系列文章目录
第一章 Java线程池技术应用
第二章 CountDownLatch和Semaphone的应用
第三章 Spring Cloud 简介
第四章 Spring Cloud Netflix 之 Eureka
第五章 Spring Cloud Netflix 之 Ribbon
第六章 Spring Cloud 之 OpenFeign
第七章 Spring Cloud 之 GateWay
第八章 Spring Cloud Netflix 之 Hystrix
第九章 代码管理gitlab 使用
第十章 SpringCloud Alibaba 之 Nacos discovery
第十一章 SpringCloud Alibaba 之 Nacos Config
第十二章 Spring Cloud Alibaba 之 Sentinel
第十三章 JWT
第十四章 RabbitMQ应用
第十五章 RabbitMQ 延迟队列
第十六章 spring-cloud-stream
第十七章 Windows系统安装Redis、配置环境变量
第十八章 查看、修改Redis配置,介绍Redis类型
推荐一个人工智能学习网站:AI 人工智能



文章目录
前言
本章节讲解如何查看、修改Redis配置,介绍Redis类型。
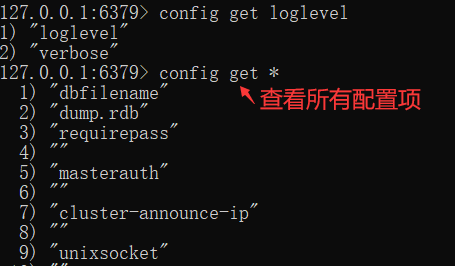
1、查看配置
config get 配置名称
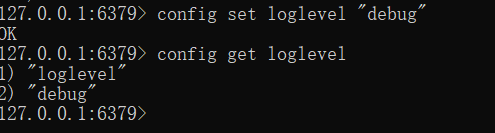
2、修改配置项
config set 配置项名称 配置项值
2.1、配置项说明
| 配置项 | 参数 | 说明 |
|---|---|---|
| daemonize | no/yes | 默认为 no,表示 Redis 不是以守护进程的方式运行,通过修改为 yes 启用守护进程。 |
| pidfile | 文件路径 | 当 Redis 以守护进程方式运行时,会把进程 pid 写入自定义的文件中。 |
| port | 6379 | 指定 Redis 监听端口,默认端口为 6379。 |
| bind | 127.0.0.1 | 绑定的主机地址。 |
| timeout | 0 | 客户端闲置多长秒后关闭连接,若指定为 0 ,表示不启用该功能。 |
| loglevel | notice | 指定日志记录级别,支持四个级别:debug、verbose、notice、warning,默认为 notice。 |
| logfile | stdout | 日志记录方式,默认为标准输出。 |
| databases | 16 | 设置数据库的数量(0-15个)共16个,Redis 默认选择的是 0 库,可以使用 SELECT 命令来选择使用哪个数据库储存数据。 |
| save[seconds] [changes] |
可以同时配置三种模式: save 900 1 save 300 10 save 60 10000 |
表示在规定的时间内,执行了规定次数的写入或修改操作,Redis 就会将数据同步到指定的磁盘文件中。比如 900s 内做了一次更改,Redis 就会自动执行数据同步。
|
| rdbcompression | yes/no | 当数据存储至本地数据库时是否要压缩数据,默认为 yes。 |
| dbfilename | dump.rdb | 指定本地存储数据库的文件名,默认为 dump.rdb。 |
| dir | ./ | 指定本地数据库存放目录。 |
| slaveof | 主从复制配置选项 | 当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动与 master 主机进行数据同步。 |
| requirepass | foobared 默认关闭 | 密码配置项,默认关闭,用于设置 Redis 连接密码。如果配置了连接密码,客户端连接 Redis 时需要通过 密码认证。 |
| maxmemory | 最大内存限制配置项 | 指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会尝试清除已到期或即将到期的 Key,当此方法处理 后,若仍然到达最大内存设置,将无法再进行写入操作,但可以进行读取操作。 |
| appendfilename | appendonly.aof | 指定 AOF 持久化时保存数据的文件名,默认为 appendonly.aof。 |
| glueoutputbuf | yes | 设置向客户端应答时,是否把较小的包合并为一个包发送,默认开启状态。 |
2.2、配置支持远程访问
打开redis.windows.conf
将bind 127.0.0.1 改成 bind 0.0.0.0
将 protected-mode yes 修改为 protected-mode no
改成要求输入密码:
requirepass 123456
重新启动redis
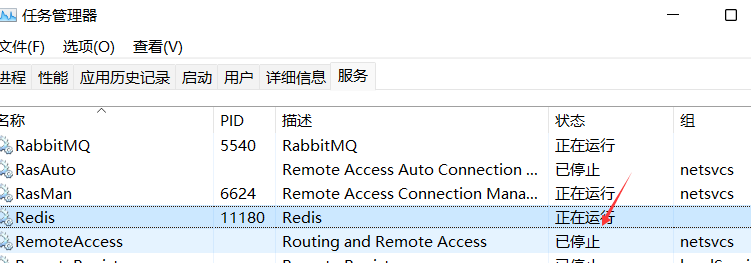
下载客户端工具:RedisDesktopManager
新增连接连接redis
3、数据类型
- string(字符串)
- hash(哈希散列)
- list(列表)
- set(集合)
- zset(sorted set:有序集合)
3.1、String
String 是 Redis 最基本的数据类型。字符串是一组字节,在 Redis 数据库中,字符串具有二进制安全(binary safe)特性,这意味着它的长度是已知的,不由任何其他终止字符决定的,一个字符串类型的值最多能够存储 512 MB 的内容。

一次存储多个值

String存储结构SDS(Simple Dynamic String)即简单动态字符串)
SDS 的结构定义如下:
struct sdshdr{
//记录buf数组中已使用字符的数量,等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用的字符数量
int free;
//字符数组,用于保存字符串
char buf[];
}
分配冗余空间
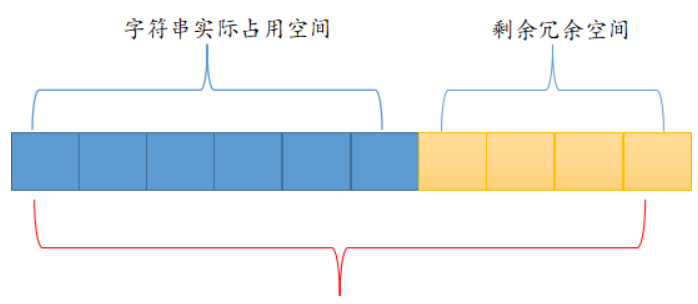
3.1.1、string扩容规则
当字符串所占空间小于 1MB 时,Redis 对字符串存储空间的扩容是以成倍的方式增加的;而当所占空间超过 1MB 时,每次扩容只增加 1MB。Redis 字符串允许的最大值字节数是 512 MB。
3.1.2、字符串命令
SET key value [EX seconds|PX milliseconds] [NX|XX]
其中[]内代表可选参数,其含义如下所示:
EX seconds:设置指定的过期时间,以秒为单位;
PX milliseconds:设置指定的过期时间,以毫秒为单位;
NX:先判断 key 是否存在,如果 key 不存在,则设置 key 与 value;
XX:先判断 key 是否存在,如果 key 存在,则重新设置 value。
3.1.3、string 常用命令
| 命令 | 说明 |
|---|---|
| SET key value | 用于设定指定键的值。 |
| GET key | 用于检索指定键的值。 |
| GETRANGE key start end | 返回 key 中字符串值的子字符。 |
| GETSET key value | 将给定 key 的值设置为 value,并返回 key 的旧值。 |
| GETBIT key offset | 对 key 所存储的字符串值,获取其指定偏移量上的位(bit)。 |
| MGET key1 [key2…] | 批量获取一个或多个 key 所存储的值,减少网络耗时开销。 |
| SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| SETEX key seconds value | 将值 value 存储到 key中 ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| SETNX key value | 当 key 不存在时设置 key 的值。 |
| SETRANGE key offset value | 从偏移量 offset 开始,使用指定的 value 覆盖的 key 所存储的部分字符串值。 |
| STRLEN key | 返回 key 所储存的字符串值的长度。 |
| MSET key value [key value …] | 该命令允许同时设置多个键值对。MSETNX key value [key value …]当指定的 key 都不存在时,用于设置多个键值对。 |
| PSETEX key milliseconds value | 此命令用于设置 key 的值和有过期时间(以毫秒为单位)。 |
| INCR key | 将 key 所存储的整数值加 1。 |
| INCRBY key increment | 将 key 所储存的值加上给定的递增值(increment)。 |
| INCRBYFLOAT key increment | 将 key 所储存的值加上指定的浮点递增值(increment)。 |
| DECR key | 将 key 所存储的整数值减 1。 |
| DECRBY key decrement | 将 key 所储存的值减去给定的递减值(decrement)。 |
| APPEND key value | 该命令将 value 追加到 key 所存储值的末尾。 |
3.2、Hash
hash 散列是由字符串类型的 field 和 value 组成的映射表,您可以把它理解成一个包含了多个键值对的集合。由于 Hash 类型具有上述特点,所以一般被用来存储对象。
语法:hmset key field value [field value …]

3.2.1、数据存储
第一种:当存储的数据量较少的时,hash 采用 ziplist 作为底层存储结构,此时要求符合以下两个条件:
- 哈希对象保存的所有键值对(键和值)的字符串长度总和小于 64 个字节。
- 哈希对象保存的键值对数量要小于 512 个。
第二种:不满足第一种,采用 dict(字典结构),该结构类似于 Java 的 HashMap,是一个无序的字典,并采用了数组和链表相结合的方式存储数据
3.2.2、常用命令
| 命令 | 说明 |
|---|---|
| HDEL key field2 [field2] | 用于删除一个或多个哈希表字段。 |
| HEXISTS key field | 用于确定哈希表字段是否存在。 |
| HGET key field | 获取 key 关联的哈希字段的值。 |
| HGETALL key | 获取 key 关联的所有哈希字段值。 |
| HINCRBY key field increment | 给 key 关联的哈希字段做整数增量运算 。 |
| HINCRBYFLOAT key field increment | 给 key 关联的哈希字段做浮点数增量运算 。 |
| HKEYS key | 获取 key 关联的所有字段和值。 |
| HLEN key | 获取 key 中的哈希表的字段数量。 |
| HMSET key field1 value1 [field2 value2 ] | 在哈希表中同时设置多个 field-value(字段-值) |
| HMGET key field1 [field2] | 用于同时获取多个给定哈希字段(field)对应的值。 |
| HSET key field value | 用于设置指定 key 的哈希表字段和值(field/value)。 |
| HSETNX key field value | 仅当字段 field 不存在时,设置哈希表字段的值。 |
| HVALS key | 用于获取哈希表中的所有值。 |
| HSCAN key cursor | 迭代哈希表中的所有键值对,cursor 表示游标,默认为 0。 |
3.3、list
Redis List 中的元素是字符串类型,其中的元素按照插入顺序进行排列,允许重复插入
lpush key 元素值

当列表中存储的元素较少时,Redis 会使用一块连续的内存来存储这些元素,这个连续的结构被称为 ziplist(压缩列表),它将所有的元素紧挨着一起存储。而当数据量较大时,Redis 列表就会是用 quicklist(快速链表)存储元素。

3.3.1、常用命令
| 命令 | 说明 |
|---|---|
| LPUSH key value1 [value2] | 在列表头部插入一个或者多个值。 |
| LRANGE key start stop | 获取列表指定范围内的元素。 |
| RPUSH key value1 [value2] | 在列表尾部添加一个或多个值。 |
| LPUSHX key value | 当储存列表的 key 存在时,用于将值插入到列表头部。 |
| RPUSHX key value | 当存储列表的 key 存在时,用于将值插入到列表的尾部。 |
| LINDEX key index | 通过索引获取列表中的元素。 |
| LINSERT key before | after pivot value |
| LREM key count value | 表示从列表中删除元素与 value 相等的元素。count 表示删除的数量,为 0 表示全部移除。 |
| LSET key index value | 表示通过其索引设置列表中元素的值。 |
| LTRIM key start stop | 保留列表中指定范围内的元素值。 |
| LPOP key | 从列表的头部弹出元素,默认为第一个元素。 |
| RPOP key | 从列表的尾部弹出元素,默认为最后一个元素。 |
| LLEN key | 用于获取列表的长度。 |
| RPOPLPUSH source destination | 用于删除列表中的最后一个元素,然后将该元素添加到另一个列表的头部,并返回该元素值。 |
| BLPOP key1 [key2 ] timeout | 用于删除并返回列表中的第一个元素(头部操作),如果列表中没有元素,就会发生阻塞,直到列表等待超时或发现可弹出元素为止。 |
| BRPOP key1 [key2 ] timeout | 用于删除并返回列表中的最后一个元素(尾部操作),如果列表中没有元素,就会发生阻塞, 直到列表等待超时或发现可弹出元素为止。 |
| BRPOPLPUSH source destination timeout | 从列表中取出最后一个元素,并插入到另一个列表的头部。如果列表中没有元素,就会发生阻塞,直到等待超时或发现可弹出元素时为止。 |
3.4、set
Redis Set 是一个字符串类型元素构成的无序无重复集合。
添加元素:sadd key 元素值
查看set的值:smembers key

Redis set 采用了两种方式相结合的底层存储结构,分别是 intset(整型数组)与 hash table(哈希表),当 set 存储的数据满足以下要求时,使用 intset 结构:
- 集合内保存的所有成员都是整数值;
- 集合内保存的成员数量不超过 512 个。
当不满足上述要求时,则使用 hash table 结构。
3.4.1、常用命令
| 命令 | 说明 |
|---|---|
| SADD key member1 [member2] | 向集合中添加一个或者多个元素,并且自动去重。 |
| SCARD key | 返回集合中元素的个数。 |
| SDIFF key1 [key2] | 求两个或多个集合的差集。 |
| SDIFFSTORE destination key1 [key2] | 求两个集合或多个集合的差集,并将结果保存到指定的集合中。 |
| SINTER key1 [key2] | 求两个或多个集合的交集。 |
| SINTERSTORE destination key1 [key2] | 求两个或多个集合的交集,并将结果保存到指定的集合中。 |
| SISMEMBER key member | 查看指定元素是否存在于集合中。 |
| SMEMBERS key | 查看集合中所有元素。 |
| SMOVE source destination member | 将集合中的元素移动到指定的集合中。 |
| SPOP key [count] | 弹出指定数量的元素。 |
| SRANDMEMBER key [count] | 随机从集合中返回指定数量的元素,默认返回 1个。 |
| SREM key member1 [member2] | 删除一个或者多个元素,若元素不存在则自动忽略。 |
| SUNION key1 [key2] | 求两个或者多个集合的并集。 |
| SUNIONSTORE destination key1 [key2] | 求两个或者多个集合的并集,并将结果保存到指定的集合中。 |
| SSCAN key cursor [match pattern] [count count] | 该命令用来迭代的集合中的元素。 |
3.5、zset有序集合
Redis zset 是一个字符串类型元素构成的有序集合,集合中的元素不仅具有唯一性,而且每个元素还会关联一 个 double 类型的分数,该分数允许重复。

有序集合(zset)同样使用了两种不同的存储结构,分别是 zipList(压缩列表)和 skipList(跳跃列表),当 zset 满足以下条件时使用压缩列表:
- 成员的数量小于128 个;
- 每个 member (成员)的字符串长度都小于 64 个字节。
3.5.1、常用命令
| 命令 | 说明 |
|---|---|
| ZADD key score1 member1 [score2 member2] | 用于将一个或多个成员添加到有序集合中,或者更新已存在成员的 score 值 |
| ZCARD key | 获取有序集合中成员的数量 |
| ZCOUNT key min max | 用于统计有序集合中指定 score 值范围内的元素个数。 |
| ZINCRBY key increment member | 用于增加有序集合中成员的分值。 |
| ZINTERSTORE destination numkeys key [key …] | 求两个或者多个有序集合的交集,并将所得结果存储在新的 key 中。 |
| ZLEXCOUNT key min max | 当成员分数相同时,计算有序集合中在指定词典范围内的成员的数量。 |
| ZRANGE key start stop [WITHSCORES] | 返回有序集合中指定索引区间内的成员数量。 |
| ZRANGEBYLEX key min max [LIMIT offset count] | 返回有序集中指定字典区间内的成员数量。 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 返回有序集合中指定分数区间内的成员。 |
| ZRANK key member | 返回有序集合中指定成员的排名。 |
| ZREM key member [member …] | 移除有序集合中的一个或多个成员。 |
| ZREMRANGEBYLEX key min max | 移除有序集合中指定字典区间的所有成员。 |
| ZREMRANGEBYRANK key start stop | 移除有序集合中指定排名区间内的所有成员。 |
| ZREMRANGEBYSCORE key min max | 移除有序集合中指定分数区间内的所有成员。 |
| ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到低。 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序。 |
| ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序。 |
| ZSCORE key member | 返回有序集中,指定成员的分数值。 |
| ZUNIONSTORE destination numkeys key [key …] | 求两个或多个有序集合的并集,并将返回结果存储在新的 key 中。 |
| ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(包括元素成员和元素分值)。 |
备注:
压缩列表ziplist五部分组成,如图所示:
上述每一部分在内存中都是紧密相邻的,并承担着不同的作用,介绍如下:
- zlbytes 是一个无符号整数,表示当前 ziplist 占用的总字节数;
- zltail 指的是压缩列表尾部元素相对于压缩列表起始元素的偏移量。
- zllen 指 ziplist 中 entry 的数量。当 zllen 比2^16 – 2大时,需要完全遍历 entry 列表来获取 entry 的总数目。
- entry 用来存放具体的数据项(score和member),长度不定,可以是字节数组或整数,entry 会根据成员的数量自动扩容。
- zlend 是一个单字节的特殊值,等于 255,起到标识 ziplist 内存结束点的作用。
原文地址:https://blog.csdn.net/s445320/article/details/134432937
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_51241.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!