遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
E.消融研究
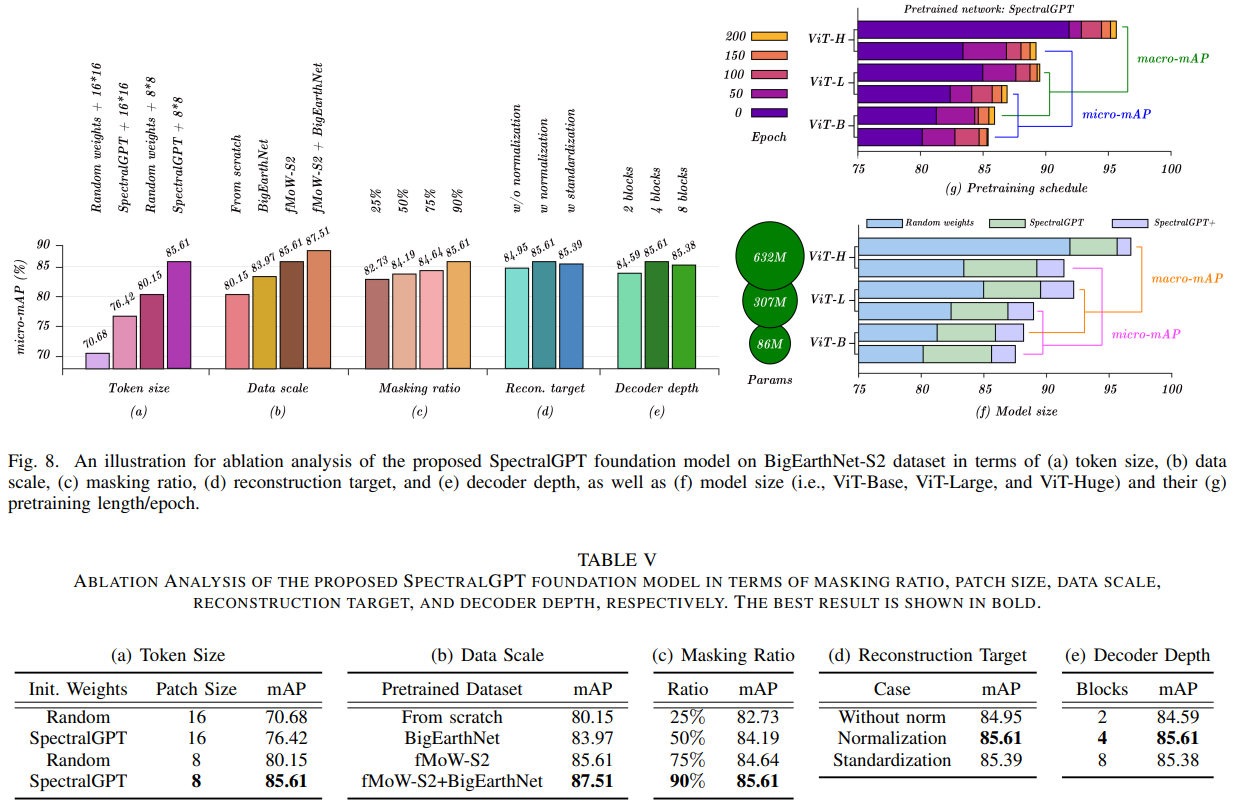
在预训练阶段,我们对可能影响下游任务表现的各种因素进行了全面研究。这些因素包括掩蔽比、ViT patch大小、数据规模、重建目标、解码器深度、模型尺寸。为了对预训练模型进行更严格的评估,我们在BigEarthNet多标签分类数据集上对所有消融模型进行微调,只使用训练集的10%子集,这是一个更艰巨的挑战,使用mAP测量进行评估。我们选择ViT-B作为主干模型,保证了实验间的一致性。除了涉及数据规模和训练计划长度的缩减外,所有模型都在fMoW-S2数据集上进行了200 epoch的预训练。这个全面的评估框架使我们能够更深入地了解这些因素对模型性能的影响。
1)token大小:表V(a)图8(a)提供了token大小对模型性能影响的重要见解,一致表明较大的patch大小会导致模型性能降低,这与先前的研究结果一致[30]。这种现象可以归因于ViT架构的内在特征。对于较大的令牌大小,例如16 x 16,每个图像包含较少的令牌,从而导致随着模型通过其更深层的进展,细粒度空间信息的减少。因此,空间细节的减少会对模型的整体性能产生负面影响。然而,值得注意的是,无论token大小设置如何,预训练模型始终增强mAP,强调其在各种配置中提高性能的能力。值得注意的是,尽管输入图像的大小为96 × 96或128 × 128,但标记大小为8 × 8时的识别性能明显优于16 × 16,强调了预训练模型的多功能性和有效性。
2)数据规模:表V(b)和图8(b)针对预训练数据在我们研究中的影响进行了综合分析。我们使用两个数据集(即fMoW-S2, BigEarthNet)进行预训练,同时保持标准输入图像大小为96 × 96。为了更深入地研究这种比较,我们最初专门在fMoW-S2上预训练模型,然后在BigEarthNet上无缝地继续预训练,没有任何中间的微调步骤。我们的预训练数据集包括fMoW-S2的广泛训练集,其中包括来自世界各地的令人印象深刻的712,874张图像,以及BigEarthNet的训练集,其中包括欧洲地区的351,496张图像,其中不包括受雪,云或云阴影影响的图像。
表V(b)中的分析强调了数据规模和分布对模型预训练的实质性影响。在与下游任务相同的数据集上预训练的模型始终表现出优异的性能,突出了数据集一致性在有效迁移学习中的关键作用。此外,fMoW-S2在预训练方面优于BigEarthNet,主要是由于其更大的数据集和更广泛的地理覆盖。有趣的是,持续预训练的概念,结合了两个数据集,导致模型具有更高的mAP分数。这种改进可以部分归因于fMoWS2预训练期间的96 × 96图像到BigEarthNet预训练期间的128 × 128图像的过渡,强调了增加图像大小对整体模型效率的有益影响。在与下游任务相同的数据集上预训练的模型始终表现出优异的性能,突出了数据集一致性在有效迁移学习中的关键作用。此外,fMoW-S2在预训练方面优于BigEarthNet,主要是由于其更大的数据集和更广泛的地理覆盖。有趣的是,持续预训练的概念,结合了两个数据集,导致模型具有更高的mAP分数。这种改进可以部分归因于fMoWS2预训练期间的96 × 96图像到BigEarthNet预训练期间的128 × 128图像的过渡,强调了增加图像大小对整体模型效率的有益影响。