前言
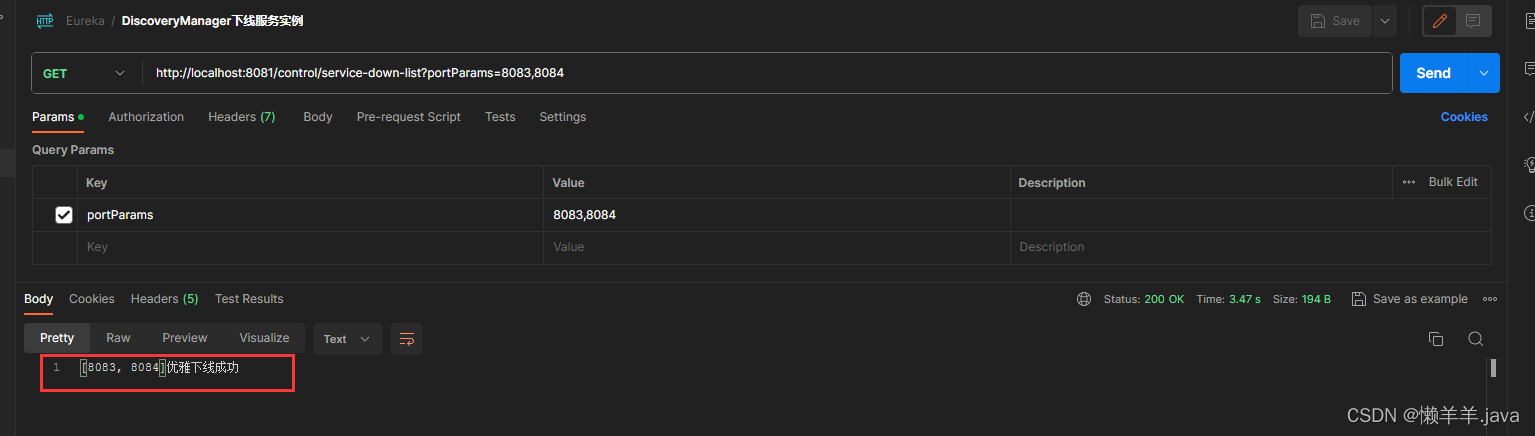
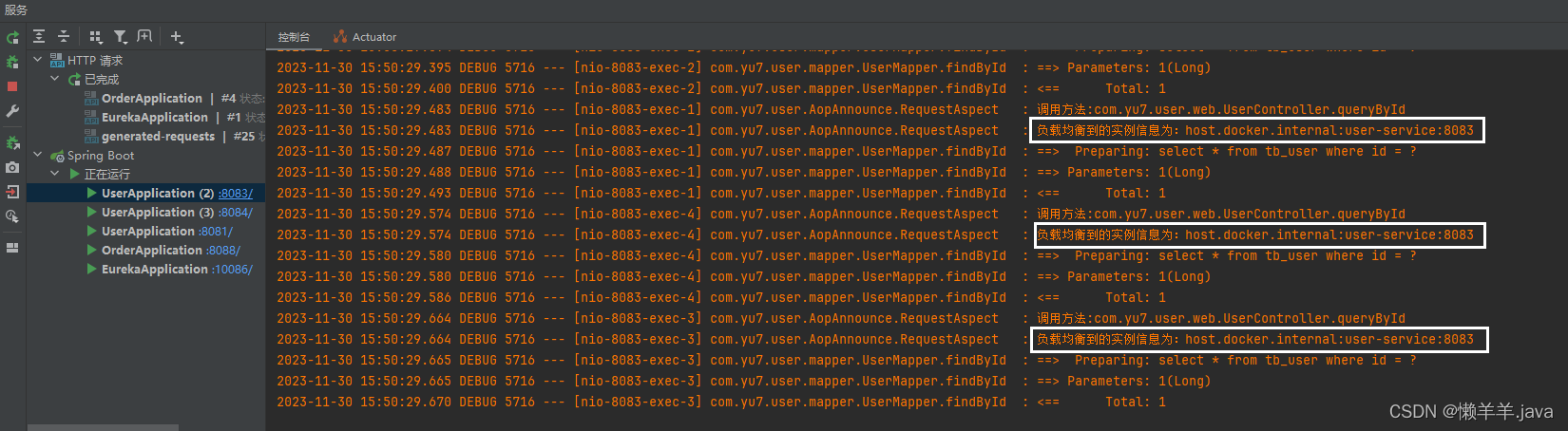
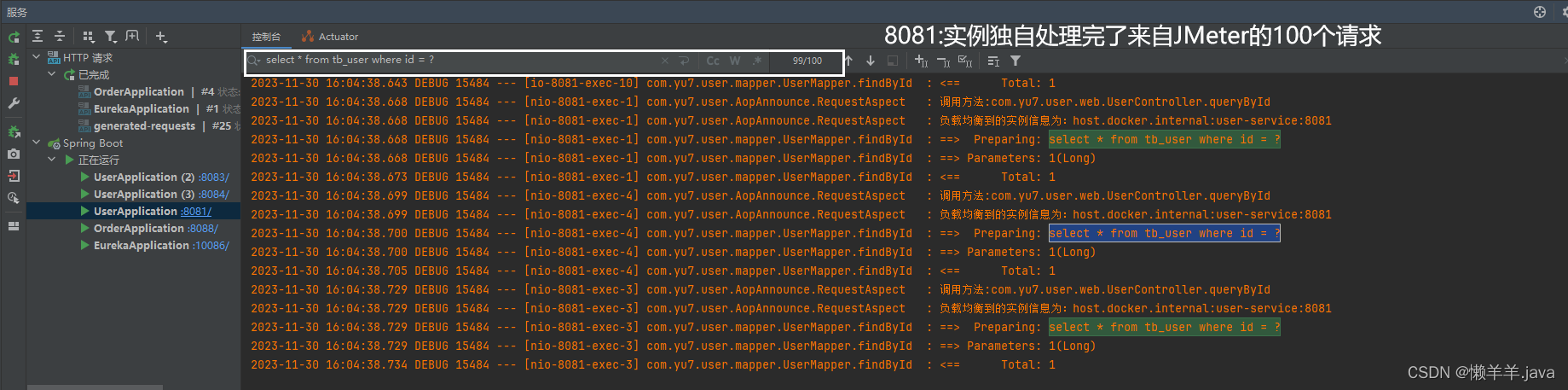
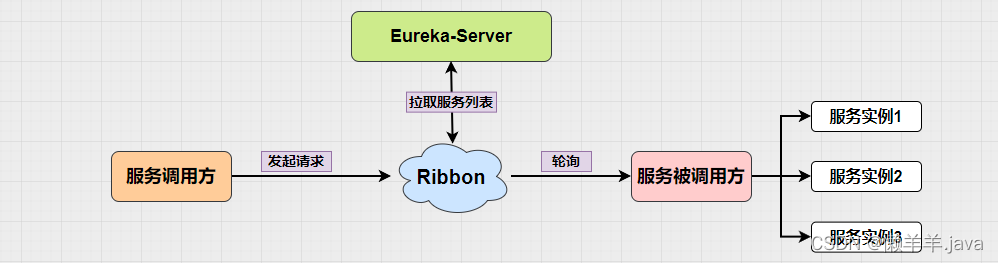
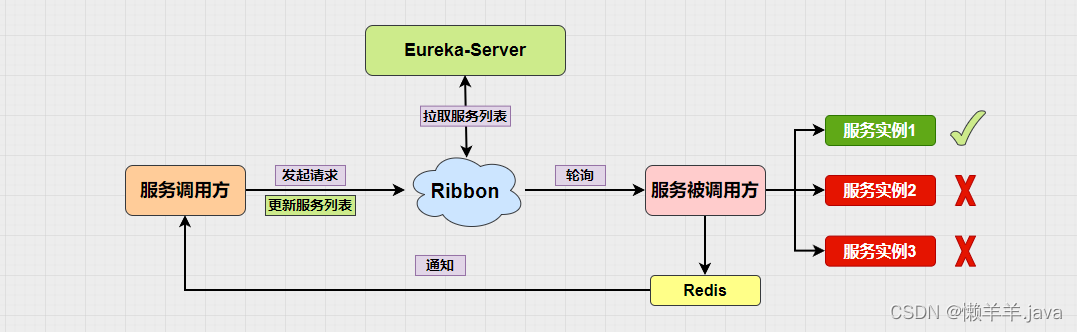
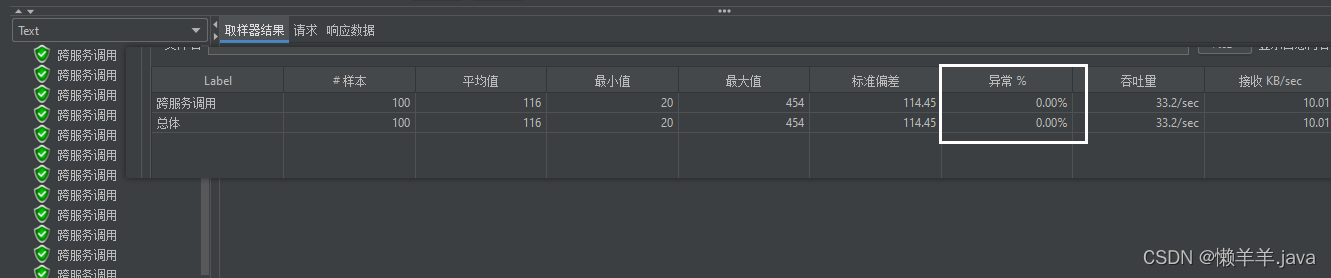
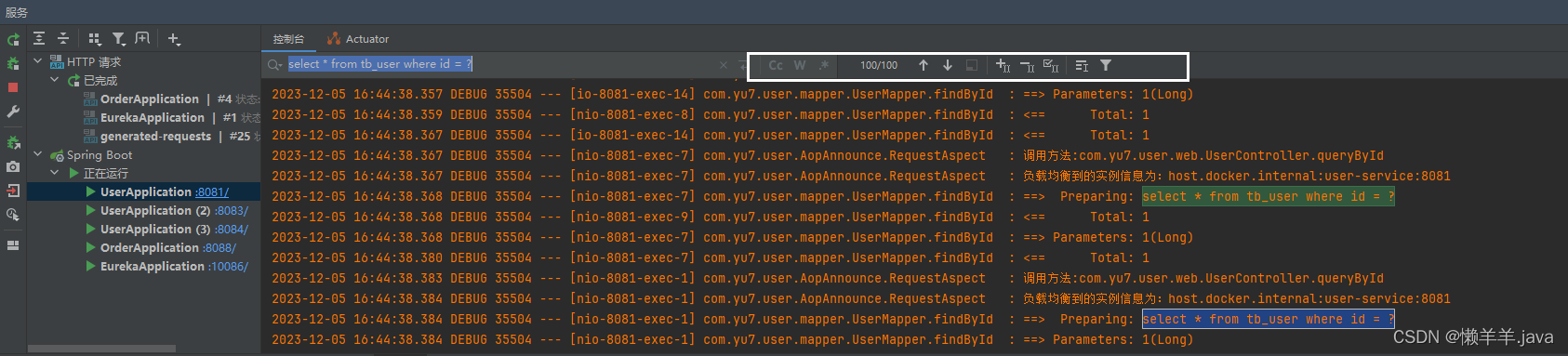
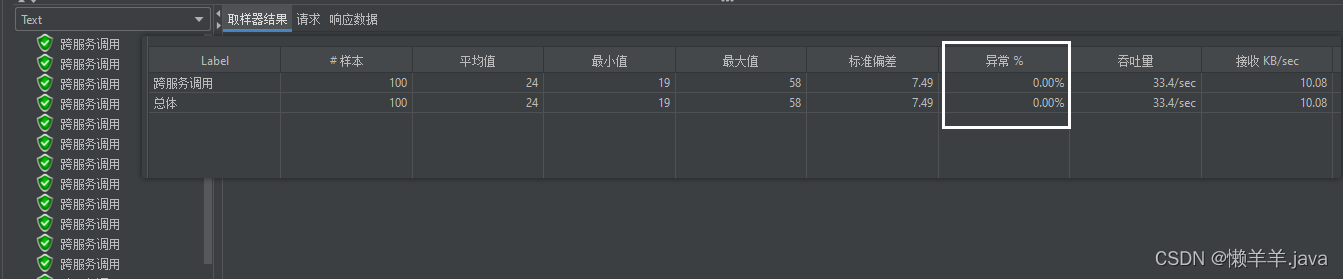
在上文的基础上,通过压测的结果可以看出,使用DiscoveryManager下线服务之后进行压测是不会出现异常情况的,但唯一缺点就是下线服务的方式是取消注册与续约,之后并没有结束进程。也就使得在调用api下线后的服务其实是还存在处理请求的能力的。加之eureka三种级别的缓存同步需要一定时间,Eureka-Client从三级缓存中拉取的并不是实时的服务列表,进而使得Ribbon从Eureka-Client拉取的也不是实时的服务列表。最终导致Ribbon负载均衡到了已经下线的服务实例,并且此时该实例(进程还未关闭)刚好能处理请求!就造成了下线了两个端口的服务实例,但是却还是被负载均衡到来处理请求!
按照这个思路,再去看这张图:
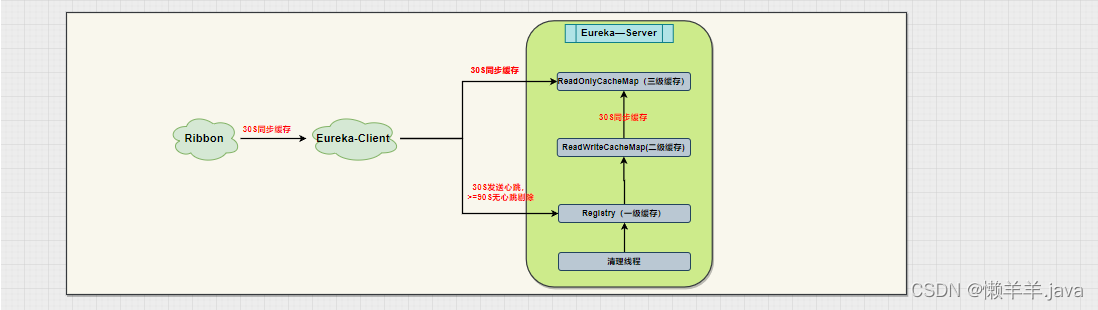
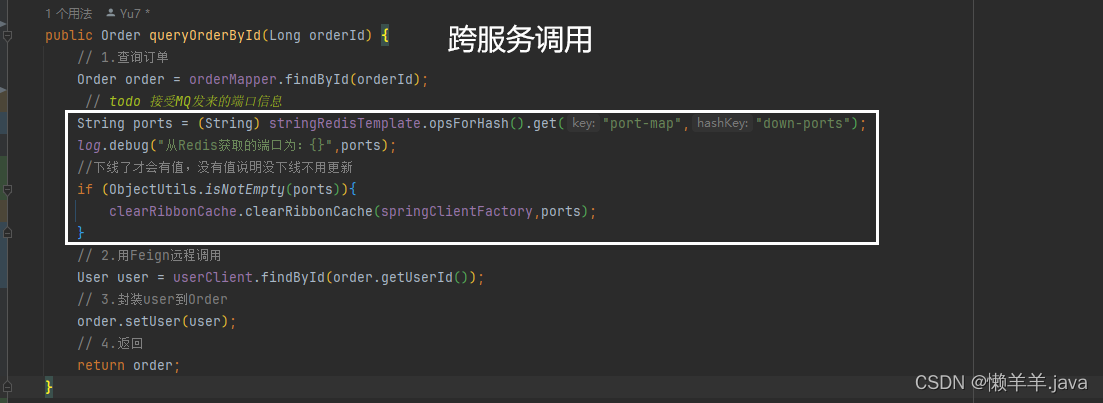
可不可以通过某种手段,当服务下线后去越过三级缓存直接去更新Ribbon缓存来缩短感知时间?
1.第一次尝试
1.1服务被调用方更新
在之前分析Ribbon源码的时候,说到了接口路径从http://服务名称/接口路径——>http://服务地址/接口路径,这个过程中调用方的请求被Ribbon拦截器拦截,并且通过负载均衡最终被改写成为了一个准确的服务地址,其中有一个非常重要的方法,getLoadBalancer(“服务名称”)
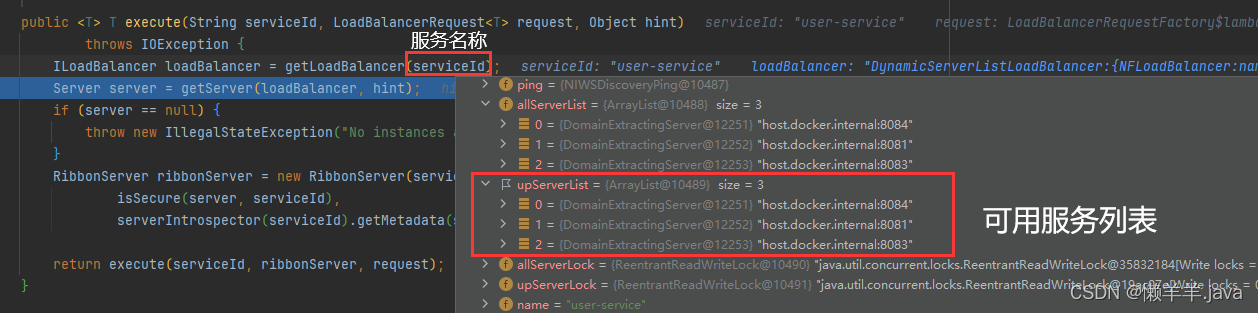
可见,他通过服务名称就拿到了该服务名称下的所有服务列表(allServerList)和可用服务列表(upServerList),我们通过这个操作可不可以直接获取到最新一手的可用服务列表并且手动去set进Ribbon的可用服务列表缓存里,让他不再去每过30S同步?
Tips:在我们的SpringCloud项目中有一个非常重要的组件SpringClientFactory是Spring Cloud中用于管理和获取客户端实例的工厂类。在这里面可以获取特定服务的负载均衡器(即ILoadBalancer)