NGINX
nginx返回状态码
一些常见的状态码
200 - 服务器成功返回网页
404 - 请求的网页不存在
304 - Not Modified. 原来缓冲的还可以使用
500 - 大多是代码问题,或者sql报错
501 - 服务器不具备完成请求的功能
502 - Bad Gateway fpm进程挂掉或者后端程序过长时间未返回。
503 - Service Unavailable 当遇到这个状态码的时候表示服务临时不可用,比如nginx配置了频率限制,而client端又超过了配置的限制后就会收到503的响应。
504 - Gateway Time-out nginx的fastcgi模块有一个fastcgi_read_timeout配置,它表示从FastCGI server获取数据的超时时间。如果超过这个配置客户端就是收到504的响应。
HTTP 状态码的完整列表
**1xx(**临时响应)
表示临时响应并需要请求者继续执行操作的状态码。
**100**(继续)请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
**101**(切换协议)请求者已要求服务器切换协议,服务器已确认并准备切换。
**2xx** (成功)
表示成功处理了请求的状态码。
**200**(成功)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果是对您的 robots.txt 文件显示此状态码,则表示 Googlebot 已成功检索到该文件。
**201**(已创建)请求成功并且服务器创建了新的资源。
**202**(已接受)服务器已接受请求,但尚未处理。
**203**(非授权信息)服务器已成功处理了请求,但返回的信息可能来自另一来源。
**204**(无内容)服务器成功处理了请求,但没有返回任何内容。
**205**(重置内容)服务器成功处理了请求,但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
**206**(部分内容)服务器成功处理了部分 GET 请求。
**3xx **(重定向)
要完成请求,需要进一步操作。通常,这些状态码用来重定向。Google 建议您在每次请求中使用重定向不要超过 5 次。您可以使用网站管理员工具查看一下 Googlebot 在抓取重定向网页时是否遇到问题。诊断下的网络抓取页列出了由于重定向错误导致 Googlebot 无法抓取的网址。
**300**(多种选择)针对请求,服务器可执行多种操作。服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
**301**(永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
**302**(临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
**303**(查看其他位置)请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
**304**(未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
nginx返回4xx
403 Forbidden 访问被拒绝
一、由于启动用户和nginx工作用户不一致所致
查看nginx的启动用户,发现是nobody,而为是用root启动的
命令:
ps aux | grep "nginx: worker process" | awk'{print $1}'
1.2将nginx.config的user改为和启动用户一致,
命令:
vi conf/nginx.conf
二、缺少index.html或者index.php文件,就是配置文件中index index.html index.htm这行中的指定的文件。
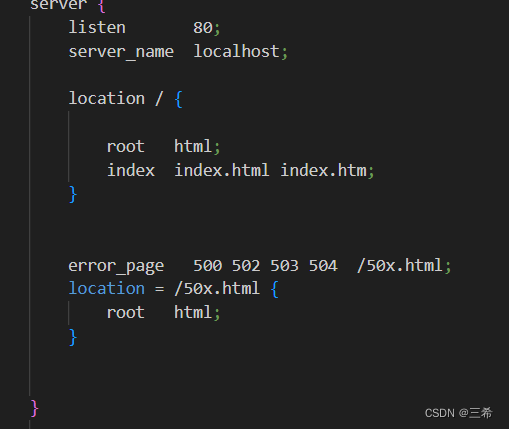
server {
listen 80;
server_name localhost;
index index.php index.html;
root /data/www/;
}
如果在/data/www/下面没有index.php,index.html的时候,直接文件,会报403 forbidden。
三、权限问题,如果nginx没有web目录的操作权限,也会出现403错误。
解决办法:修改web目录的读写权限,或者是把nginx的启动用户改成目录的所属用户,重启Nginx即可解决
chmod -R 777 /data
chmod -R 777 /data/www/
四、SELinux设置为开启状态(enabled)的原因。
查看当前selinux的状态
/usr/sbin/sestatus
将SELINUX=enforcing 修改为 SELINUX=disabled 状态
vi /etc/selinux/config
#SELINUX=enforcing
SELINUX=disabled
重启生效
reboot
404 NOT FOUND
一、 页面找不到 ,可能是url错了。
二、 也可能是配置文件的问题。
在/etc/nginx/conf.d 下有default.conf 和nginx.conf 两个配置文件,
前者是默认的配置,后者是我的个性化配置
nginx 运行的时候加载了conf.d文件夹下的所有.conf结尾的文件
default.conf 覆盖了nginx.conf配置,原因:
因为在nginx的配置中,conf.d文件夹中的配置文件优先级是按照字母顺序来的,default.conf 的优先级大于nginx.conf,覆盖了nginx.conf的配置
nginx返回5xx
简述5xx出现原因
500:大多是代码问题,或者sql报错。
501:服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
502:nginx在这里充当的是反向代理服务器的角色,是把http协议请求转成fastcgi协议的请求,通过fastcgi_pass指令传递给php-fpm进程,当php-fpm进程响应的内容是nginx无法理解的响应,就会返回502 bad gateway。
503:服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。(服务不可用)。一个http请求占用一个php-fpm进程,瞬时请求量过大时,没有足够的php-fpm进程去处理请求,就会返回503 service unavailable。
504: 单个php-fpm进程阻塞超过nginx的时间阈值返回504 gateway timeout。
505:服务器不支持请求中所用的 HTTP 协议版本。(HTTP 版本不受支持)
500错误
1、500 Internal Server Error 内部服务错误:顾名思义500错误一般是服务器遇到意外情况,而无法完成请求。
2、500出错的可能性:
a、编程语言语法错误,web脚本错误
b、并发高时,因为系统资源限制,而不能打开过多的文件
3、一般解决思路:
a、查看nginx、php的错误日志文件,从而看出端倪
b、如果是too many open files,修改nginx的worker_rlimit_nofile参数,使用ulimit查看系统打开文件限制,修改/etc/security/limits.conf,还是出现too many open files,那就要考虑做负载均衡,把流量分散到不同服务器上去了
c、如果是脚本的问题,则需要修复脚本错误,优化代码
501
服务器不具备完成请求的功能。例如:服务器无法识别请求方法时可能会返回。
502 Bad Gateway
网关超时。
fpm进程挂掉或者后端程序过长时间未返回。
503 Service Unavailable
解释:服务临时不可用。
问题原因:
nginx配置了频率限制,client端又超过了配置的限制,比如单个ip并发设置过小。
504 Gateway Time-out
nginx的fastcgi模块有一个fastcgi_read_timeout配置,它表示从FastCGI server获取数据的超时时间,增加它的等待时间,可以达到优化。
505 HTTP Version Not Supported
状态码是说服务器并不支持在请求中所标明 HTTP 版本。该状态是新加入 HTTP 1.1的
502、504的区别
502、504问题出现的可能性,一般是web服务器故障、程序进程不够。
a、使用nginx代理,而后端服务器发生故障;或者php-cgi进程数不够用;php执行时间长,或者是php-cgi进程死掉;已经fastCGI使用情况等都会导致502、504错误。
b、502 是指请求的php-fpm已经执行,但是由于某种原因而没有执行完毕,最终导致php-fpm进程终止。一般来说,与php-fpm.conf的设置有关,也与php的执行程序性能有关,网站的访问量大,而php-cgi的进程数偏少。针对这种情况的502错误,只需增加php-fpm的进程数。具体就是修改/usr/local/php/etc/php-fpm.conf文件,将其中的max_children值适当增加。这个数据要依据你的服务器的配置进行设置。一般一个php-cgi进程占20M内存,你可以自己计算下,适量增多。然后php-fpm然后重启一下.
c、504 表示超时,也就是客户端所发出的请求没有到达网关,请求没有到可以执行的php-fpm。与nginx.conf的配置也有关系。
通俗的来说,nginx作为一个代理服务器,将请求转发到其他服务器或者php-cgi来处理,当nginx收到了无法理解的响应时,就返回502。当nginx超过自己配置的超时时间还没有收到请求时,就返回504错误。
nginx返回502,504详解
502 Bad Gateway
官方解释:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
上面说到nginx收到了无法理解的响应,什么是无法理解的响应呢?
- nginx无法与php-fpm进行连接。
- nginx在连接php-fpm一段时间后发现与php-fpm的连接被断开。
那么什么时候会出现上面的情况呢?
- php-fpm没有启动,nginx无法将请求交给php-fpm
- php-fpm运行脚本超时,php-fpm终止了脚本的执行和执行脚本的Worker进程,nginx发现自己与php-fpm的连接断开
php-fpm没有启动
我们关闭php-fpm,刷新页面,发现返回502错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ihtG3GFc-1689747222343)(http://img.qdhgrc.com/cf32c2e53063778c811d06d57da96851)]
php-fpm请求超时
我们首先将php-fpm.conf中的max_terminate_request改成5s:
request_terminate_timeout = 5
在php脚本中添加如下语句:
sleep(20);
刷新页面,发现返回502错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jz8YDzWA-1689747222344)(http://img.qdhgrc.com/cf32c2e53063778c811d06d57da96851)]
其他502原因的检测
1、查看当前的PHP FastCGI进程数是否够用
netstat -anpo | grep "php-cgi" | wc –l
如果实际使用的【FastCGI进程数】接近预设的【FastCGI进程数】,那么,说明【FastCGI进程数】不够用,需要增大。
2、部分PHP程序的执行时间超过了Nginx的等待时间
可以适当增加nginx.conf配置文件中FastCGI的timeout时间。php.ini中memory_limit设低了会出错,修改了php.ini的memory_limit为64M,重启nginx,如果发现恢复了,那么就是PHP的内存不足的原因。
3、max-children和max-requests
主机上运行着nginx php(fpm) xcache的话,访问量日均 300W pv左右。如果是近期出现php页面打开很慢,cpu使用率突然降至很低,系统负载突然升至很高,查看网卡的流量,也会发现突然降到了很低这样的情况,而且这种情况只持续数秒钟就恢复,这时检查php-fpm的日志文件发现了一些线索:
1)Sep 30 08:32:23.289973 [NOTICE] fpm_unix_init_main(), line 271: getrlimit(nofile): max:51200, cur:51200
2)Sep 30 08:32:23.290212 [NOTICE] fpm_sockets_init_main(), line 371: using inherited socket fd=10, “127.0.0.1:9000″
3)Sep 30 08:32:23.290342 [NOTICE] fpm_event_init_main(), line 109: libevent: using epoll
4)Sep 30 08:32:23.296426 [NOTICE] fpm_init(), line 47: fpm is running, pid 30587
看显示的这几句的前面,是1000多行的关闭children和开启children的日志。因为php-fpm有一个参数 max_requests,该参数指明每个children最多处理多少个请求后便会被关闭,默认的设置是500。因为php是把请求轮询给每个children,在大流量下,每个children到达max_requests所用的时间都差不多,这样就造成所有的children基本上在同一时间被关闭。
在这期间,nginx无法将php文件转交给php-fpm处理,所以cpu会降至很低,不用处理php,更不用执行sql,而负载会升至很高,关闭和开启children、nginx等待php-fpm,网卡流量也降至很低,nginx无法生成数据传输给客户端。
解决方式:增加children的数量,并且将 max_requests 设置为 0 或者一个比较大的值,打开 /usr/local/php/etc/php-fpm.conf,调大以下两个参数,但是要根据主机实际情况,数值过大也不行。然后再重启php-fpm,就能恢复了。
4、增加缓冲区容量大小
将nginx的error log打开,发现【pstream sent too big header while reading response header from upstream】这样的错误提示。大概意思是nginx缓冲区有一个bug造成的,网站的页面消耗占用缓冲区可能过大。
参考国外系统管理员写的修改办法,增加了缓冲区容量大小设置,502问题彻底解决。后来系统管理员又对参数做了调整只保留了2个设置参数:client head buffer,fastcgi buffer size。
5、PHP脚本的最大执行时间
max_execution_time //php.ini
request_terminate_timeout //php.ini
这两项都是用来配置PHP脚本的最大执行时间。超时时php-fpm会终止脚本的执行,同时还会终止执行脚本的Worker进程。
如上,php-fpm child 18822被terminate后重新生成了新的Worker进程19164,所以nginx发现与自己通信的连接断了,就自然会返回502错误给客户端。客户端需再次发起请求重新建立新的连接,表象是刷新下浏览器即重新发起请求
所以只需将这两项的值适当调大,让PHP脚本不会因为执行时间长而被终止从而与nginx激活连接丢失。
request_terminate_timeout优先级高于max_execution_time,不想改全局的php.ini,只改php-fpm的配置就可以了。这里暂且调到600秒
request_terminate_timeout = 600
504 Bad Gateway timeout
504 即 nginx 超过了自己设置的超时时间,不等待 php-fpm 的返回结果,直接给客户端返回 504 错误。但是此时 php-fpm 依然还在处理请求(在没有超出自己的超时时间的情况下).
这里有三个相关的配置:
-
fastcgi_connect_timeout 300;
指定连接到后端 FastCGI 的超时时间.
-
fastcgi_send_timeout 300;
向 FastCGI 传送请求的超时时间,这个值是指已经完成两次握手后向FastCGI传送请求的超时时间.
-
fastcgi_read_timeout 300;
接收 FastCGI 应答的超时时间,这个值是指已经完成两次握手后接收FastCGI应答的超时时间.
网关超时,客户端所发出的请求没有到达网关,在限定时间内没有得到php-fpm,或者完成php-fpm的传输数据的工作而超时 。比方说:即nginx的worker去php-fpm进程池去处理,但是没有fpm进程可以使用了,等啊等,还是没有,返回504。
场景
nginx的fastcgi模块有一个fastcgi_read_timeout配置,它表示从FastCGI server获取数据的超时时间。如果超过这个配置客户端就是收到504的响应。比如执行了一段非常耗时的查询语句,nginx的相关fastcgi等待配置超时后,就会返回504,但是php-fpm还在运行。
解决办法
location ~ .php$ {
fastcgi_connect_timeout 180;//优化点
fastcgi_read_timeout 600;//优化点
fastcgi_send_timeout 600;//优化点
fastcgi_pass unix:/tmp/php-fpm.sock;
fastcgi_index index.php;
include fastcgi.conf;
}
调高上面标红的3个值后,主要是read和send两项(默认Nginx超时为60),完美地解决了504错误。
并且可以配置在http,server级别,也可以配置在location级别。
factcgi_connect_{read|send|timeout}是对fastcgi_pass生效
proxy_connect_{read|send|timeout|是对proxy_pass生效
优化方案
简述优化项
启动用户更改为非root,比如nginx,降权更安全
worker_processes 改为cpu核心数
worker_cpu_affinity 开启多核CPU使用
errorlog 配置crit尽量精简写log,减少磁盘IO
worker_rlimit_nofile 自行配置nginx的worker进程打开的最大文件数,
网络IO事件模型使用 epoll
worker_connections 设置一个worker可以打开的最大连接数
错误页面上的nginx版本信息关闭,提升安全性
开启sendfile()函数,sendfile可以在磁盘和tcp socket之间互相copy数据
开启gzip,会大量减少我们的发数据的量
开启nginx缓存,设置Web缓存区名称为cache_one,内存缓存空间大小为200MB,1天没有被访问的内容自动清除,硬盘缓存空间大小为30GB
具体配置项
#头部配置
user nginx nginx; #定义nginx的启动用户,不建议使用root
worker_processes 4; #定位为cpu的内核数量,因为我的环境配置是4核,所以就写4。不过这值最多也就是8,8个以上也就没什么意义了,想继续提升性能只能参考下面一项配置
worker_cpu_affinity 0001 0010 0100 1000; #此项配置为开启多核CPU,对你先弄提升性能有很大帮助nginx默认是不开启的,1为开启,0为关闭,因此先开启第一个倒过来写,
第一位0001(关闭第四个、关闭第三个、关闭第二个、开启第一个)
第二位0010(关闭第四个、关闭第三个、开启第二个、关闭第一个)
第三位0100(关闭第四个、开启第三个、关闭第二个、关闭第一个)
后面的依次类推,有智商的应该都可以看懂了吧? 那么如果是16核或者8核cpu,就注意为00000001、00000010、00000100,总位数与cpu核数一样。
error_log /data/logs/nginx/error.log crit; #这两项基本不用我说
pid /usr/local/nginx/nginx.pid;
#Specifies the value for maximum file descriptors that can be opened by this process.
worker_rlimit_nofile 65535; #这个值为nginx的worker进程打开的最大文件数,如果不配置,会读取服务器内核参数(通过ulimit -a查看),如果内核的值设置太低会让nginx报错(too many open
file),但是在此设置后,就会读取自己配置的参数不去读取内核参数
events
{
use epoll; #客户端线程轮询方法、内核2.6版本以上的建议使用epoll
worker_connections 65535; #设置一个worker可以打开的最大连接数
}
http {
include mime.types;
default_type application/octet-stream;
#charset gb2312;
server_tokens off; #为错误页面上的nginx版本信息,建议关闭,提升安全性
server_names_hash_bucket_size 128;
client_header_buffer_size 32k;
large_client_header_buffers 4 32k;
client_max_body_size 8m;
sendfile``on``; #开启sendfile()函数,sendfile可以再磁盘和tcp socket之间互相copy数据。
tcp_nopush ``on``; #告诉nginx在数据包中发送所有头文件,而不是一个一个的发
#keepalive_timeout 15;
keepalive_timeout 120;
tcp_nodelay``on``;
proxy_intercept_errors``on``;
fastcgi_intercept_errors``on``;
fastcgi_connect_timeout 1300;
fastcgi_send_timeout 1300;
fastcgi_read_timeout 1300;
fastcgi_buffer_size 512k;
fastcgi_buffers 4 512k;
fastcgi_busy_buffers_size 512k;
fastcgi_temp_file_write_size 512k;
proxy_connect_timeout 20s;
proxy_send_timeout 30s;
proxy_read_timeout 30s;
gzip``on``; #gzip是告诉nginx采用gzip后的数据来传输文件,会大量减少我们的发数据的量
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary``on``;
gzip_disable msie6;
#limit_zone crawler $binary_remote_addr 10m;
log_format main ``'$http_host $remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" '
'$request_time $upstream_response_time'``;
#proxy_temp_path和proxy_cache_path指定的路径必须在同一分区,因为它们之间是硬链接的关系
#proxy_temp_path /var/cache/nginx/proxy_temp_dir;
#设置Web缓存区名称为cache_one,内存缓存空间大小为200MB,1天没有被访问的内容自动清除,硬盘缓存空间大小为30GB。
#proxy_cache_path /var/cache/nginx/proxy_cache_dir levels=1:2 keys_zone=cache_one:200m inactive=1d max_size=30g;
include /usr/local/nginx/conf/vhosts/*.conf;
error_page 404 = https:``//www.niu.com/404/;
#error_page 500 502 503 504 = http://service.niu.com/alien/;
}
内核参数优化
如果是高并发架构,需要在nginx的服务器上添加如下的内核参数
这些参数追加到/etc/sysctl.conf,然后执行sysctl -p 生效。
-
每个网络接口接收数据包速度比内核处理速度快的时候,允许发送队列数目数据包的最大数
net.core.netdev_max_backlog = 262144
-
调节系统同时发起的tcp连接数
net.core.somaxconn = 262144
-
该参数用于设定系统中最多允许存在多少TCP套接字不被关联到任何一个用户文件句柄上,主要目的为防止Ddos攻击
net.ipv4.tcp_max_orphans = 262144
-
该参数用于记录尚未收到客户端确认信息的连接请求的最大值
-
net.ipv4.tcp_max_syn_backlog = 262144
-
nginx服务上建议关闭(既为0)
net.ipv4.tcp_timestamps = 0
-
该参数用于设置内核放弃TCP连接之前向客户端发送SYN+ACK包的数量,为了建立对端的连接服务,服务器和客户端需要进行三次握手,第二次握手期间,内核需要发送SYN并附带一个回应前一个SYN的ACK,这个参
数主要影响这个过程,一般赋予值为1,即内核放弃连接之前发送一次SYN+ACK包。net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
其他一些优化方面
. gzip压缩优化
. expires缓存
. 网络IO事件模型优化
. 隐藏软件名称和版本号
. 防盗链优化
. 禁止恶意域名解析
. 禁止通过IP地址访问网站
. HTTP请求方法优化
. 防DOS攻击单IP并发连接的控制,与连接速率控制
. 严格设置web站点目录的权限
. 将nginx进程以及站点运行于监牢模式
. 通过robot协议以及HTTP_USER_AGENT防爬虫优化
. 配置错误页面根据错误码指定网页反馈给用户
. nginx日志相关优化访问日志切割轮询,不记录指定元素日志、最小化日志目录权限
. 限制上传到资源目录的程序被访问,防止木马入侵系统破坏文件
. FastCGI参数buffer和cache配置文件的优化
. php.ini和php-fpm.conf配置文件的优化
. 有关web服务的Linux内核方面深度优化(网络连接、IO、内存等)
. nginx加密传输优化(SSL)
. web服务器磁盘挂载及网络文件系统的优化
. 使用nginx cache
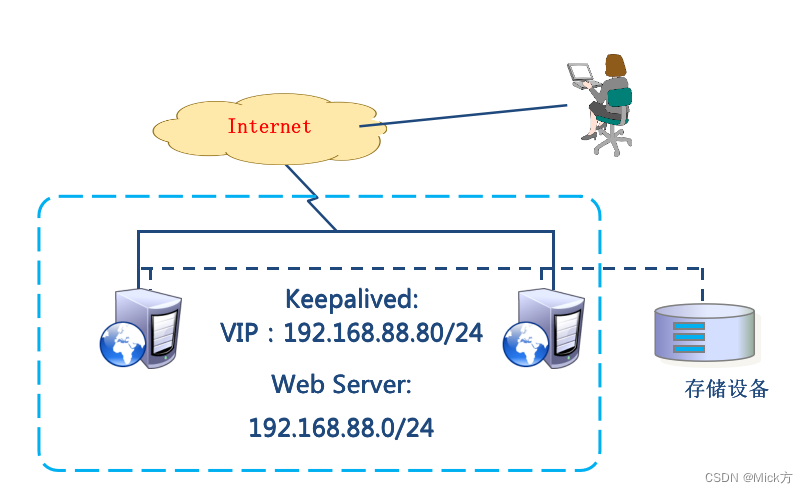
lvs,keepalive和nginx的关系
keepalived
keepalived是一个类似于layer3, 4 & 5交换机制的软件,也就是我们平时说的第3层、第4层和第5层交换。Keepalived是自动完成,不需人工干涉。
特点
自动完成,不需人工干涉
简介
Keepalived的作用是检测服务器的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。
工作原理
Layer3,4,5工作在IP/TCP协议栈的IP层,TCP层,及应用层,原理分别如下:
Layer3:Keepalived使用Layer3的方式工作式时,Keepalived会定期向服务器群中的服务器发送一个ICMP的数据包(既我们平时用的Ping程序),如果发现某台服务的IP地址没有激活,Keepalived便报告这台服务器失效,并将它从服务器群中剔除,这种情况的典型例子是某台服务器被非法关机。Layer3的方式是以服务器的IP地址是否有效作为服务器工作正常与否的标准。
Layer4:如果您理解了Layer3的方式,Layer4就容易了。Layer4主要以TCP端口的状态来决定服务器工作正常与否。如web server的服务端口一般是80,如果Keepalived检测到80端口没有启动,则Keepalived将把这台服务器从服务器群中剔除。
Layer5:Layer5对指定的URL执行HTTP GET。然后使用MD5算法对HTTP GET结果进行求和。如果这个总数与预期值不符,那么测试是错误的,服务器将从服务器池中移除。该模块对同一服务实施多URL获取检查。如果您使用承载多个应用程序服务器的服务器,则此功能很有用。此功能使您能够检查应用程序服务器是否正常工作。MD5摘要是使用genhash实用程序(包含在keepalived软件包中)生成的。
作用
Keepalived软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能。因此,Keepalived除了能够管理LVS软件外,还可以作为其他服务(例如:Nginx、Haproxy、MySQL等)的高可用解决方案软件。
Keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
所以,Keepalived 一方面具有配置管理LVS的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。
keepalived官网
lvs
负载均衡的类型
负载均衡可以采用硬件设备(例如常常听见的 F5),也可以采用软件负载
商用硬件负载设备成本通常较高(一台几十万甚至上百万),所以一般 情况下会采用软件负载
软件负载解决的两个核心问题是:选谁、转发,其中最著名的是 lvs
lvs 是什么?
英文全称是 Linux Virtual Server,即 Linux 虚拟服务器
由 章 文 嵩 博 士 发 起 的 自 由 软 件 项 目 , 它 的 官 方 站 点 是 www.linuxvirtualserver.org
Linux2.4 内核以后,LVS 已经是 Linux 标准内核的一部分
可以将请求分发给后端真实服务器处理
有许多比较著名网站和组织都在使用 LVS 架设的集群系统,例如:Linux 的门户网站(www.linux.com)、向 RealPlayer 提供音频视频服务而闻 名的 Real 公司(www.real.com )、全球最大的开源网站 (sourceforge.net)等。
调度算法
1.轮询调度
轮询调度(Round Robin 简称’RR’)算法就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是实现简单。轮询算法假设所有的服务器处理请求的能力都一样的,调度器会将所有的请求平均分配给每个真实服务器。
2.加权轮询调度
加权轮询(Weight Round Robin 简称’WRR’)算法主要是对轮询算法的一种优化与补充,LVS会考虑每台服务器的性能,并给每台服务器添加一个权值,如果服务器A的权值为1,服务器B的权值为2,则调度器调度到服务器B的请求会是服务器A的两倍。权值越高的服务器,处理的请求越多。
3.最小连接调度
最小连接调度(Least Connections 简称’LC’)算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态的调度算法,它通过服务器当前活跃的连接数来估计服务器的情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中断或者超时,其连接数减1。
(集群系统的真实服务器具有相近的系统性能,采用最小连接调度算法可以比较好地均衡负载。)
4.加权最小连接调度
加权最少连接(Weight Least Connections 简称’WLC’)算法是最小连接调度的超集,各个服务器相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
5.基于局部的最少连接
基于局部的最少连接调度(Locality-Based Least Connections 简称’LBLC’)算法是针对请求报文的目标IP地址的 负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和Cache命中率,从而提升整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则使用’最少连接’的原则选出一个可用的服务器,将请求发送到服务器。
6.带复制的基于局部性的最少连接
带复制的基于局部性的最少连接(Locality-Based Least Connections with Replication 简称’LBLCR’)算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统,它与LBLC算法不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。按’最小连接’原则从该服务器组中选出一一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按’最小连接’原则从整个集群中选出一台服务器,将该服务器加入到这个服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
7.目标地址散列调度
目标地址散列调度(Destination Hashing 简称’DH’)算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。
8.源地址散列调度U
源地址散列调度(Source Hashing 简称’SH’)算法先根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同,它的算法流程与目标地址散列调度算法的基本相似。
9.最短的期望的延迟
最短的期望的延迟调度(Shortest Expected Delay 简称’SED’)算法基于WLC算法。举个例子吧,ABC三台服务器的权重分别为1、2、3 。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用SED算法后会进行一个运算
A:(1+1)/1=2 B:(1+2)/2=3/2 C:(1+3)/3=4/3 就把请求交给得出运算结果最小的服务器。
10.最少队列调度
最少队列调度(Never Queue 简称’NQ’)算法,无需队列。如果有realserver的连接数等于0就直接分配过去,不需要在进行SED运算。
三种转发规则
NAT:简单理解,就是数据进出都通过 LVS,性能不是很好。
TUNL:简单理解:隧道 。
DR:最高效的负载均衡规则 。
NAT
NAT(Network Address Translation)即网络地址转换,其作用是通过数据报头的修改,使得位于企业内部的私有IP地址可以访问外网,以及外部用用户可以访问位于公司内部的私有IP主机。VS/NAT工作模式拓扑结构如图2所示,LVS负载调度器可以使用两块网卡配置不同的IP地址,eth0设置为私钥IP与内部网络通过交换设备相互连接,eth1设备为外网IP与外部网络联通。
第一步,用户通过互联网DNS服务器解析到公司负载均衡设备上面的外网地址,相对于真实服务器而言,LVS外网IP又称VIP(Virtual IP Address),用户通过访问VIP,即可连接后端的真实服务器(Real Server),而这一切对用户而言都是透明的,用户以为自己访问的就是真实服务器,但他并不知道自己访问的VIP仅仅是一个调度器,也不清楚后端的真实服务器到底在哪里、有多少真实服务器。
第二步,用户将请求发送至124.126.147.168,此时LVS将根据预设的算法选择后端的一台真实服务器(192.168.0.1~192.168.0.3),将数据请求包转发给真实服务器,并且在转发之前LVS会修改数据包中的目标地址以及目标端口,目标地址与目标端口将被修改为选出的真实服务器IP地址以及相应的端口。
第三步,真实的服务器将响应数据包返回给LVS调度器,调度器在得到响应的数据包后会将源地址和源端口修改为VIP及调度器相应的端口,修改完成后,由调度器将响应数据包发送回终端用户,另外,由于LVS调度器有一个连接Hash表,该表中会记录连接请求及转发信息,当同一个连接的下一个数据包发送给调度器时,从该Hash表中可以直接找到之前的连接记录,并根据记录信息选出相同的真实服务器及端口信息。
TUN
在LVS(NAT)模式的集群环境中,由于所有的数据请求及响应的数据包都需要经过LVS调度器转发,如果后端服务器的数量大于10台,则调度器就会成为整个集群环境的瓶颈。我们知道,数据请求包往往远小于响应数据包的大小。因为响应数据包中包含有客户需要的具体数据,所以LVS(TUN)的思路就是将请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端。VS/TUN工作模式拓扑结构如图3所示。其中,IP隧道(IP tunning)是一种数据包封装技术,它可以将原始数据包封装并添加新的包头(内容包括新的源地址及端口、目标地址及端口),从而实现将一个目标为调度器的VIP地址的数据包封装,通过隧道转发给后端的真实服务器(Real Server),通过将客户端发往调度器的原始数据包封装,并在其基础上添加新的数据包头(修改目标地址为调度器选择出来的真实服务器的IP地址及对应端口),LVS(TUN)模式要求真实服务器可以直接与外部网络连接,真实服务器在收到请求数据包后直接给客户端主机响应数据。
DR
在LVS(TUN)模式下,由于需要在LVS调度器与真实服务器之间创建隧道连接,这同样会增加服务器的负担。与LVS(TUN)类似,DR模式也叫直接路由模式,其体系结构如图4所示,该模式中LVS依然仅承担数据的入站请求以及根据算法选出合理的真实服务器,最终由后端真实服务器负责将响应数据包发送返回给客户端。与隧道模式不同的是,直接路由模式(DR模式)要求调度器与后端服务器必须在同一个局域网内,VIP地址需要在调度器与后端所有的服务器间共享,因为最终的真实服务器给客户端回应数据包时需要设置源IP为VIP地址,目标IP为客户端IP,这样客户端访问的是调度器的VIP地址,回应的源地址也依然是该VIP地址(真实服务器上的VIP),客户端是感觉不到后端服务器存在的。由于多台计算机都设置了同样一个VIP地址,所以在直接路由模式中要求调度器的VIP地址是对外可见的,客户端需要将请求数据包发送到调度器主机,而所有的真实服务器的VIP地址必须配置在Non-ARP的网络设备上,也就是该网络设备并不会向外广播自己的MAC及对应的IP地址,真实服务器的VIP对外界是不可见的,但真实服务器却可以接受目标地址VIP的网络请求,并在回应数据包时将源地址设置为该VIP地址。调度器根据算法在选出真实服务器后,在不修改数据报文的情况下,将数据帧的MAC地址修改为选出的真实服务器的MAC地址,通过交换机将该数据帧发给真实服务器。整个过程中,真实服务器的VIP不需要对外界可见。
lvs 的体系结构
最前端的负载均衡层,用 Load Balancer 表示
中间的服务器集群层,用 Server Array 表示
最底端的数据共享存储层,用 Shared Storage 表示
在用户看来,所有的内部应用都是透明的,用户只是在使用一个虚拟服 务器提供的高性能服务
和keepAlived 组合使用
因为所有的请求都要经过负载均衡,所以负载均衡必然是非常重要,不 能挂掉,说白了就是要 keep the lvs alived。
提供的功能就是可以配置 2 台 LVS,一台主机,一台备机。并且检测任 何一个节点是否还活着。
lvs 的优点
抗负载能力强,因为 lvs 工作方式的逻辑是非常之简单,而且工作在网络 4 层仅做请求分发之用,没有流量,所以在效率上基本不需要太过考虑。
有完整的双机热备方案,当节点出现故障时,lvs 会自动判别,所以系统整体是非常稳定的。
基本上能支持所有应用,因为 lvs 工作在 4 层,所以它可以对几乎所有应用做负载均衡,包括 http、数据库、聊天室等等。
lvs 负载均衡机制
lvs 是四层负载均衡,也就是说建立在 OSI 模型的第四层——传输层之 上
传输层上有 TCP/UDP,lvs 支持 TCP/UDP 的负载均衡
因为 LVS 是四层负载均衡,因此它相对于其它高层负载均衡的解决办法, 比如 DNS 域名轮流解析、应用层负载的调度、客户端的调度等,它的效 率是非常高的
lvs 的转发可以通过修改 IP 地址实现(NAT 模式)
lvs 的转发还可以通过修改直接路由实现(DR 模式)
lvs+keepAlived 的应用场景
大型网站负载均衡。
lvs 与 nginx 对比(简单)
负载度: lvs 优于 nginx
稳定度: lvs 优于 nginx
服务器性能要求: lvs 优于 nginx
网络层数的效率: lvs 优于 nginx(网络七层:应用层、会话层、表示层、传输层、网络层、链路层、 物理层)
功能多少 : nginx 优于 lvs
lvs与nginx区别(深度)
lvs和nginx都可以用作多机负载方案,他们各有优缺点,在生产环境中需要好好分析实际情况并加以利用。
一、lvs的优势
1.抗负载能力强,因为lvs工作方式的逻辑是非常简单的,而且工作再网络层第4层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。lvs一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU等)出现问题导致lvs出现问题。
2.配置性地,这通常是一大劣势同时也是一大优势,因为没有太多的可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率。
3.工作稳定,因为其本省抗负载能力很强,所以稳定性高也是顺理成章的事,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体式非常稳定的。
4.无流量,lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5.lvs基本上能支持所有应用,因为绿色工作在第4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等。
另外:lvs也不是完全能判别节点故障的,比如在wlc分配方式下,集群里有一个节点没有配置vip,会使整个集群不能使用,这时使用wrr分配方式则会丢掉一台机器。目前这个问题还在进一步测试中。所以用lvs也得多多当心为妙。
二、nginx和lvs作对比的结果
1.nginx工作在网络的第7层,所以它可以针对http应用本身来做分流策略,比如针对域名、目录结构等,相比之下lvs并不具备这样的功能,所以nginx单凭这点可以利用的场合就远多于lvs了;但nginx有用的这些功能使其可调整度要高于lvs,所以经常要去触碰触碰,由lvs的第2条优点来看,触碰多了,人为出现问题的几率也就会大。
2.nginx对网络的依赖较小,理论上只要ping得通,网页访问正常,nginx就能连得通,nginx同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;lvs就比较依赖于网络环境,目前来看服务器在同一网段内并且lvs使用direct方式分流,效果较能得到保证。另外注意,lvs需要向托管商至少申请多于一个ip来做visual ip,貌似是不能用本省的ip来做VIP的。要做好lvs管理员,确实得跟进学习很多有关网络通信方面的知识,就不再是一个http那么简单了。
3.nginx安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。lvs的安装和配置、测试就要花比较长的时间,因为同上所述,lvs对网络依赖性比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦的多。
4.nginx也同样能承受很高负载且稳定,但负载度很稳定度差lvs还有几个等级:nginx处理所有流量所以受限于机器IO和配置;本身的bug也还是难以避免的;nginx没有现成的双机热备方案,所以跑在单机上还是风险比较大,单机上的事情全都很难说。
5.nginx可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前lvs中ldirectd也能支持针对服务器内部的情况来监控,但lvs的原理使其不能重发请求。重发请求这点,比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx会把上传切到另一台服务器重新处理,而lvs就直接断掉了,如果是上传一个很大的文件或者很重要的文件的话,用户可能会因此而恼火。
6.nginx对请求的异步处理可以帮助节点服务器减轻负载,键入使用Apache直接对外服务,那么出现很多的窄带链接时Apache服务器将会占用大量内存而不能释放,使用多于一个nginx做Apache代理的话,这些窄带链接会被nginx挡住,Apache上就不会堆积过多的请求,这样就减少了相当多的内存占用。这点使用squid也有相同的作用,即使squid本身配置为不缓存,对Apache还是有很大帮助你的。lvs没有这些功能,也就无法能比较。
7.nginx能支持http和Email(Email的功能估计比较少人用),lvs所支持的应用在这点上会比nginx更过。
在使用上,一般最前端所采取的的策略应是lvs,也就是dns的指向应为lvs均衡器,lvs的优点另它非常适合做这个任务。
重要的ip地址,最好交由lvs托管,比如数据库的ip、webservice服务器的ip等等,这些ip地址随着时间推移,使用面会越来越大,如果更换ip则故障会接踵而来。所以将这些重要ip交给lvs托管式最为稳妥的,这样做的唯一缺点是需要VIP数量会比较多。
nginx可以作为lvs节点机器使用,一是可以利用nginx的功能,二是可以利用nginx的性能。当然这一层面也可以直接使用squid,squid的功能方面就比nginx弱不少,性能上也有所逊色于nginx。
nginx也可以作为中层代理使用,这一层面nginx基本上无对手,唯一可以撼动nginx的就只有lighttpd了,不过lighttpd目前还没有能做到nginx完全的功能,配置也不那么清晰易读。另外,中层代理的ip也是重要的,所以中层代理业拥有一个VIP和lvs是最完美的方案了。
nginx也可以作为网页静态服务器。
具体的应用还得具体分析,如果是比较小的网站(日pv<1000万),用nginx就完全可以了,如果机器也不少,可以用dns轮询,lvs所耗费的机器还是比较多的;大型网站或者重要的服务,机器不发愁的时候要多多考虑利用lvs。
说明
使用nginx+keepalived实现负载均衡,解决单点与高流量并发问题。为什么要用nginx而不用lvs?
7个理由:
1.高并发连接:官方测试能够支撑5万并发连接,在实际生产环境中跑到2——3万并发连接数。
2.内存消耗少:在3万并发连接数下,开启的10个nginx进程才消耗150M内存(150*10=150M)。
3.配置文件非常简单:风格跟程序一样通俗易懂。
4.成本低廉:nginx为开源软件,可以免费使用。而购买F5 big-ip、netscaler等硬件负载均衡交换机则需要十多万至几十万人民币。
(使用nginx做七层负载均衡的理由?)
5.支持rewrite重写规则:能够根据域名、url的不同,将http请求分到不同的后端服务器群组。
6.内置的健康检查功能:如果nginx proxy后端的某台web服务器宕机了,不会影响前端访问。
7.节省带宽:支持gzip压缩,可以添加浏览器本地缓存的header头。
进一步说明
keepalived是linux下面实现vrrp备份路由的高可靠性运行件。基于keepalived设计的服务模式能够真正做到主服务器和备份服务器故障时ip瞬间无缝交接。
nginx是基于linux2.6内核中epoll模型http服务器,与Apache进程派生模式不同的是nginx进程基于master+slave多进程模型,自身具有非常稳定的子进程管理功能。在master进程分配模式下,master进程永远不进行业务处理,只是进行任务分发,从而达到master进程的存活高可靠性,slave进程所有的业务信号都由主进程发出,slave进城所有的超时任务都会被master终止,属于阻塞式人物模型。
服务器ip存活检测是由keepalived自己本身完成的,将2台服务器配置成keepalived互为主辅关系,任意一方机器故障对方都能够将ip接管过去。
keepalived的服务器ip通过其配置文件进行管理,依靠其自身的进程去确定服务器的存活状态,如果在需要对服务器进程在线维护的情况下,只需要停掉被维护机器的keepalived服务进程,另外一台服务器就能够接管该台服务器的所有应用。
现实意义
nginx实现了web服务器的高可用,如果流量入口的nginx服务器挂了,那么就web服务不可用了。
所以在nginx做负载均衡之前,用lvs做osi网络协议的四层负载均衡,实现nginx的高可用。lvs主要解决的是这个问题。
nginx配置https
#server端基本配置 server {
listen 80;
listen 443 ssl spdy;
server_name io.123.com;
include ssl/io.com; #注意看下一个文件
location / {
proxy_pass http:``//lb_io;
if``($scheme = http ) {
return``301 https:``//$host$request_uri; #此项配置为转换为https的基本配置
}
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection``"upgrade"``;
}
access_log /data/logs/nginx/access/niuaero.log main;
}
ssl_certificate ssl/ca/io.com.pem; #这个为购买的https证书,供应商会生成
ssl_certificate_key ssl/ca/io.com.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
#启用TLS1.1、TLS1.2要求OpenSSL1.0.1及以上版本,若您的OpenSSL版本低于要求,请使用 ssl_protocols TLSv1;
ssl_ciphers HIGH:!RC4:!MD5:!aNULL:!eNULL:!NULL:!DH:!EDH:!EXP:+MEDIUM;
ssl_prefer_server_ciphers ``on``;
nginx配置反爬虫
#以下内容添加nginx虚拟主机配置里,proxypass之后
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return``403;
}
#禁止指定UA及UA为空的访问
if(KaTeX parse error: Expected group after ‘^’ at position 413: …ts|Linguee Bot|^̲“) {
return 403; `
}
#禁止非GET|HEAD|POST方式的抓取
if`($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
nginx日志分析
Nginx日志格式
$remote_addr –
r
e
m
o
t
e
u
s
e
r
[
remote_user [
remoteuser[time_local] “$request” $status
b
o
d
y
b
y
t
e
s
s
e
n
t
”
body_bytes_sent ”
bodybytessent“http_referer” “
h
t
t
p
u
s
e
r
a
g
e
n
t
”
”
http_user_agent” ”
httpuseragent“”http_x_forwarded_for”’
1)统计日志中访问最多的10个IP
思路:对第一列进行去重,并输出出现的次数
方法1:
awk '{a[$1]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
方法2:
awk ‘{print $1}’ access.log |sort |uniq -c |sort -k1 -nr |head -n10
说明:a[$1]++ 创建数组a,以第一列作为下标,使用运算符++作为数组元素,元素初始值为0。处理一个IP时,下标是IP,元素加1,处理第二个IP时,下标是IP,元素加1,如果这个IP已经存在,则元素再加1,也就是这个IP出现了两次,元素结果是2,以此类推。因此可以实现去重,统计出现次数。
2)统计日志中访问大于100次的IP
方法1:awk ‘{a[$1]++}END{for(i in a){if(a[i]>100)print i,a[i]}}’ access.log
方法2:awk ‘{a[$1]++;if(a[$1]>100){b[$1]++}}END{for(i in b){print i,a[i]}}’ access.log
说明:方法1是将结果保存a数组后,输出时判断符合要求的IP。方法2是将结果保存a数组时,并判断符合要求的IP放到b数组,最后打印b数组的IP。
3)统计2019年3月14日一天内访问最多的10个IP
思路:先过滤出这个时间段的日志,然后去重,统计出现次数
方法1:awk ‘$4>=“[14/Mar/2019:00:00:01” && $4<=“[14/Mar/2019:23:59:59” {a[$1]++}END{for(i in a)print a[i],i|“sort -k1 -nr|head -n10”}’ access.log
方法2: sed -n ‘/[14/Mar/2019:00:00:01/,/[14/Mar/2019:23:59:59/p’ access.log |sort |uniq -c |sort -k1 -nr |head -n10 #前提开始时间与结束时间日志中必须存在
4)统计访问最多的前10个页面($request)
awk ‘{a[$7]++}END{for(i in a)print a[i],i|“sort -k1 -nr|head -n10”}’ access.log
5)统计每个URL访问内容的总大小($body_bytes_sent)
awk ‘{a[$7]++;size[$7]+=$10}END{for(i in a)print a[i],size[i],i}’ access.log
6)统计每个IP访问状态码数量($status)
awk ‘{a[$1″ “$9]++}END{for(i in a)print i,a[i]}’ access.log
7)统计访问状态码为404的IP及出现次数
awk ‘{if($9~/404/)a[$1″ “$9]++}END{for(i in a)print i,a[i]}’ access.log
优化Nginx中FastCGI参数
优化项
fastcgi_cache_path/usr/local/nginx/fastcgi_cache levels=1:2keys_zone=TEST:10minactive=5m;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 464k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;fastcgi_cache TEST;fastcgi_cache_valid 2003021h;fastcgi_cache_valid 3011d;fastcgi_cache_valid any 1m;
说明
第一行是为FastCGI缓存指定一个文件路径、目录结构等级、关键字区域存储时间和非活动删除时间。
fastcgi_connect_timeout指定连接到后端FastCGI的超时时间。
fastcgi_send_timeout指定向FastCGI传送请求的超时时间,这个值是已经完成两次握手后向FastCGI传送请求的超时时间。
fastcgi_read_timeout指定接收FastCGI应答的超时时间,这个值是已经完成两次握手后接收FastCGI应答的超时时间。
fastcgi_buffer_size用于指定读取FastCGI应答第一部分需要用多大的缓冲区,这个值表示将使用1个64KB的缓冲区读取应答的第一部分(应答头),可以设置为fastcgi_buffers选项指定的缓冲区大小。
fastcgi_buffers指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求。如果一个PHP脚本所产生的页面大小为256KB,那么会为其分配4个64KB的缓冲区来缓存;如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于硬盘。一般这个值应该为站点中PHP脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“16 16k”、“4 64k”等。
fastcgi_busy_buffers_size的默认值是fastcgi_buffers的两倍。
fastcgi_temp_file_write_size表示在写入缓存文件时使用多大的数据块,默认值是fastcgi_buffers的两倍。
fastcgi_cache表示开启FastCGI缓存并为其指定一个名称。开启缓存非常有用,可以有效降低CPU的负载,并且防止502错误的发生,但是开启缓存也会引起很多问题,要视具体情况而定。
fastcgi_cache_valid、fastcgi用来指定应答代码的缓存时间,实例中的值表示将200和302应答缓存一个小时,将301应答缓存1天,其他应答均缓存1分钟。
原文地址:https://blog.csdn.net/weixin_46651125/article/details/131807718
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_50755.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!