本文介绍: 这篇论文的框架已经过时,在量化和分词上面有借鉴性
一、论文解读
Google’s Neural Machine Translation system简称GNMT,是一个深度LSTM网络,其由8层编码器和8层解码器组成;在这个深层LSTM网络中,层与层之间使用残差连接,解码器和编码器使用注意力机制连接;
wordpiece在“character”分隔模型的灵活性和“word”分隔模型的效率之间提供了很好的平衡,自然地处理罕见词的翻译,最终提高了系统的整体精度
该结果与与谷歌的之前的翻译系统相比,该模型平均减少了60%的翻译错误;我想这就是是谷歌抛弃传统翻译方法拥抱神经网络的最主要的原因之一吧;
1.1 模型介绍
神经机器翻译的架构通常由两个递归神经网络组成,(2017年的Transformer就打你的脸;),一个用于输入文本,一个用于输出文本;通常存在以下几个问题:训练和推理速度较慢(Transformer),无法处理罕见的单词无效,有时无法翻译源句中的所有单词(wordpiece);
传统的翻译系统基本都是基于Statistical Machine Translation (SMT)统计机器翻译,主要的应用都是 在翻译短文本上;在神经网络出现优势之前,统计机器翻译就集合了神经机器翻译,直到后来的一篇论文Addressing the rare word problem in neural machine translation中发现使用某架构的神经机器翻译模型的效果要好于传统机器翻译,神经机器翻译迎来了许多的新技术;
1.2 模型架构
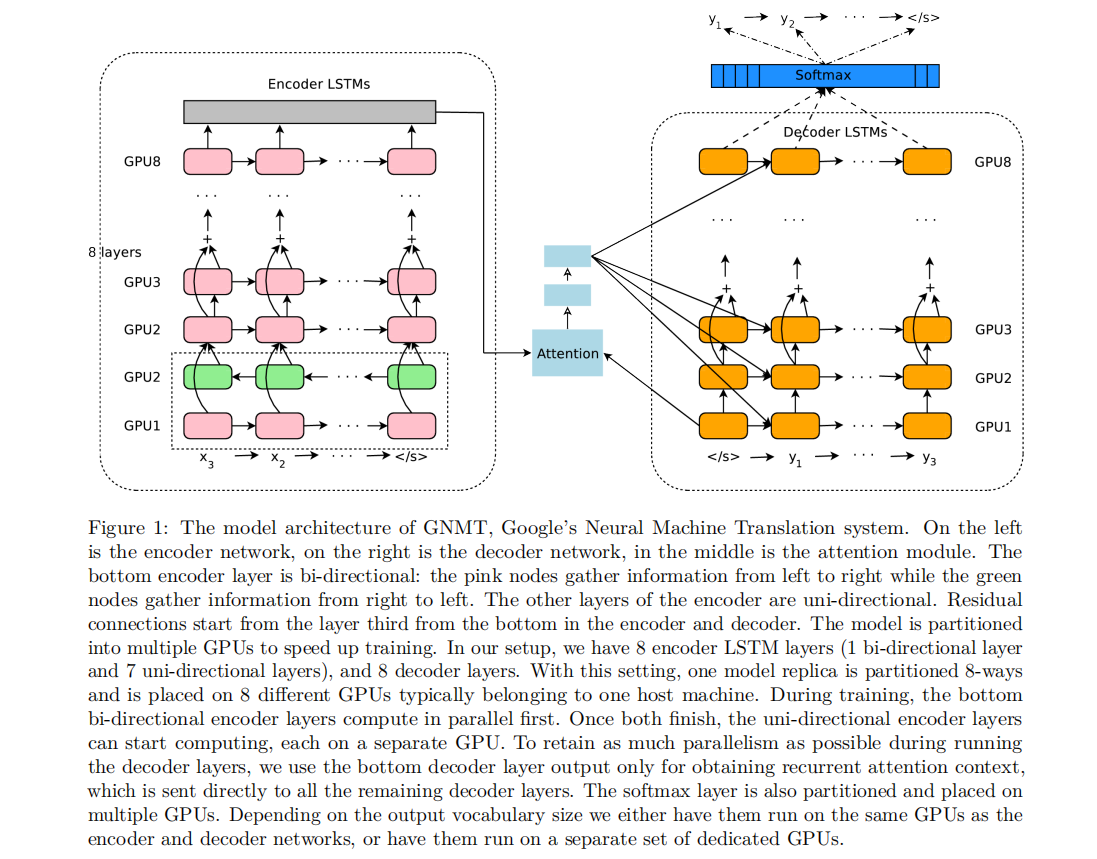

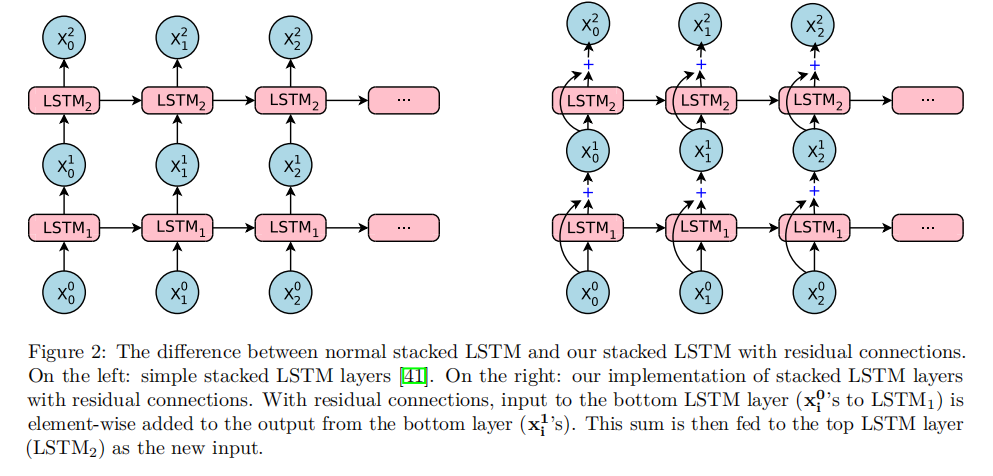
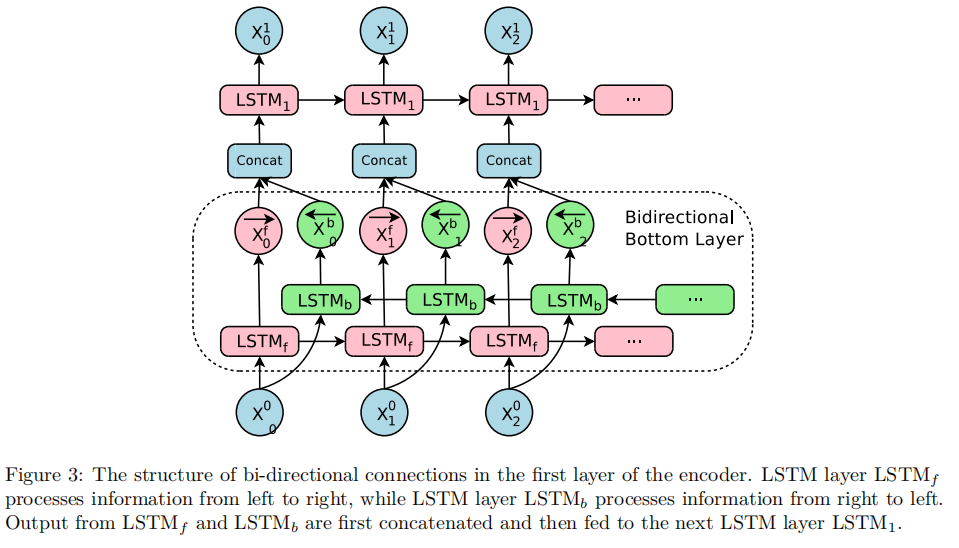
1.3 wordpiece

二、整体总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





