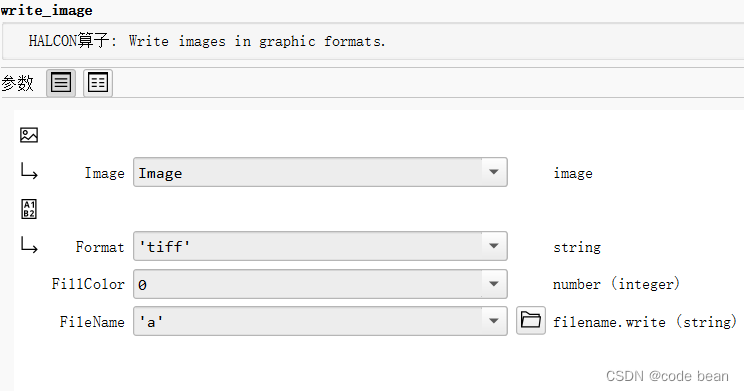
个人理解
思考
- 基于掩码的修改如果在修改的同时逐步融合新的Token是否可以更好的进行局部修改?
- 修改的范围是否足够精准?
- 要改变物体的时候形状差异过大会导致伪影?
- 当前的方法不能用于在空间上移动图像中的现有对象
- 怎么样能更好的生成符合视觉的效果(走Emu Edit造good data并训练的路子?其他的思路该怎么走)
- zero–shot的改进方法到目前是否已经到了极限(2023年11月28日)
- 当注意力存在交集,怎么能分离或者说进一步精准控制?
- 除了注意力机制还有什么是关键的因素
- 怎么和大语言模型LLM相结合(instruct pix2pix是一个例子)
基本信息
- 标题: Prompt-to-Prompt Image Editing with Cross-Attention Control
- 作者: Google Research
- 链接: 项目主页
- 发布信息: 2022
- 关键词: 文生图,扩散模型,图像编辑
摘要
背景
挑战
- 编辑技术的固有特性是保留大部分原始图像,而在基于文本的模型中,即使是对文本提示的微小修改也会导致完全不同的结果
- 最先进的方法通过要求用户提供空间掩码来定位编辑来缓解这个问题,因此忽略了掩码区域内的原始结构和内容
方法
结果
- 通过这一观察,我们展示了几个应用程序,它们仅通过编辑文本提示来监控图像合成
- 这包括通过添加规范替换单词、全局编辑,甚至巧妙地控制单词在图像中反映的程度来定位编辑
- 我们在不同的图像和提示上展示了我们的结果,展示了编辑提示的高质量合成和保真度
- 可以实现各种编辑任务,并且不需要模型训练、微调、额外数据或优化

引言
方法论

方法概述。
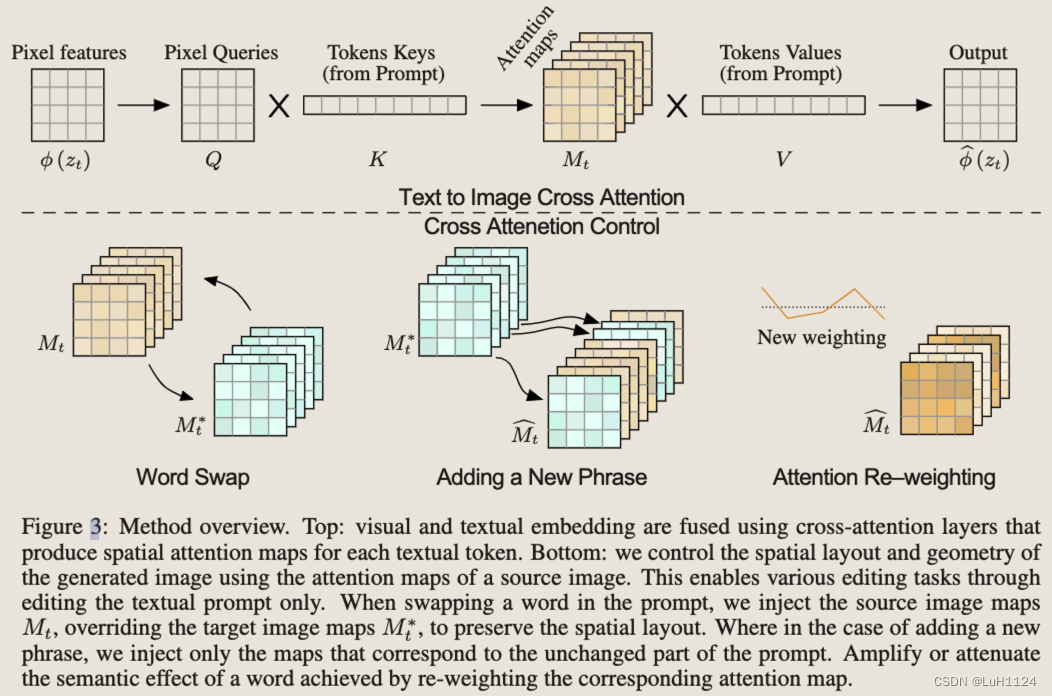
-
方法的创新点是什么?
-
方法的优势和潜在劣势是什么?
-
实施步骤
-
设DM (zt, P, t, s)为扩散过程单步t的计算,输出噪声图像zt−1,注意图Mt(未使用省略)。用 DM (zt, P, t, s){M ←
M
^
hat{M}
M^} 表示扩散步骤,我们用一个额外的给定映射
M
^
hat{M}
M^覆盖注意力图 M,但保留来自提供的提示的值 V。还用
M
t
∗
M^*_t
Mt∗表示使用编辑提示
∗
p^*
M
t
M_t
Mt,
M
t
∗
M^*_t
-
Attention Re–weighting
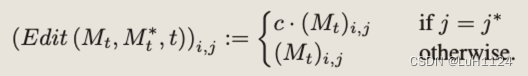

-
DDIM反演并执行P2P

但由于DDIM反演可能会产生和原图不一致的情况,使用直接从注意力图中提取的掩码恢复原始图像的未编辑区域。请注意,这里掩码是在没有用户指导的情况下生成的。

-

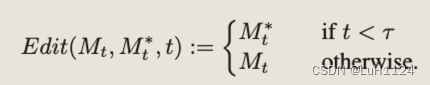

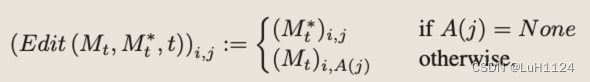


结果
讨论
引用
如何引用本文:
@article{hertz2022prompt,
title={Prompt-to-prompt image editing with cross attention control},
author={Hertz, Amir and Mokady, Ron and Tenenbaum, Jay and Aberman, Kfir and Pritch, Yael and Cohen-Or, Daniel},
booktitle={arXiv preprint arXiv:2208.01626},
year={2022}
}
原文地址:https://blog.csdn.net/weixin_43357695/article/details/134663605
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5051.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!