一、 PHP部分
-
PHP如何实现静态化
PHP的静态化分为:纯静态和伪静态。其中纯静态又分为:局部纯静态和全部纯静态。
PHP伪静态:利用Apache mod_rewrite实现URL重写的方法;
PHP纯静态,就是生成HTML文件的方式,我们须要开启PHP自带的缓存机制,即ob_start来开启缓存。
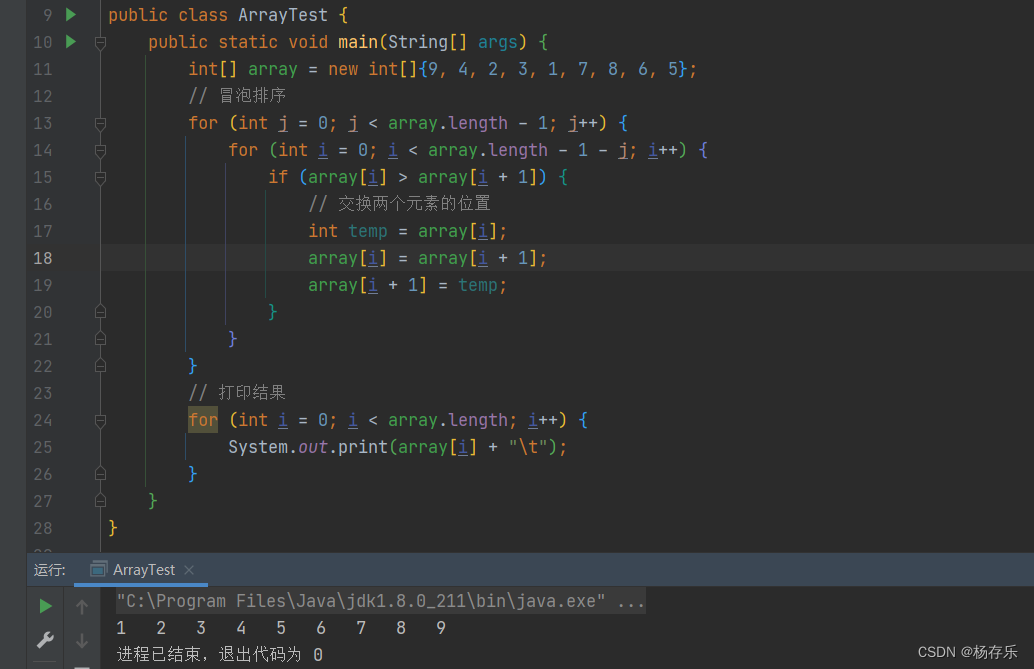
PHP的四种基本排序算法为:冒泡排序、插入排序、选择排序和快速排序。
冒泡排序:对数组进行多轮冒泡,每一轮对数组中的元素两两比较,调整位置,冒出一个最大的数来。
插入排序:假设组前面的元素是排好序的,遍历数组后面的元素,在已排好序的元素队列中找到合适的位置,插入其中。
快速排序:递归算法。先选择数组的第一个元素作为标准,然后把小于或等于它和大于它的数分别放入两个数组中,对这两个数组也进行相同的处理,最后合并这两个数组和第一个元素。
1)CGI(通用网关接口/ Common Gateway Interface)
2)FastCGI(常驻型CGI / Long-Live CGI)lamp
3)CLI(命令行运行 / Command Line Interface)
5)ISAPI(Internet Server Application Program Interface)
大概有23种设计模式,PHP常见的大概有10几种,虽然不算是基础,但是你必须要懂得。
1、创建型模式共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
2、结构型模式共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
3、行为型模式共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。

观察者模式:定义了对象之间的一对多依赖,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并且有所作为。即出版者+订阅者=观察者模式。
工厂模式 :将调用者和创建者分离,调用者直接向工厂类请求获取调用对象,减少代码耦合,提高系统的维护性和扩展性;
工厂模式应用场景:有多个产品类时就要用到工厂模式,比如在数据库连接中,我们可以采用多种数据库连接方法,有mysql扩展,mysqli扩展,PDO扩展等,在这种情况下我们可以一个扩展对应一个产品类,然后采用工厂模式。
适配器模式核心思想:把对某些相似的类的操作转化为一个统一的“接口”(这里是比喻的说话)–适配器,或者比喻为一个“界面”,统一或屏蔽了那些类的细节。适配器模式还构造了一种“机制”,使“适配”的类可以很容易的增减,而不用修改与适配器交互的代码,符合“减少代码间耦合”的设计原则。
-
16.数据库连接当使用完毕时应关掉。
单个cookie保存的数据<=4KB,一个站点最多保存20个Cookie。
对于session来说并没有上限,但出于对服务器端的性能考虑,session内不要存放过多的东西,并且设置session删除机制。
cookie中只能保管ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据。
session中能够存储任何类型的数据,包括且不限于string,integer,list,map等。
cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的。
session存储在服务器上,对客户端是透明对,不存在敏感信息泄漏的风险。
5、有效期上不同
开发可以通过设置cookie的属性,达到使cookie长期有效的效果。
session依赖于名为JSESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session不能达到长期有效的效果。
cookie保管在客户端,不占用服务器资源。对于并发用户十分多的网站,cookie是很好的选择。
session是保管在服务器端的,每个用户都会产生一个session。假如并发访问的用户十分多,会产生十分多的session,耗费大量的内存。
cookie是需要客户端浏览器支持的,假如客户端禁用了cookie,或者不支持cookie,则会话跟踪会失效。关于WAP上的应用,常规的cookie就派不上用场了。
运用session需要使用URL地址重写的方式,就是把session id附加在URL路径的后面,附加的方式也有两种,一种是作为URL路径的附加信息,另一种是作为查询字符串附加在URL后面。。一切用到session程序的URL都要进行URL地址重写,否则session会话跟踪还会失效。
cookie既能够设为本浏览器窗口以及子窗口内有效,也能够设为一切窗口内有效。
将用户信息加密放到http的header部分,每次拿到http的时候,验证获取header的信息。
CSRF(Cross–site request forgery)跨站请求伪造,黑客建立一个伪造网站或发送邮箱带了一个正常URL链接来让正常用户访问,来让正常用户让自己浏览器里的COOKIE权限来执行一些非法请求,
防范方法有,验证 HTTP Referer 字段;在请求地址中添加 token 并验证;
XSS攻击
主要将XSS代码提交存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码。当目标用户访问该页面获取数据时,XSS代码会从服务器解析之后加载出来,返回到浏览器做正常的HTML和JS解析执行,XSS攻击就发生了。
防范方法:通过过滤是针对非法的HTML代码包括单双引号等,使用htmlspecialchars()函数
RESTful API是REST风格的API,是一套用来规范多种形式的前端和同一个后台的交互方式的协议。RESTful API由后台也就是SERVER来提供前端来调用;前端调用API向后台发起HTTP请求,后台响应请求将处理结果反馈给前端。
单一职责原则:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责。
开放封闭原则:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
里氏替换原则:所有引用基类的地方必须能透明地使用其子类的对象。
接口隔离原则:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
依赖倒置原则:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
自动加载就是当我们在当前文件中实例化一个不存在的类时,调用自动加载机制引入相应的类文件。
注:自动加载有两种方式(都是php内置的),一种是通过__autoload(),另一种是通过spl_autoload_register()。
PSR是PHP Standards Recommendation的简称,制定的代码规范,简称PSR,是代码开发的事实标准。
PSR-4使代码更加规范,能够满足面向package的自动加载,它规范了如何从文件路径自动加载类,同时规范了自动加载文件的位置。
抽象类:是基于类来说,其本身就是类,只是一种特殊的类,不能直接实例,可以在类里定义方法,属性。类似于模版,规范后让子类实现详细功能。
具体类(class)——执行行为
接口:主要基于方法的规范,有点像抽象类里的抽象方法,只是其相对于抽象方法来说,更加独立。可让某个类通过组合多个方法来形成新的类。
1、都是用于声明某一种事物,规范名称、参数,形成模块,未有详细的实现细节。
3、语法上,抽象类的抽象方法与接口一样,不能有方法体,即{}符号
4、都可以用继承,接口可以继承接口形成新的接口,抽象类可以继承抽象类从而形成新的抽象类
抽象类与接口的不同点:
1、抽象类可以有属性、普通方法、抽象方法,但接口不能有属性、普通方法、可以有常量
2、抽象类内未必有抽象方法,但接口内一定会有“抽象”方法
3、语法上有不同
4、抽象类用abstract关键字在类前声明,且有class声明为类,接口是用interface来声明,但不能用class来声明,因为接口不是类。
5、抽象类的抽象方法一定要用abstract来声明,而接口则不需要
6、抽象类是用extends关键字让子类继承父类后,在子类实现详细的抽象方法。而接口则是用implements让普通类在类里实现接口的详细方法,且接口可以一次性实现多个方法,用逗号分开各个接口就可
-
微服务的了解
概念:又称微服务架构,是一种架构风格,它将应用程序构建为以业务领域为模型的小型自治服务集合 。
优势:
特点:
php7的垃圾回收包含两个部分,一个是垃圾收集器,一个是垃圾回收算法。
垃圾收集器,把刚刚提到的,可能是垃圾的元素收集到回收池中 也就是把变量的 zend_refcount>0的变量 放在回收池中。 当回收池的值达到一定额度了,会进行统一遍历处理。进行模拟删除,如果zend_refcount=0那就认为是垃圾,直接删除它。 遍历回收池中的每一个变量,根据每一个变量,再遍历每一个成员,如果成员还有嵌套的话继续遍历。然后把所有成员的 做模拟的 refcount -1。如果此时外部的变量的 引用次数为 0 。那么可以视为垃圾,清楚。如果大于0,那么恢复引用次数,并从垃圾回收池中取出。
-
高并发解决方案
(2) 添加异步请求(先不将所有数据都展示给用户,用户触发某个事件,才会异步请求数据)
(4) CDN加速
(1) 页面静态化
(2) 并发处理
(3) 队列处理
防止注入的第一步就是验证数据,可以根据相应类型进行严格的验证。比如 int 类型直接同过 intval 进行转换就行:
参数化绑定,防止 SQL 注入的又一道屏障。php MySQLi 和 PDO 均提供这样的功能。比如 MySQLi 可以这样去查询:
https://blog.csdn.net/t707584896/article/details/128798962
引用就是:当改变$Object1对象时,$Object2也做相同的变化。
克隆就是:克隆的对象$Object1与原来的对象没有任何关系,它是将原来的对象从当前位置从新复制了一份。
composer是一个依赖管理工具,composer会帮你安装这些依赖的库文件;
比如composer可以解决自动加载类,不用你写过多的new。
二. 数据库方面
第一范式:
第二范式:
2NF是对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
3NF是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存
4.InnoDB表的大小更加的大,用MyISAM可省很多的硬盘空间。
5.InnoDB 引擎的索引和文件是存放在一起的,找到索引就可以找到数据,是聚簇式设计。
6.MyISAM 引擎采用的是非聚簇式(即使是主键)设计,索引文件和数据文件不在同一个文件中。
(1)、B+树索引(O(log(n))):关于B+树索引,可以参考 MySQL索引背后的数据结构及算法原理
(2)、hash索引:
(2)、非聚集索引(non–clustered index)
(1)、主键索引:主键索引是一种特殊的唯一索引,不允许有空值
(2)、普通索引或者单列索引
(3)、多列索引(复合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
列越小越快
避免null值
原子性:事务是一个不可分割的工作单位,要么同时成功,要么同时失败。例:当两个人发起转账业务时,如果A转账发起,而B因为一些原因不能成功接受,事务最终将不会提交,则A和B的请求最终不会成功。
持久性:一旦事务提交,他对数据库的改变就是永久的。注:只要提交了事务,将会对数据库的数据进行永久性刷新。
读写分离解决的是,数据库的写操作,影响了查询的效率,适用于读远大于写的场景。读写分离的实现基础是主从复制,主数据库利用主从复制将自身数据的改变同步到从数据库集群中,然后主数据库负责处理写操作(当然也可以执行读操作),从数据库负责处理读操作,不能执行写操作。并可以根据压力情况,部署多个从数据库提高读操作的速度,减少主数据库的压力,提高系统总体的性能。
https://blog.csdn.net/shida219/article/details/117981566

https://blog.csdn.net/weixin_45433031/article/details/120838045
InnoDB引擎中,非主键索引查找数据时需要先找到主键,再根据主键查找具体行数据,这种现象叫回表查询
索引覆盖,即将查询sql中的字段添加到联合索引里面,只要保证查询语句里面的字段都在索引文件中,就无需进行回表查询;
4、在索引列上使用“IS NULL”或“IS NOT NULL”操作;
6、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
7、当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
脏读(无效的数据)
a事务把数据改完之后并没有提交,b事务读到这个改完数据之后的事务,
b事务读完之后,a事务又把数据做了一个回滚操作,这种现象叫脏读
a事务把数据读完拿去用了,b事务刚好直接把数据给改了,并且提交了,
a事务会发现之前读的数据不准确了
幻读现象
举例:假设一张表一共有10条数据,a事务把id大于3的数据name全部改成了xx,
就在刚刚改完的那一刻,b事务又插入一条数据,a事务改完之后,会发现有一条数据没有修改成功
-
MySQL数据库cpu飙升到100%的话怎么处理?
https://blog.csdn.net/t707584896/article/details/129971047
2、读写分离,这样减少主库的压力,支持更大的并发,主写从读。还可以单独使用一个从库来做为企业内部人员查询数据使用的服务器,这样更有利于减少线上服务器的访问压力。
1.Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
2.Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
3.Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
4.Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash–safe能力。
5.由binlog和redo log的概念和区别可知:binlog日志只用于归档,只依靠binlog是没有crash–safe能力的。但只有redo log也不行,因为redo log是InnoDB特有的,且日志上的记录落盘后会被覆盖掉。因此需要binlog和redo log二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失
-
慢SQL如何定位呢?
4.相关sql查询
id:选择标识符
ref:列与索引的比较
-
MySQL单表过亿条数据,如何优化查询速度?
https://www.zhihu.com/question/439988021/answer/2436380280
持久化:Redis支持持久化(周期性的将数据写到磁盘中),memcache不支持持久化
分布式:Redis做主从结构,memcache服务器需要通过hash一致化来支撑主从结构
最常用的的有5种,字符串(String)、哈希(Hash)、列表(list)、集合(set)、有序集合(ZSET)
https://blog.csdn.net/t707584896/article/details/128812799
-
redis淘汰策略
volatile-lru,针对设置了过期时间的key,使用lru算法进行淘汰。
allkeys-lru,针对所有key使用lru算法进行淘汰。
volatile-lfu,针对设置了过期时间的key,使用lfu算法进行淘汰。
allkeys-lfu,针对所有key使用lfu算法进行淘汰。
volatile–random,从所有设置了过期时间的key中使用随机淘汰的方式进行淘汰。
allkeys-random,针对所有的key使用随机淘汰机制进行淘汰。
https://www.zhihu.com/question/300767410/answer/1931519430
-
Redis的持久化机制
区别:
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程就是有一个fork子进程,先将数据集写入到临时文件中,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
RDB的优缺点:
优点:RDB持久化文件,速度比较快,而且存储的是一个二进制文件,传输起来很方便。
缺点:RDB无法保证数据的绝对安全,有时候就是1s也会有很大的数据丢失。
AOF的优缺点:
优点:AOF相对RDB更加安全,一般不会有数据的丢失或者很少,官方推荐同时开启AOF和RDB。
缺点:AOF持久化的速度,相对于RDB较慢,存储的是一个文本文件,到了后期文件会比较大,传输困难。
https://zhuanlan.zhihu.com/p/268290754
分析题目:保证Redis 中的 20w 数据都是热点数据 说明是被频繁访问的数据,并且要保证Redis的内存能够存放20w数据,要计算出Redis内存的大小。
a、保留热点数据:对于保留 Redis 热点数据来说,我们可以使用 Redis 的内存淘汰策略来实现,可以使用allkeys-lru淘汰策略,该淘汰策略是从 Redis 的数据中挑选最近最少使用的数据删除,这样频繁被访问的数据就可以保留下来了。
b、保证 Redis 只存20w的数据:1个中文占2个字节,假如1条数据有100个中文,则1条数据占200字节,20w数据 乘以 200字节 等于 4000 字节(大概等于38M);所以要保证能存20w数据,Redis 需要38M的内存。
一、架构不同
redis主从:一主多从;
二、存储不同
redis集群:数据的存储是通过hash计算16384的槽位,算出要将数据存储的节点,然后进行存储;
三、选举不同
redis主从:通过启动redis自带的哨兵(sentinel)集群进行选举,也可以是一个哨兵
选举流程:1、先发现主节点fail的哨兵,将成为哨兵中的leader,之后的主节点选举将通过这个leader进行故障转移操作,从存活的slave中选举新的master,新的master选举同集群的master节点选举类似;
选举流程:1、当主节点挂掉,从节点就会广播该主节点fail;
2、延迟时间后进行选举(延迟的时间算法为:延迟时间+随机数+rank*1000,从节点数据越多,rank越小,因为主从数据复制是异步进行的,所以 所有的从节点的数据可能会不同),延迟的原因是等待主节点fail广播到所有存活的主节点,否则主节点会拒绝参加选举;
3、参加选举的从节点向所有的存活的节点发送ack请求,但只有主节点会回复它,并且主节点只会回复第一个到达参加选举的从节点,一半以上的主节点回复,该节点就会成为主节点,广播告诉其他节点该节点成为主节点。
四、节点扩容不同
redis集群:可以扩容整个主从节点,但是扩容后需要进行槽位的分片,否则无法进行数据写入,命令为:
/usr/local/redis-5.0.3/src/redis-cli -a zhuge —cluster reshard 192.168.0.61:8001,其中的192.168.0.61:8001为新加入的主从节点;
-
redis消息队列如何防止数据丢失
Redis实现消息队列有两种形式:
广播订阅模式:基于Redis的 Pub/Sub 机制,一旦有客户端往某个key里面 publish一个消息,所有subscribe的客户端都会触发事件
集群订阅模式:基于Redis List双向+ 原子性 + BRPOP
Redis消息队列时,当Redis宕机后,消息可能会丢失(也要看持久化的策略)。如果收消息方(消费端)未有重发和验证机制,Redis内的数据会出现丢失。所以,使用Redis的作为消息队列,通常是对于消息的准确性并非特别高的场景。
如果绝对的保证数据最终一致性,保证消息百分百不丢,那么需要:
2. redis配置成任何变更一定实时持久化,比如存储端是磁盘的话,每次变更马上同步写入磁盘,才算完成。redis是支持这种方式配置的,但是这么做会使它的内存数据库特性完全消失,性能变得十分低下。
3. 消费端也要实现事务方式,处理完成后,再回来真实删除消息。
3 4的需求需要自己实现,可以一起考虑,用另外一个队列实现的方式也可以,但是更好的方式是在队列内部实现个计数器。hash格式的加个字段加数值,list的先推一个数值打底,string的头上加个数值再加个分隔符,就可以做个简单计数器了,虽然土,胜在够实用。
除了特定的系统之外,一般不会要求这么强的一致性,实现倒不难,但是性能会很差很差。
银行类支付类业务会要求严格的事务一致性,而互联网类业务一般会用点取巧的方式,就是可以容忍极短时间内少量数据丢失的方式,换取更高性能。
比如上面的redis处理,可以改为1000条数据变更的时候再真实落盘,即写入磁盘。那么极限情况下,如突然断电,存在可能丢失这1000条数据的风险。当然这种情况出现的概率也是很低的(远离蓝翔挖掘机?),所以大部分场景下可以接受。
-
MQ消息队列你怎么选择,各大优劣
2 RocketMQ
-
缺点:兼容性较差
3 Kafka
4 总结
如果说,消息队列并不是你将要构建的主角之一,对消息队列的功能和性能都没有很高的要求,只需要一个开箱即用易于维护的产品,建议使用 RabbitMQ。
如果系统使用消息队列的主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,那 RocketMQ 的低延迟和金融级的稳定性是我们需要的。
如果需要的是处理海量的数据,像收集日志、监控信息或是前端的埋点这类数据,或是应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
INT(1) 和 INT(10)本身没有区别,但是INT[(M)] 加上ZEROFILL值后,会对值有宽度的设置,不够位数前面自动补0.
-
MySQL:数据库自增 ID 用完了会咋样?
把主键类型改为 bigint,也就是 8 个字节。这样能存储的最大数据量就是 2^64
PS:单表 21 亿的数据量显然不现实,一般来说数据量达到 500 万就该分表了
三、 服务器&其它方面
1.pwd 命令 2.ls 命令 3.cd 命令 4.man 命令 5.grep 命令 6.find 命令 7.chmod 命令 8.ps 命令 9.kill 命令 10.tail 命令 11.netstat 命令 8.date 查看当前系统时间 10.echo 打印
$pid = pcntl_fork();$fp = fopen(“test.txt“, “a”);if (flock($fp, LOCK_EX)){ fwrite($fp, “content“); fflush($fp); flock($fp, LOCK_UN);}else{ echo “此文件正在被其他进程占用“;}
https://blog.csdn.net/zhanghongshun624/article/details/127920039
https://blog.csdn.net/t707584896/article/details/129266951
主要从并发上面考虑:缓存、分流、redis锁、队列、mysql所有等方面
在多个系统中,只需要登陆/注销一次,就可以完成所有系统中的用户登陆验证。
以上方式的前提都要有统一的用户信息存储中心。
https://blog.csdn.net/sinat_36757755/article/details/124049382
1、基于网关 API
2、基于 RPC
3、基于 SideCar
https://zhuanlan.zhihu.com/p/452558073
握手:
服务端收到请求,回复确认标示和顺序码(X)+1的确认码和另一个顺序码(Y)
客户端验证(X)+1确认码,通过后发送确认标示和(Y)+1的顺序码给服务端,服务端验证通过后建立连接
挥手:
第一次握手:TCP发送一个FIN(结束),用来关闭客户到服务端的连接。
第二次握手:服务端收到这个FIN,他发回一个ACK(确认),确认收到序号为收到序号+1。
第三次握手:服务端发送一个FIN(结束)到客户端,服务端关闭客户端的连接。
第四次握手:客户端发送ACK(确认)报文确认,并将确认的序号+1,这样关闭完成
server端收到结束请求后,需要等待数据传输完毕,所以只能先发送一个收到请求的确认信息给客户端,等数据传输完毕后再发送结束报文。
1、构建请求
2、查找缓存
3、域名解析
4、与服务器建立连接
TCP的三次握手
5、发起HTTP请求
6、服务器处理请求
7、服务器响应HTTP请求
8、客户端解析返回数据
9、与服务器断开连接
TCP的四次挥手
https://blog.csdn.net/weixin_43844718/article/details/126975557
-
swoole的了解
技术特点:
2 基于epoll,轻松支持高并发;
4 支持多种通信协议,方便地开发 Http、WebSocket、TCP、UDP 等应用
优点:
1 常驻内存的 cli 运行模式,不用每次请求加载一次项目代码
2 大大提高了对连接请求的并发能力
4 支持多种通信协议,能搭建 TCP/UDP/UnixSocket 服务器
缺点
1 相关文档较少
2 不支持 xdebug,不支持手动 dump,不熟悉相关工具的话,不太方便调试
3 入门难度高,多数 phper 不了解 TCP/IP 网络协议、多进程 / 多线程、异步 io 等
http://www.test.cc
|
Nginx
|
路由到 http://www.test.cc/index.php
|
加载nginx的fast-cgi模块
|
fast-cgi监听127.0.0.1:9000地址
|
www.test.com/index.php请求到达127.0.0.1:9000
|
php-fpm 监听127.0.0.1:9000
|
php-fpm 接收到请求,启用worker进程处理请求
|
php-fpm 处理完请求并撤消内存,返回给nginx
|
nginx 将结果通过http返回给浏览器2.慢,说明能打开,直接走这一步,free/top命令查看服务器内存和CPU使用情况,iftop等工具查看带宽
4.排查响应慢的接口代码,看php,mysql,redis等的日志看错误信息(mysql的慢查询日志功能,php–fpm慢日志功能,需要配置开启)
-
高并发解决方案
1、流量优化
2、前端优化
(2) 添加异步请求(先不将所有数据都展示给用户,用户触发某个事件,才会异步请求数据)
(3) 启用浏览器缓存和文件压缩
(4) CDN加速
(5) 建立独立的图片服务器(减少I/O)
3、服务端优化
(1) 页面静态化
(2) 并发处理
(3) 队列处理
4、数据库优化
(1) 数据库缓存
(2) 分库分表,分区
(3) 读写分离
5、web服务器优化
集群
(2) 负载均衡
-
如何选择消息队列?
https://blog.mimvp.com/article/47038.html
-
什么是MQ?
mq是一个消息队列,其主要目的是为了解决传统的消息传输上管理困难,效率不高的问题.
解耦: 如果是传统的消息通讯方式,无论是哪一方都要去维护一份供外部通讯的这个一个接口,而且各方处理消息的能力有限,效率上明显跟不上,并且这样子二者之间的耦合度非常高,对于拓展管理方面极不友好,而是要了mq就不一样,发送方只需要将消息发送给mq就可以了,别的不用考虑,接口什么的由mq去维护,接收方也只需要去mq里消费消息就可以了,就需要其他开销,一切由mq中间件来做,达到了解耦操作.
异步: 使用mq,还可以达到异步效果,极大地提升了消息传输的效率.发送方在发送消息后不需要关心消费方是否能消费完成,还可以继续发送其他消息.
削峰:如果是传统的消息通讯,一下子有大量的消息发送给接收方,这样对于接收方的处理压力是很大的,而我们刚好可以利用mq达到一个缓冲操作,一旦流量超出了接收方处理范围,不用担心,只需要慢慢消费即可,像经典的双十一,就很容易会使用到mq这么一个优点.
因为增加了中间件,系统复杂度肯定大大提高,增加了很多维护的成本,比如我们要保证消息不丢失(一致性)和消息幂等性问题,还要保证mq的高可用等.
消息的可靠性传输分为两个问题,一个是保证消息不被重复消费,另一个是保证消息不丢失.
保证消息不重复被消费,就是保证消息的幂等性问题,消息的幂等性是指一个操作执行任意多次所产生的影响均与一次执行的影响相同,在mq里,也就是消息只能被消费一次,不能被重复消费.
来看看消息丢失的场景:
发送方丢失,可能发送方在发送消息的过程中,出现网络问题等导致mq接收不到消息,导致了消息丢失.
要解决这个问题,首先可以采用事务机制,在发送消息的时候实现事务机制,若是出现发送失败的情况,可以进行回滚,而让消息重新被发送.但是开启了事务,发送方就必须同步等待事务执行完毕或者回滚,导致消息一多,性能会下降.
但是,还有一个更好的办法:可以采用确认机制,发送方在发送消息的时候必须要保证要收到一个确认消息,如果没有收到或者收到失败的确认消息,就说明消息发送失败,要重新进行发送,确认机制是可以采用异步进行的,这样就极大地保证了在保留效率的基础上又能保证消息的不丢失问题.
第二个丢失问题可能是在mq方发生的,如果mq没有进行持久化,出现了宕机关机等情况,消息就会丢失,解决办法无非就是将消息进行持久化,这样在出现问题的时候可以及时对消息进行恢复.
第三个丢失问题可能在消费方发生,这和发送方丢失问题类似,解决这个问题也是采用确认机制,这样一来就可以实现效率上的保证和消息不丢失的保证.
但是解决了这些问题,就会产生下面的幂等性问题:
我们都知道mq是可以进行重发的,且只有在它认为失败的情况会进行重发.什么时候mq会认为它发送给消费者的消息是失败的呢?也就是超出了它等待消费者响应的时间,这是一个超时时间,若是过了这个时间消费者仍然没有响应,说明mq发送失败,就会进行重试,而其实这个时候消费者可能是没有失败的,它只是因为某个原因导致消费超出了mq的等待时间而已,这个时候mq再发送一次消息,消费者就会重复消费.
实现幂等性消费:
-
MQ相关面试题
https://blog.csdn.net/weixin_47303191/article/details/124693751
https://blog.csdn.net/KangJinXuan/article/details/126936926
多进程之间会产生进程隔离,global无效,不能共用一个mysql,redis连接,所以每个进程单独开一个数据库连接
icons
客户端发送的多次请求,服务端是可以一次性接收的。并不是客户端发送一次,服务端接收一次
不可以。
-
进程、线程、协程区别
进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程也由操作系统调度。
swoole相比于apache/fpm,主要节省了PHP框架和全局对象每次创建销毁带来的性能开销,是进程常驻内存型。
(1).进程常驻内存:
swoole本身是进程常驻内存,在进程启动的时候就将PHP框架等代码读取并编译完成,不需要每次启动的时候都执行编译步骤,大大降低了脚本的运行时间;
(2).连接池
php-fpm的模式php因为每次请求结束时都会销毁所有资源,因此无法使用连接池;而基于swoole的进程常驻内存模式,可以通过连接池的方式来加速程序,
使用连接池既可以降低程序的响应时间,又可以有效保护后端资源。,限定了最多连接数量,不会直接全部打到数据库
(3).可以使用协程处理异步IO
当开发中需要去请求多处的数据,而每一块的数据单独请求都要花较长时间,常规的php-fpm是阻塞式运行,无法对这类型的数据处理进行加速;而基于swoole的程序,可以将这类的业务并行化处理,并行去请求后端的数据源,能够大大优化了此类业务的运行时间。
例如:我们开发的时候经常会遇到一个请求要查询多块数据,每个数据之间都需要占用比较长的时间,常规的php-fpm模式因为是阻塞模式运行,无法对这类业务进行很好的加速。但是基于swoole的程序,可以将这类请求协程化处理,并行的去请求后端数据源,将原本sum(a+b+c)的时间变成接近max(a, b, c)。能够大大的优化此类业务。
-
swoole里的协程是什么,怎么用?为什么协程可以提高并发?
协程是通过协作而不是抢占的方式来进行切换,它创建和切换对内存等资源比线程小的多(可以理解为更小的线程);
协程的使用是通过SwooleCoroutine或者Co命名空间短命名简化类名来创建;
-
用了swoole以后,会不会发生内存泄漏?如果发生了怎么解决?
swoole由于是常驻内存,一旦资源加载进入后,会一直存在于内存中。对于局部变量,swoole会在回调函数结束后自动释放;对于全局变量(lobal声明的变量,
static声明的对象属性或者函数内的静态变量和超全局变量),swoole不会自动释放;因此操作不好会发生内存泄漏。
(2).swoole提供了max_request和max_task_request机制:进程完成指定数量的任务后,会自动退出,达到释放资源和内存的目的;而后manager进程会重新拉起新worker/task进程来继续处理任务。
使用限制:
max_request只能用于同步阻塞、无状态的请求响应式服务器程序;
-
Swoole进程结构
当启动一个Swoole应用时,一共会创建2 + n + m个进程,2为一个Master进程和一个Manager进程,其中n为Worker进程数。m为TaskWorker进程数。
原文地址:https://blog.csdn.net/t707584896/article/details/128814999
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_50465.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!