本文介绍: 本篇博客将介绍如何使用爬虫技术来免费获取百度文库收费PPT的方法。百度文库上有许多精彩的PPT资源,但大多数需要付费才能下载。对于那些希望以免费方式获取所需资源的用户来说,这篇博客将为他们提供解决方案。通过使用Python的爬虫技术和相关工具,我们可以自动化地获取这些收费PPT,无需支付任何费用。在博客中,将介绍爬取网页内容、提取目标链接以及下载PPT的具体步骤。此外,还会强调合法性和道德准则的重要性,确保我们在使用爬虫技术时遵守法律和尊重版权。
背景:
某度上有很多优质的PPT资源和文档资源,但是大多数需要付费才能获取。对于一些经济有限的用户来说,这无疑是个遗憾,因为我们更倾向于以免费的方式获取所需资源。
解决方案:
然而,幸运的是,我们可以通过一些技巧和工具来实现免费获取PPT的目标。使用一些爬虫技术和数据抓取工具,我们可以自动化地获取这些收费PPT,无需付费就能获得所需资源。一句话,我要白嫖白嫖!!!
实现:
步骤1:
爬取pptx中的所有图片:
比如这个网页的ppt。
我们接下来看看结果:
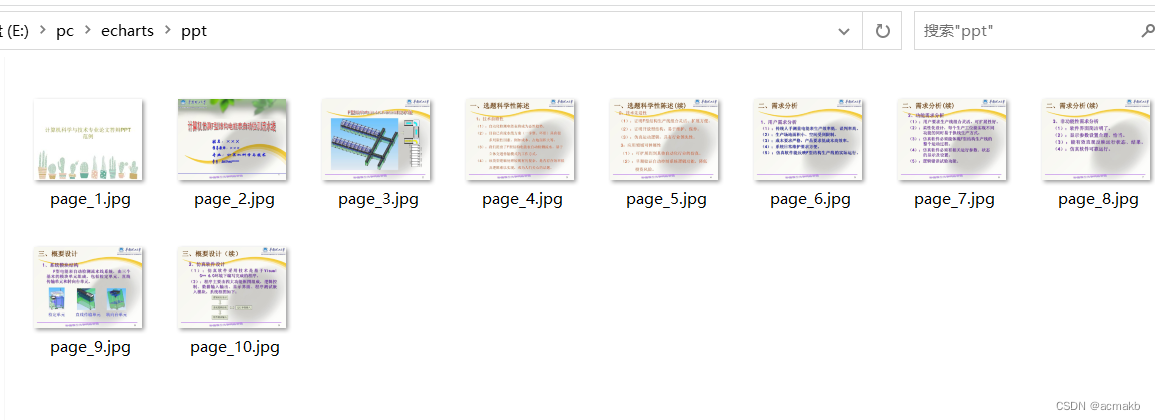
步骤2:
完整代码:
温馨提示:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




