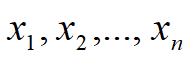本文介绍: 人体姿态估计(Human Pose Estimation, HPE)是一种识别和分类人体关节的方法。本质上,它是一种捕获每个关节(手臂、头部、躯干等)的一组坐标的方法,该坐标被称为可以描述人的姿势的关键点(keypoint)。这三种类型是随着应用逐步发展出来的,先检测关键点,类似于火柴人,进一步的检测出人的轮廓,再根据轮廓进一步的把人体进行3D重建。也称为运动学模型,该模型包括一组关键点(关节),例如脚踝、膝盖、肩膀、肘部、手腕和肢体方向,主要用于 3D 和 2D 姿势估计。
其中关键点检测是最开始的一步,本文主要对第一步的关键点检测进行一个概述,方便大家更快速的了解这里面涉及到的算法原理,属于科普文章。
1 什么是人体姿态估计
人体姿态估计(Human Pose Estimation, HPE) 是一种识别和分类人体关节的方法。本质上,它是一种捕获每个关节(手臂、头部、躯干等)的一组坐标的方法,该坐标被称为可以描述人的姿势的关键点(keypoint)。

人体姿势估计模型主要有三种类型: 这三种类型是随着应用逐步发展出来的,先检测关键点,类似于火柴人,进一步的检测出人的轮廓,再根据轮廓进一步的把人体进行3D重建。
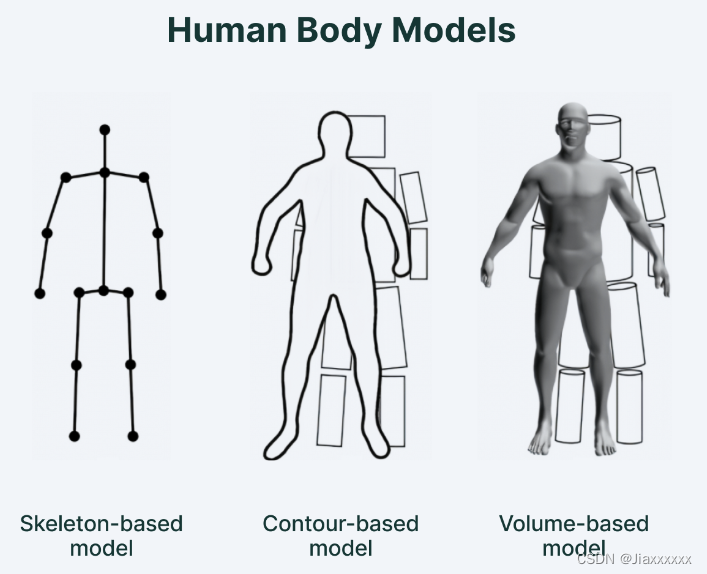
2 基于经典传统和基于深度学习的方法
2.1 基于经典传统的人体姿态估计算法
2.2 基于深度学习的人体姿态估计算法
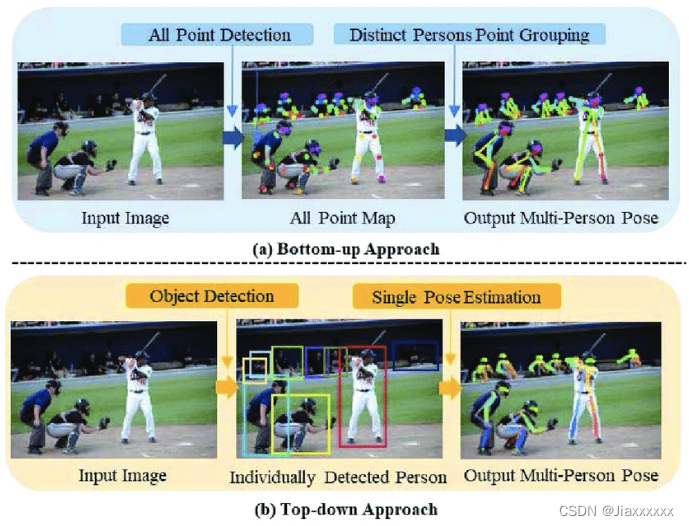
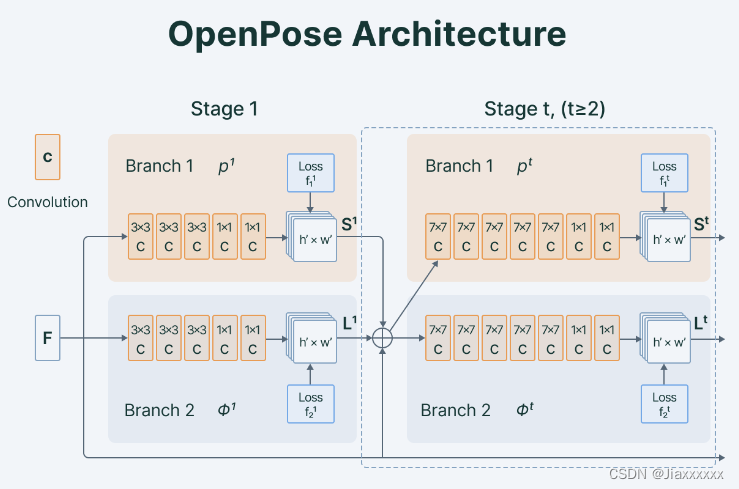
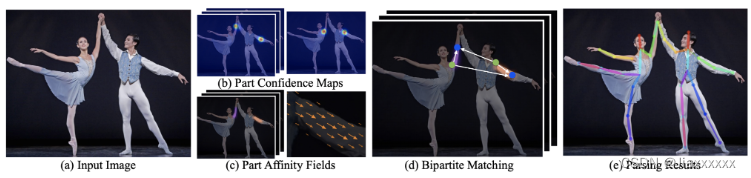
OpenPose
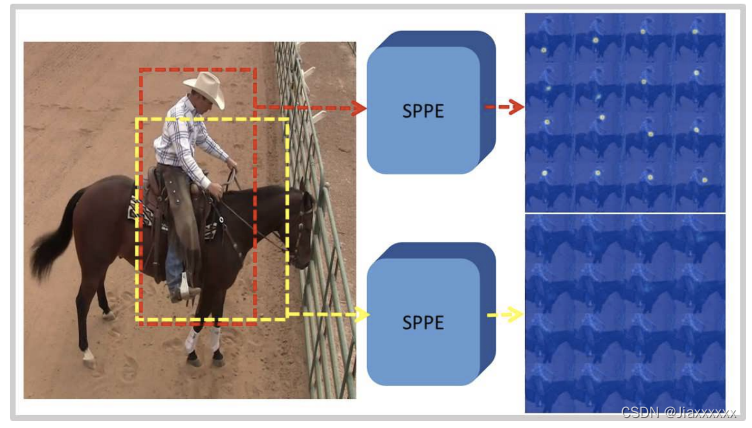
AlphaPose (RMPE)

3 算法应用
4 Paper
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。