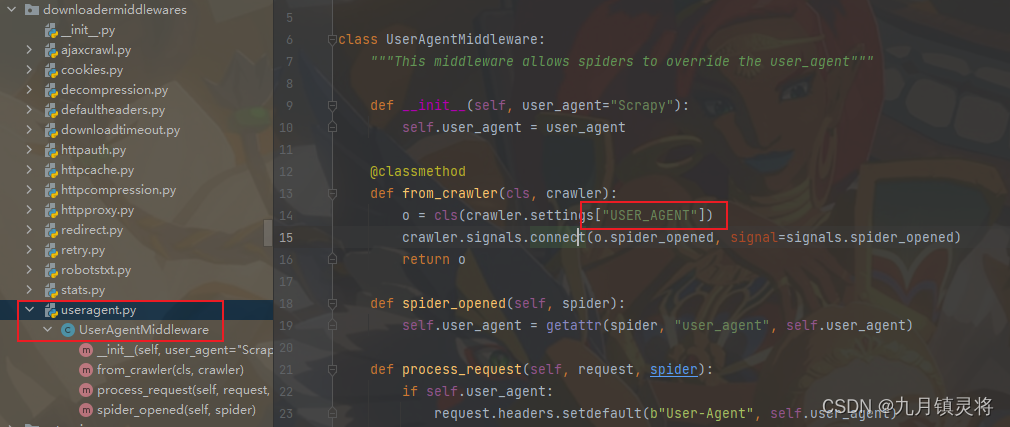
一、scrapy简介
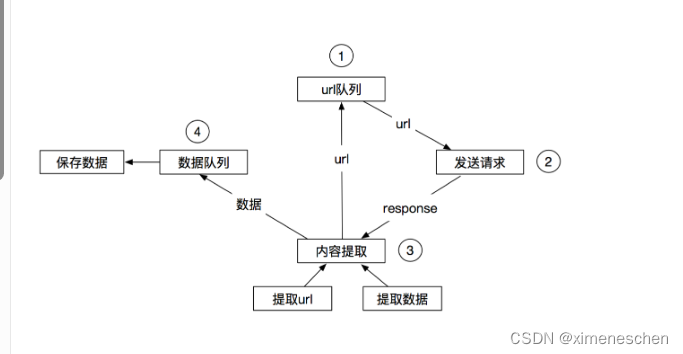
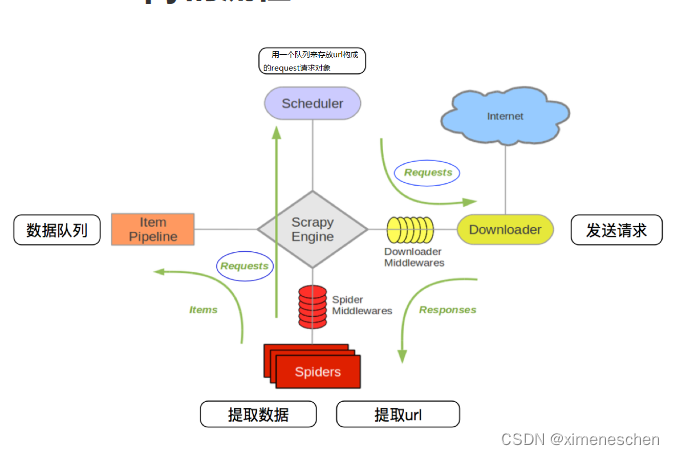
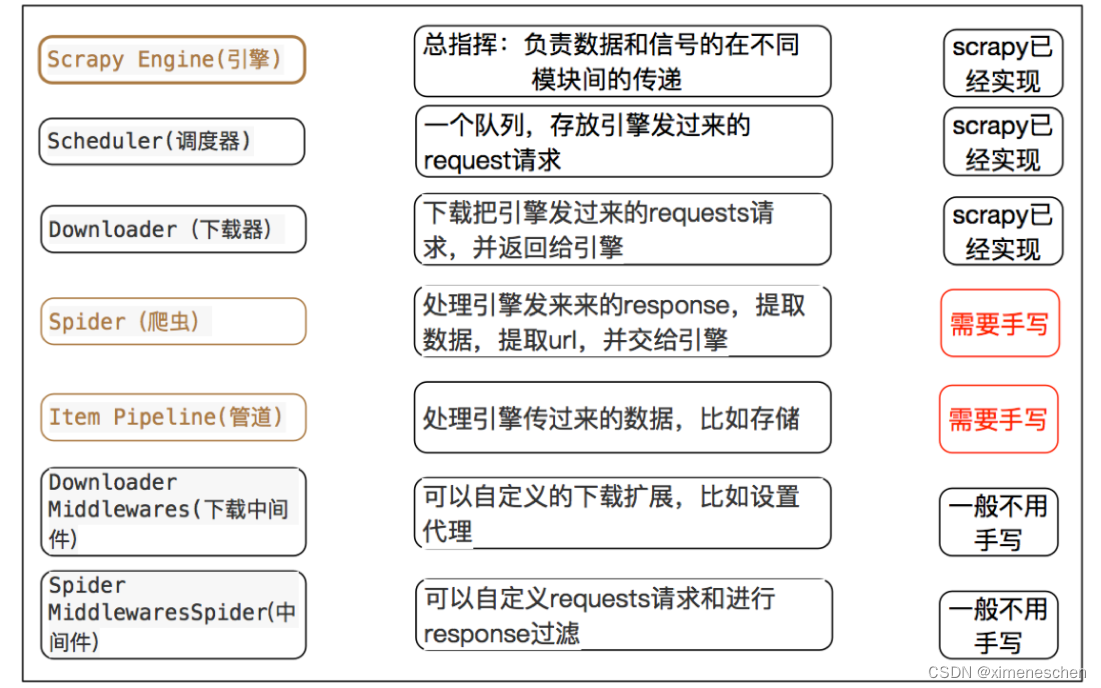
二、关于中间件
作用: 爬虫中间件主要负责处理从引擎发送到爬虫的请求和从爬虫返回到引擎的响应。这些中间件在请求发送给爬虫之前或响应返回给引擎之前可以对它们进行处理。
三、scrapy的三个内置对象
这三个内置对象是构建 Scrapy 爬虫时非常重要的组件。scrapy.Item 用于封装爬取到的数据,scrapy.Request 用于定义要爬取的URL和请求参数,scrapy.Response 用于处理从服务器返回的响应。通过巧妙地使用这些对象,你可以有效地构建和组织你的爬虫逻辑。
四、scrapy的入门使用


管道文件
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。