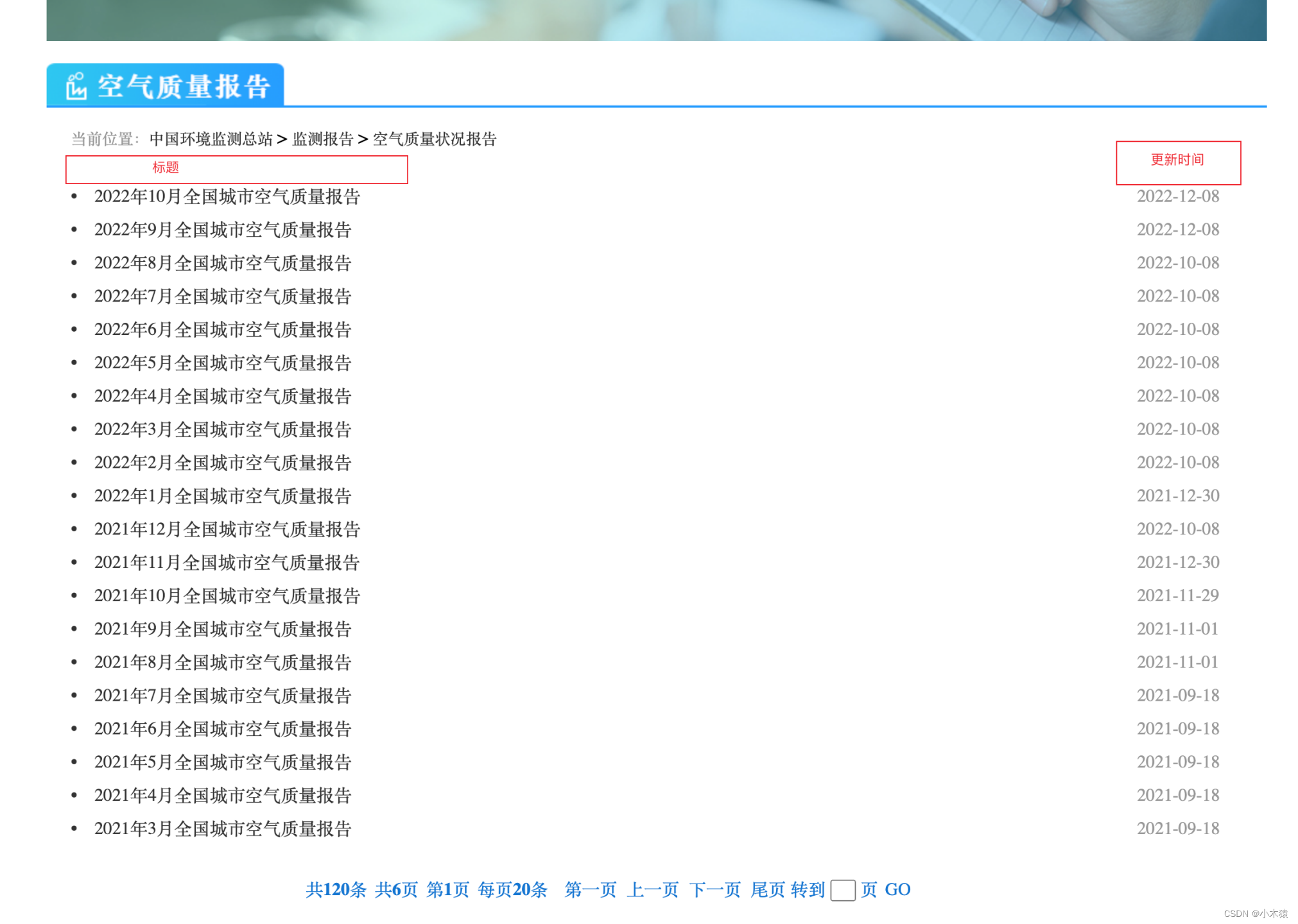
输出:将更新时间在2022年10月1日到31日之间的文件下载到本地目录(可配置),并将下载的标题列表逐行打印在控制台console中
完成标准:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)