本文介绍: CPU:可以处理通用计算,性能优化考虑数据读写效率和多线程GPU:使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务增加模型泛化性。
一、深度学习硬件-CPU和GPU
芯片:Intel or AMD
内存:DDR4
显卡:nVidia
芯片可以和GPU与内存通信
GPU不能和内存通信
1. CPU
能算出每一秒能运算的浮点运算数(大概0.15左右)
1.1 提升CPU利用率
1.1.1 提升缓存
1.1.2 提升并行
例子:

2. GPU
2.1 提升GPU利用率
3. CPU vs GPU

3.1 CPU/GPU带宽

3.2 更多的CPUs和GPUs
3.3 CPU/GPU高性能计算编程
总结:
补充:
二、TPU和其他
三、单机多卡并行
四、多GPU训练实现
五、分布式训练
六、数据增广
1. 一般专注于图片
总结:
2. 代码实现

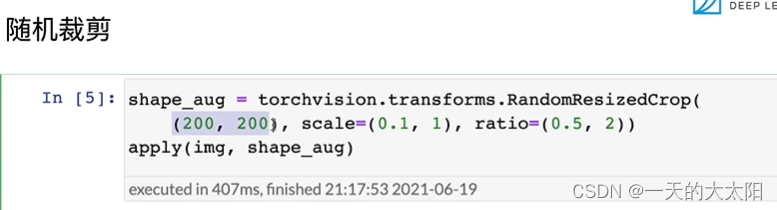

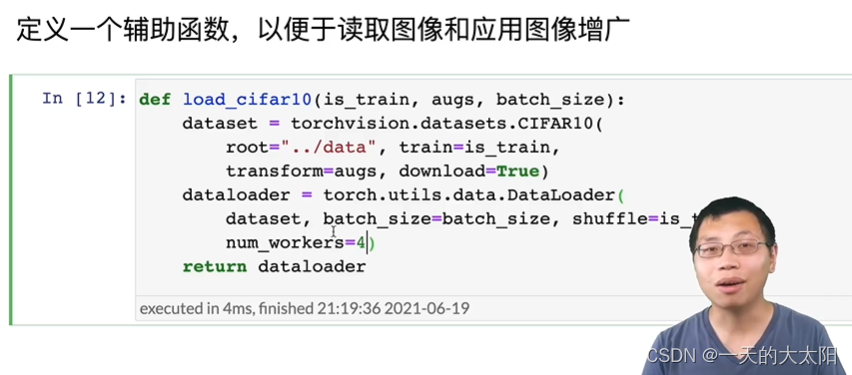
补充:
七、微调(迁移学习的一种)
1. 网络架构
2. 训练
3. 重用分类器权重
4. 固定一些层
5. 代码实现




补充:
八、竞赛-树叶分类结果
九、实战-图像分类kaggle比赛
八、竞赛-树叶分类结果
九、实战-图像分类kaggle比赛
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。