个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【MySQL学习专栏】🎈
本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌

一、联合查询
多表查询基础操作
多表查询,顾名思义即根据多个表的数据进行一系列的查询操作,是不过这个操作比以往的单表查询更加的综合。
关于多表查询,我们就不得不提到笛卡尔积的概念。简单来说笛卡尔积是一种数学上的运算,描述了多表查询基本的执行逻辑。
任何两张表都可以进行笛卡尔积运算,但是如果这两张表之间没有任何关系的话,那么笛卡尔积运算出来的结果是没有意义的。笛卡尔积就是把两个表的记录按照排列组合的方式构成一个更大的表,笛卡尔积运算结果的列数就是就是原来两个表的列数之和;笛卡尔积的行数就是原来两张表的行数之积。
关于笛卡尔积的效率问题:笛卡尔积实际上是一个低效的操作,尤其是表的数据比较多的情况下,即使用多表联合查询时效率时非常低下的。
实际开发过程中使用联合查询一定要慎重,很多执行比较慢的sql都是这种不当使用多表查询操作引起的。。
需要我们关注的是,笛卡尔积计算出来的数据中不一定全部都是有效的,即有的数据合乎常理,有点数据就不一定合乎常理了(不合理就是笛卡尔积计算出来的数据不满足客观实际情况)。
为了解决上述问题,我们可以加上具体的条件(这个条件我们叫做连接条件)来保证笛卡尔积计算出来的结果是合理的。
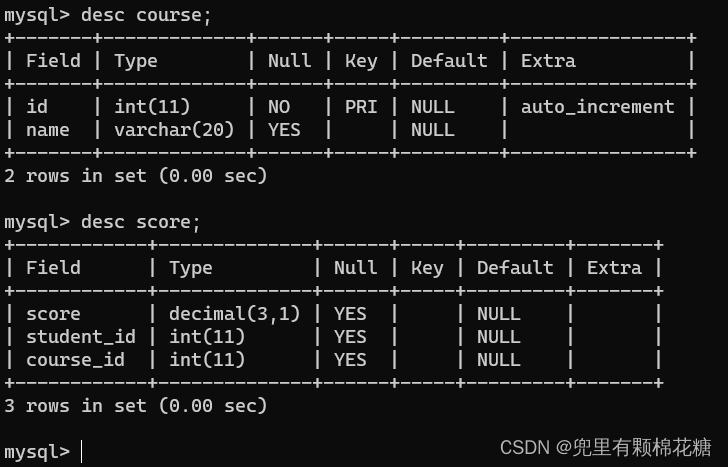
建表语句
create table student(id int primary key auto_increment,sn varchar(20),name varchar(20),qq_mail varchar(20),classes_id int) charset utf8;
create table classes(id int primary key auto_increment,name varchar(20),`desc` varchar(100)) charset utf8;
create table course(id int primary key auto_increment,name varchar(20)) charset utf8;
create table score(score decimal(3,1),student_id int,course_id int) charset utf8;
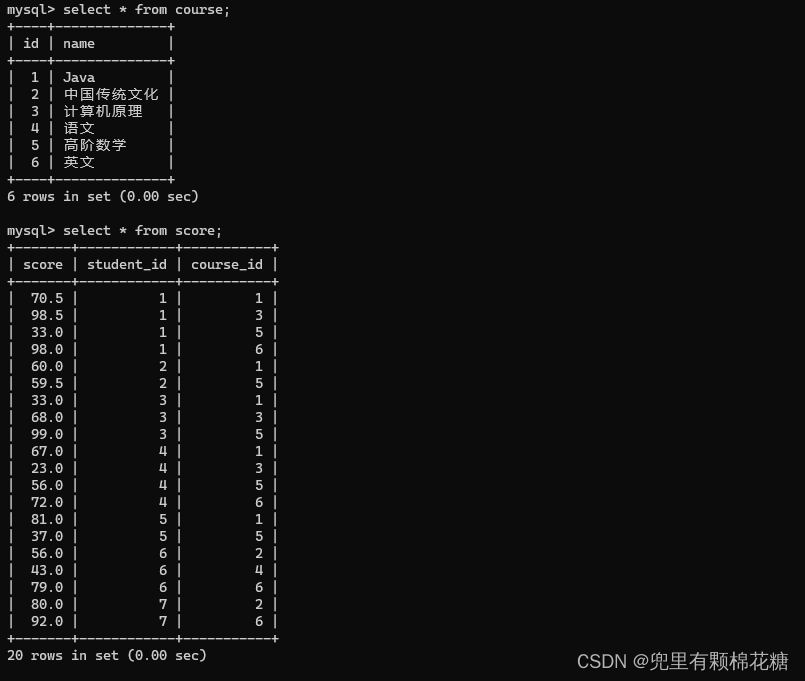
插入数据
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
(60, 2, 1),(59.5, 2, 5),
(33, 3, 1),(68, 3, 3),(99, 3, 5),
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
(81, 5, 1),(37, 5, 5),
(56, 6, 2),(43, 6, 4),(79, 6, 6),
(80, 7, 2),(92, 7, 6);
下面是上述表的结果和详情,请看:
下面为表的具体详细记录:
上述4张表,即student、classes、course、score可以构成一对多、多对多的关系。
一对多:student <=> classes
多对多:student <=> course
其中:score表相当于student表和course表的关联表

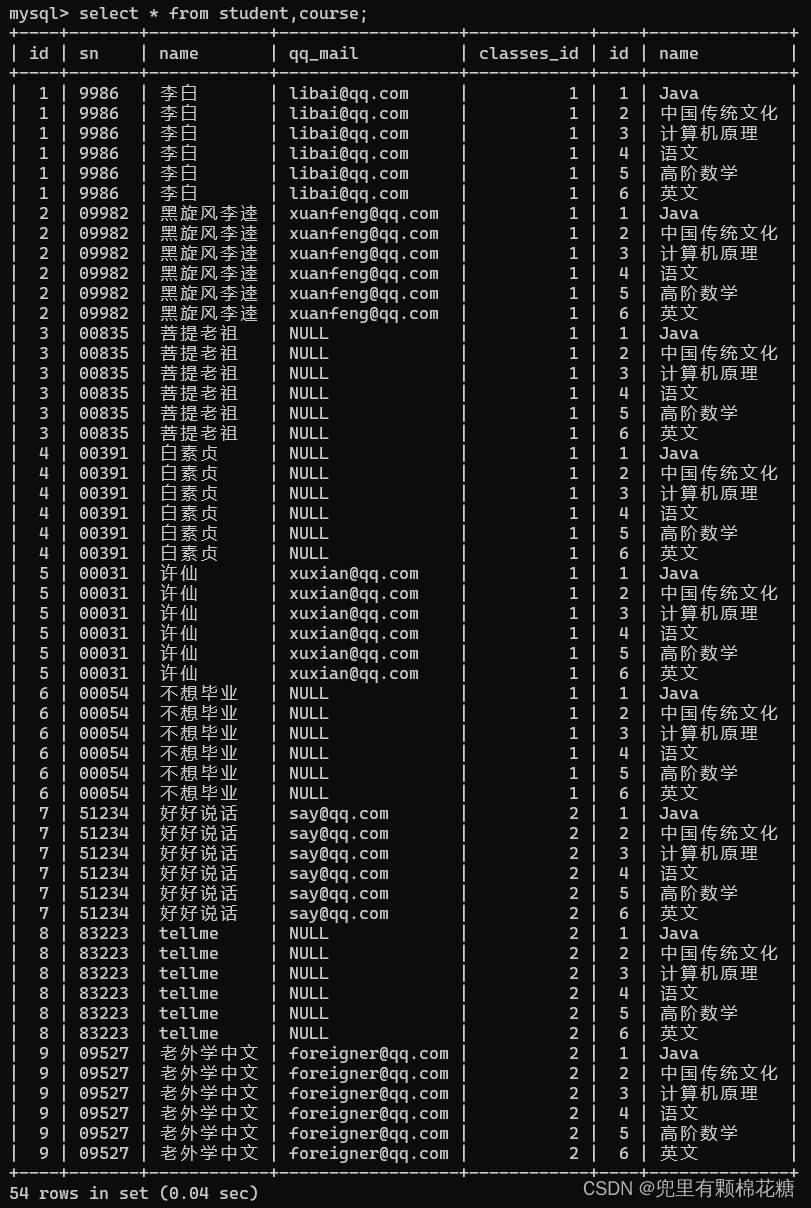
先来看
student表和course表的笛卡尔积的运算。
输入指令:select * from student,course;
笛卡尔积计算的结果数据如下:
我们可以观察到上述笛卡尔积计算出来的结果数据的大部分数据都是无效数据,我们需要加上一些连接条件把无效的、不合理的数据进行过滤掉。
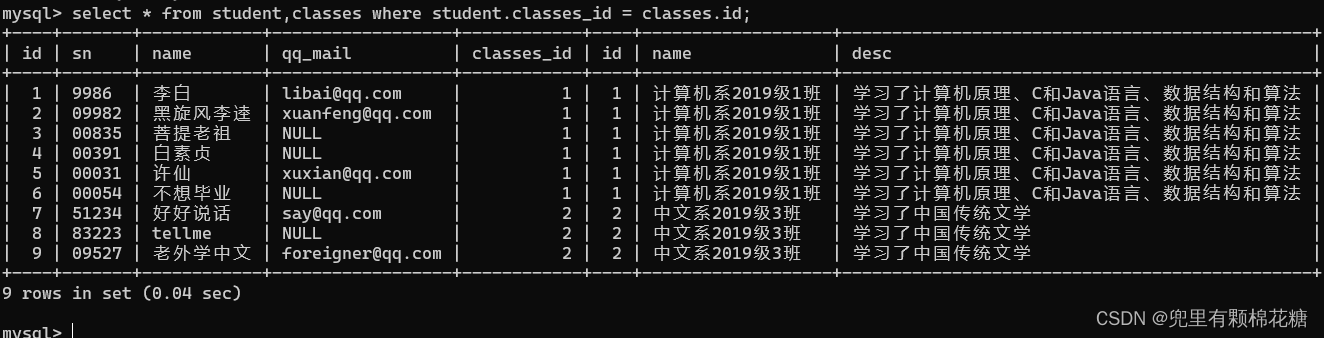
输入指令:select * from student,classes where student.classes_id = classes.id;
**注意,我们在进行多表查询的时候,条件中最好要写成”表名.列名“的形式,因为我们在进行联合查询的来查询多个表的时候,这多个表中的列名可能是一样的。**运算结果如下,请看:
笛卡尔积 + 必要的连接条件 = 多表联合查询。
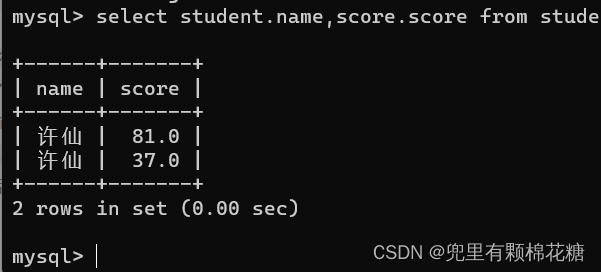
举例1:查询许仙的成绩(使用联合查询)
输入命令:select student.name,score.score from student,score where student.id = score.student_id and student.name = '许仙';
查询结果如下:
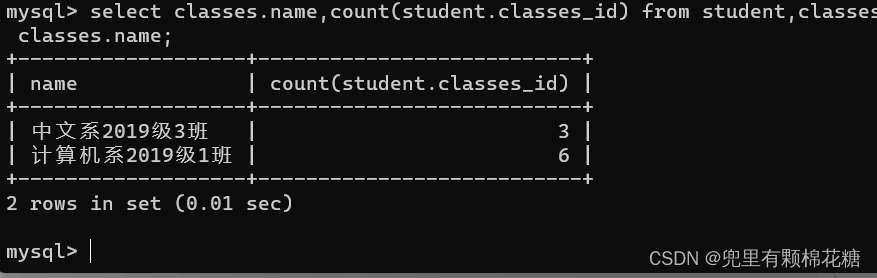
举例2:查询每个班级有多少人。
输入命令:select classes.name,count(student.classes_id) from student,classes where student.classes_id = classes.id group by classes.name;
查询结果如下:
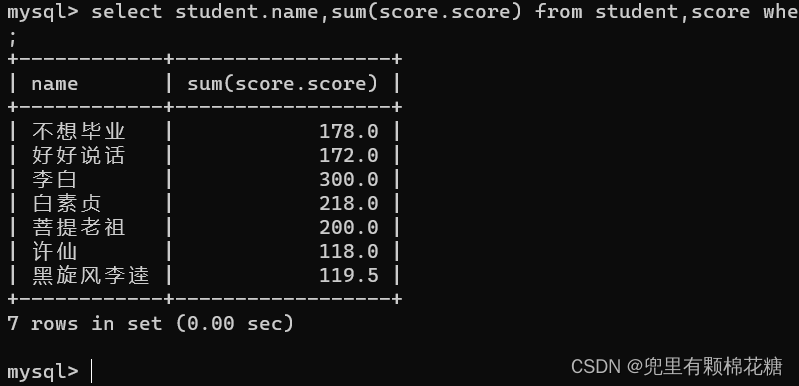
举例3:查询所有同学的总成绩以及个人信息(配合聚合函数**)。
输入命令:select student.name,sum(score.score) from student,score where student.id = score.student_id group by student.name;
查询结果如下:**
举例4:查询出所有同学的成绩,以及同学的个人信息(列出同学的名字,课程名字以及分数即可)
输入命令: select student.name as studentName,course.name as courseName,score.score from student,course,score where student. id = score.student_id and course.id = score.course_id;
查询结果如下:
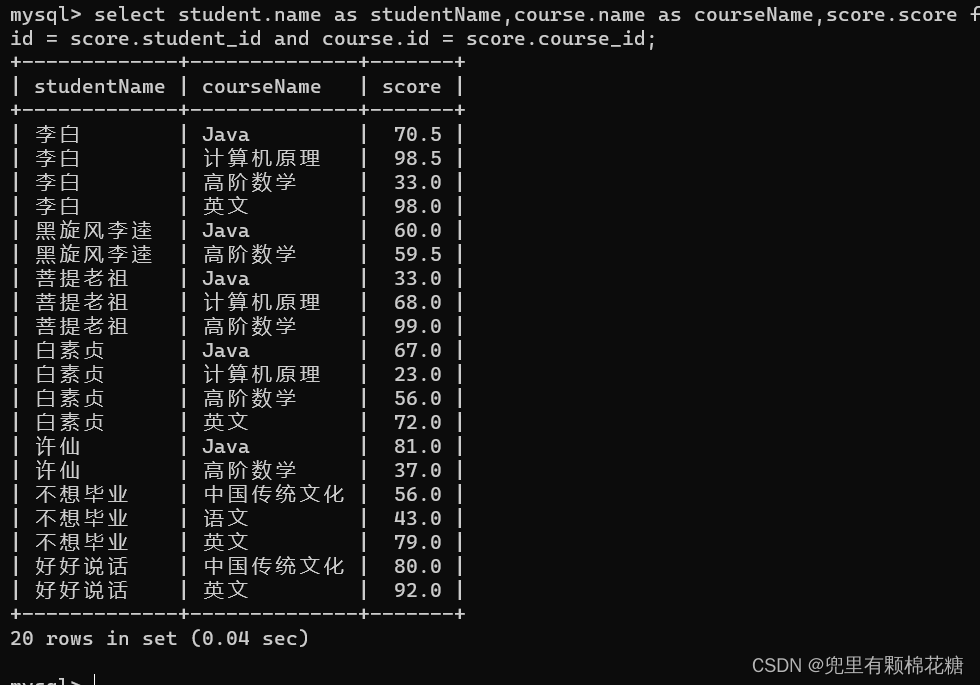
举例4这里我们需要注意到,我们查询的学生名字和课程名字,之所以能够写出连接条件就是因为这两个实体之间存在多对多的关系,如果是没有关系的两个表,这种连接条件就写不了了。
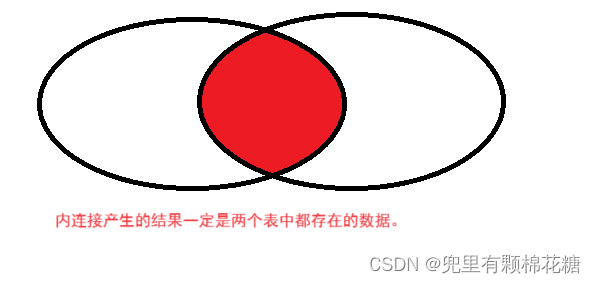
内连接
方式1:select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其它连接条件;
方式2:select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其它连接条件;
- 区别1(
多个表之间的分割方式):方式1中多个表的分割方式是使用join来进行分割的,而方式2是使用逗号即,来进行分割的。 - 区别2(
多个连接条件的指定方式):方式1中的连接条件是使用on来进行指定的,而方式2的连接条件是使用where来进行指定的。
内连接的表达方式2我们已经在上文进行解释过了,接下来我们就来看方式一是如何来进行使用的。
下面我们来对内连接中的语法1来进行举例:
举例1:(只写join不写on相当于一个完整的笛卡尔积查询)
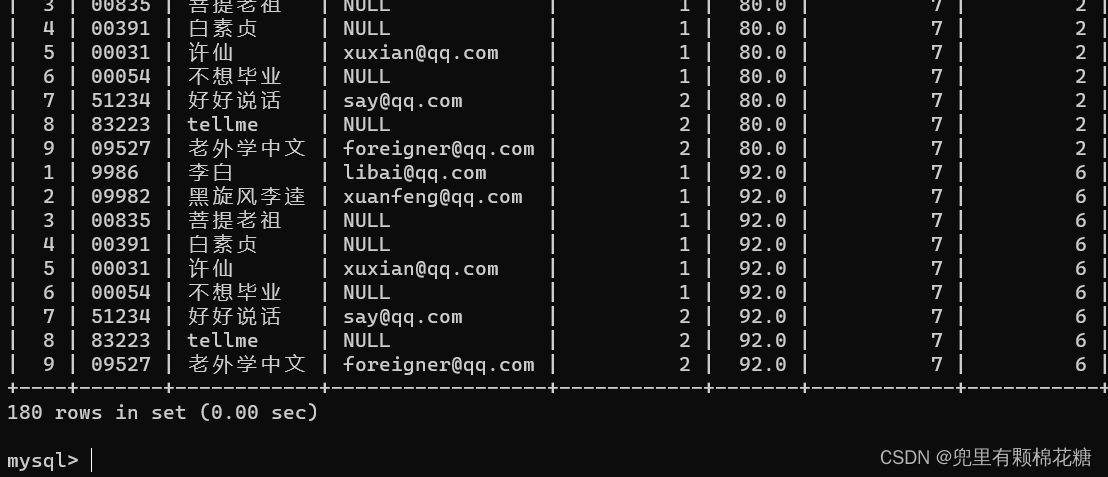
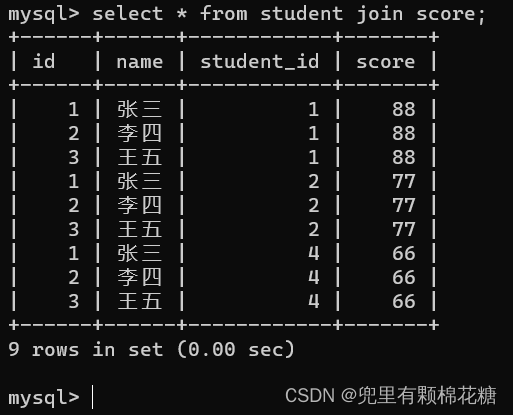
输入命令:select * from student join score;
查询结果如下:
举例2:查询许仙同学的成绩
输入命令:mysql> select student.name,score.score from student join score on student.id = score.student_id and student.name = '许仙';
查询结果如下:

内连接小结
在实际的开发中,使用多表查询就已经很克制了,其中多表查询中的内连接占绝大多数,此时我们使用内连接的第二种语法格式就已经足够了(个人感觉方式2:select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其它连接条件;比方式1:select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其它连接条件; 好用多了)
外连接
在学习外连接之前我们先来看一下内连接和外连接之间的区别,这里我们通过进行举例来带大家对内外连接进行区别:
现在,这里有两张表,如下图:
仔细观察上图中的两个表我们可以看到左表中的每一条记录都能在右表中找到对应的记录,同时右表中的每一条记录都能够在左表中找到,此时针对上述两张表的话无论使用内连接还是外连接查询出来的结果都是一样的,没有任何区别。
好了,现在再来看下面这张图,请看:
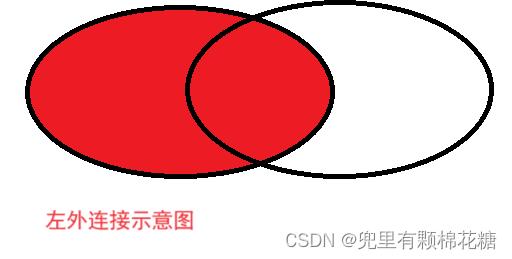
仔细观察上图中的两个表,我们可以看到左表中的王五在右表中没有数据而右表中的id为4的同学在左表中没有数据,此时在进行内外连接查询的时候就会有所差别了。


外连接分为左外连接和右外连接,左外连接就是以左表中的数据为基础,左表中的数据一定会存在于最终的查询结果中,如果遇到了左表中存在但是右表中不存在的数据,此时就会把该列设置为空值(
NULL)。
左外连接
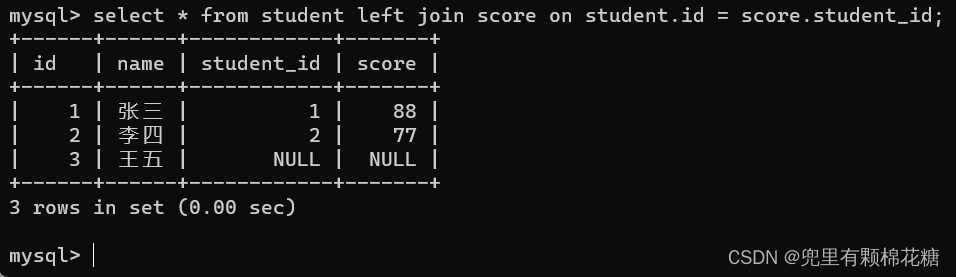
左外连接测试数据
create table student(id int,name varchar(20));
create table score(student_id int,score int);
insert into student values(1,'张三'),(2,'李四'),(3,'王五');
insert into score values(1,88),(2,77),(4,66);
如上图,如果使用左外连接进行查询的话,此时王五的成绩就是空值(NULL)。
不妨来输入sql语句来进行看一下上述左外连接的查询结果:
输入命令:select * from student left join score on student.id = score.student_id;
查询结果如下:
可以看到使用左外连接之后虽然可以把王五的成绩设置为空值,但是右表中4号同学的成绩就被忽略掉了。
右外连接
右外连接就是以右表中的数据为基础,最终查询出来的结果一定包含右表中的数据;同时如果遇到了右表中存在而左表不存在的数据此时就会把对应的列设置为空值(
NULL)。

举例1:
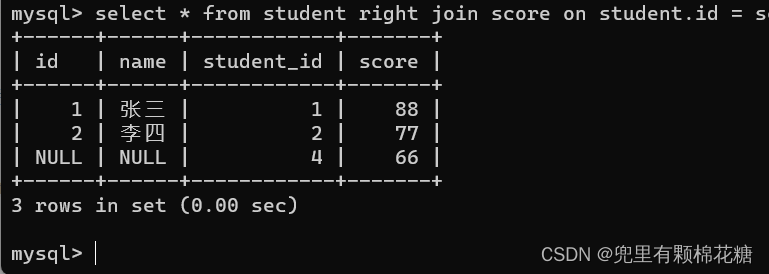
输入命令:select * from student right join score on student.id = score.student_id;
查询结果如下:
全外连接
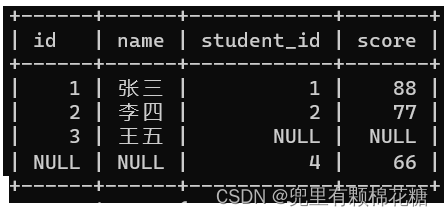
自连接
自连接是指在同一张表连接自身进行查询,就是自己和自己进行笛卡尔积,本质是把行之间的关系转换为列之间的关系(把未知问题转换为已知问题)。另外自连接的确在实际开发中很少会用到,自连接一般只有在一些极为特殊场景下才会使用到。
先来回顾一下之前的四张表,方便我们进行自连接的举例,请看:
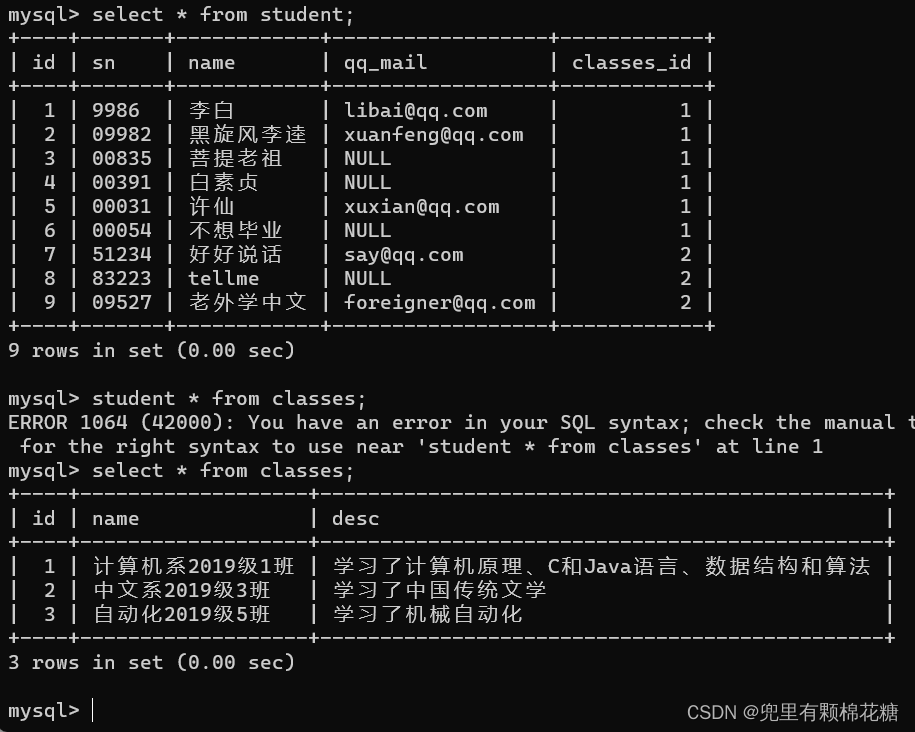
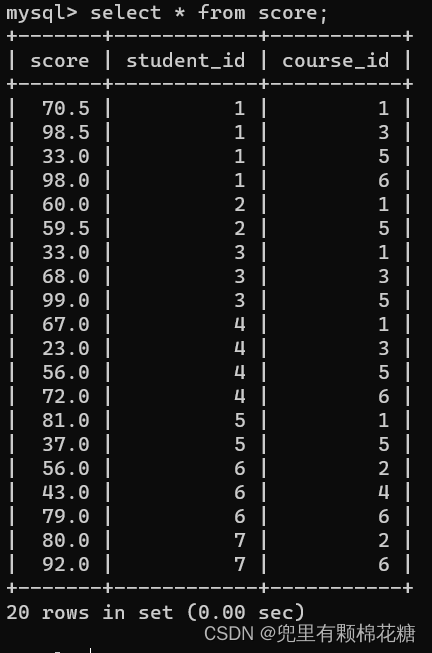
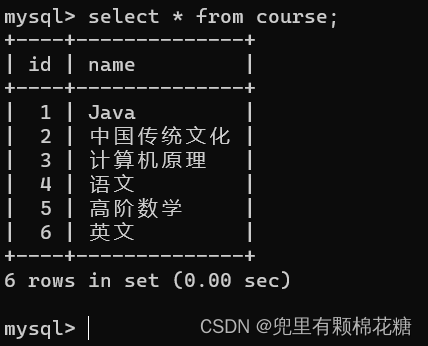
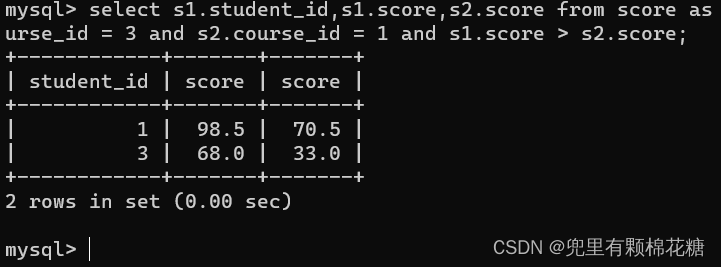
举例:查询所有“计算机原理”成绩比“Java”成绩高的成绩信息
输入命令:select s1.student_id,s1.score,s2.score from score as s1,score as s2 where s1.student_id = s2.student_id and s1.co urse_id = 3 and s2.course_id = 1 and s1.score > s2.score;
查询结果如下:
子查询
重要的事情放前面:日常开发中我们对待子查询的使用要比其他多表查询更要克制。子查询本质上就是把多个sql语句合并为一个sql。
我们依然是使用之前的四张表,方便我们进行子查询的举例,请看:
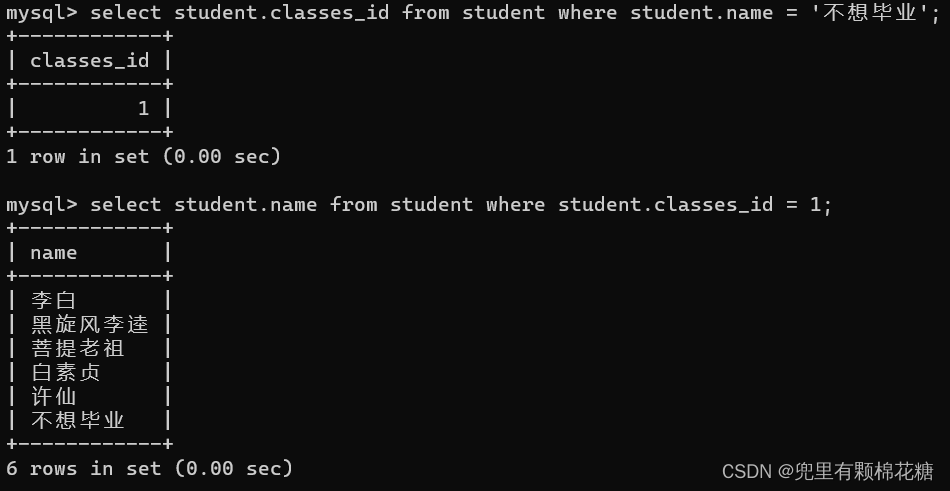
子查询举例:查询与“不想毕业”同学的同班同学。
如果不使用子查询,我们可以分为两步来进行查询,请看下图:
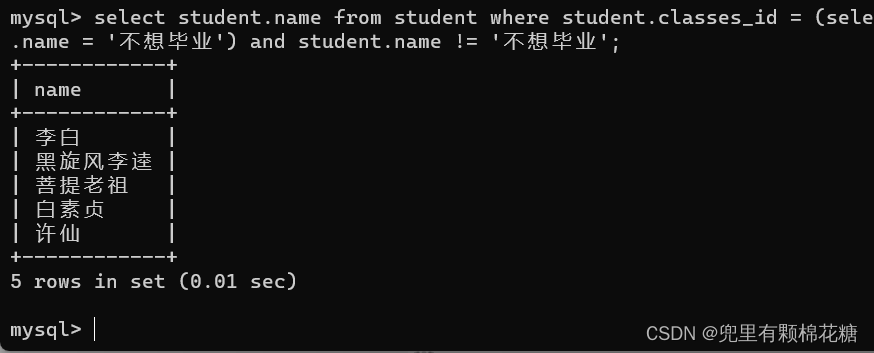
如果使用子查询进行查询的话,
输入命令:select student.name from student where student.classes_id = (select student.classes_id from student where student.name = '不想毕业') and student.name != '不想毕业';
查询结果如下:
关于子查询操作,我们需要知道的是,子查询的操作和我们平常日常开发中的设计理念(可读性好,开发效率高)是背道而驰的,为了达到可读性高,我们一般会采用化繁为简的方式(把复杂的化为简单的,采用了封装的思想,集中关注其中一个点而不用考略其它的点。封装:把任务拆分成多个小的模块,同一时刻只关注其中一个模块即可,这样可以把我们的注意力聚焦在一个点上而不需要考虑到其它的点。各个模块之间的关系考虑是的高内聚低耦合)来达到可读性高这种效果。而子查询这种操作却与之恰恰相反。
合并查询
合并查询就是把多个select查询的结果集合合并为一个集合。
注意合并查询有一个使用条件就是参与合并的结果集的列名个数相同,列名类型必须匹配,同时查询出来的最终结果的列名取自先前结果集的第一个结果集中的列名。
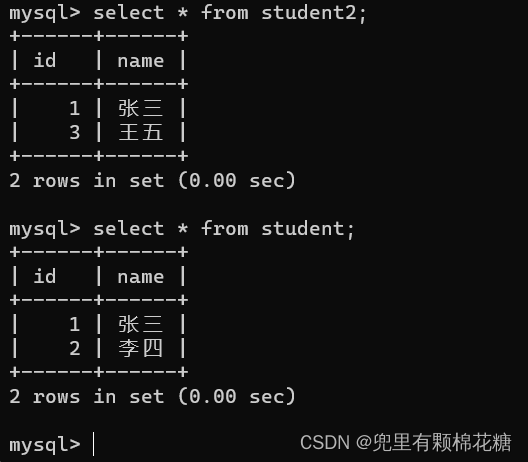
合并查询数据测试语句
create table student(id int,name varchar(20));
create table student2(id int,name varchar(20));
// 插入数据
insert into student values(1,'张三'),(2,'李四');
insert into student2 values(1,'张三'),(3,'王五');
现在我们来使用合并查询进行查询把上述的两张表进行合并在一起,
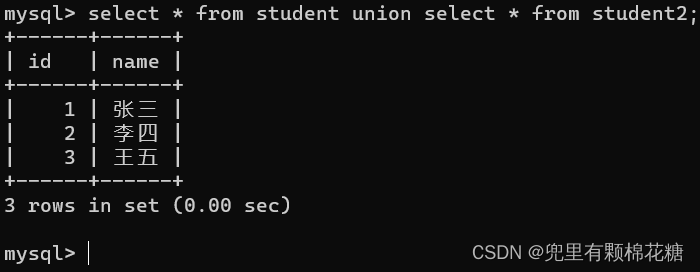
输入命令(使用union进行查询):select * from student union select * from student2;
查询结果如下:
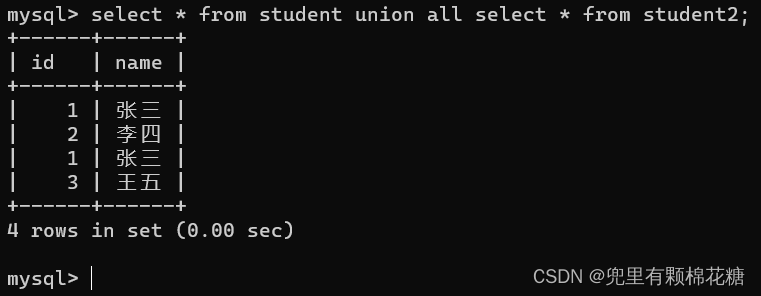
如果使用union all来进行查询的话,输入命令:select * from student union all select * from student2;
查询结果如下:
二、多表查询总结
内连接语法格式:
方式1:select 字段1,字段2,... from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其它连接条件;
方式2:select 字段1,字段2,... from 表1 别名1,表2 别名2 where 连接条件 and 其它连接条件;
外连接语法格式:
左外连接:select 字段1,字段2,... from 表名1 别名1 left join 表名2 别名2 on 连接条件;
右外连接:select 字段1,字段2,... from 表名1 别名1 right join 表名2 别名2 on 连接条件;
使用多表查询的一般步骤:
最后由于多表查询既会影响到运行效率,又会影响到实际的开发效率(可读性差),另外多表查询是非常复杂的,后续如果再次对复杂的多表查询进行sql优化的话一定是一个非常痛苦的过程,甚至需要对sql语句进行彻底地重构。
所以我们一定要克制住自己使用多表查询,尽量使用多个sql语句来替代多表查询。
三、表的增删查改进阶总结
- 聚合函数(
重点掌握):多个行之间进行运算、分组操作(group by和having);需要注意:having子句用于过滤使用group by子句进行分组后的结果集。它允许在分组后的结果集上应用条件过滤,类似于where子句对原始数据进行过滤(总之,having必须搭配group by来进行使用)。 - 多表联合查询(
重点掌握):其中包括内连接和外连接。(1)内连接:包括两种使用方式:方式1:select 字段1,字段2,... from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其它连接条件;;select 字段1,字段2,... from 表1 别名1,表2 别名2 where 连接条件 and 其它连接条件;(2)外连接:左外连接:select 字段1,字段2,... from 表名1 别名1 left join 表名2 别名2 on 连接条件;右外连接:右外连接:select 字段1,字段2,... from 表名1 别名1 right join 表名2 别名2 on 连接条件;。 - 自连接(可以理解为一个歪门邪道的小技巧哈):把行之间的关系转换为列之间的关系。
- 子查询:说白了,子查询就是套娃,把简单的sql语句复杂化,非常不建议大家使用。
- 合并查询:
union、union all合并多个结果集。
好了,MySQL中表的增删查改的进阶操作到这里就算是结束了。期望大家可以支持一下,一键三连哈😘

原文地址:https://blog.csdn.net/m0_74352571/article/details/134655801
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_50266.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!