本文介绍: 将文本分类,主要工作是让机器分析文章内容,辨别其类别。
一、学习目标
1.学习文本分类的两种传统机器学习方法:朴素贝叶斯和支持向量机
2.学习文本分类的深度学习方法
3.学习文本分类的性能评估标准
4.学习文本聚类的相似性度量、具体算法、性能评估
二、文本分类
1.概述
将文本分类,主要工作是让机器分析文章内容,辨别其类别。常见的应用有:新闻文章归类,垃圾邮件识别:

2.传统机器方法
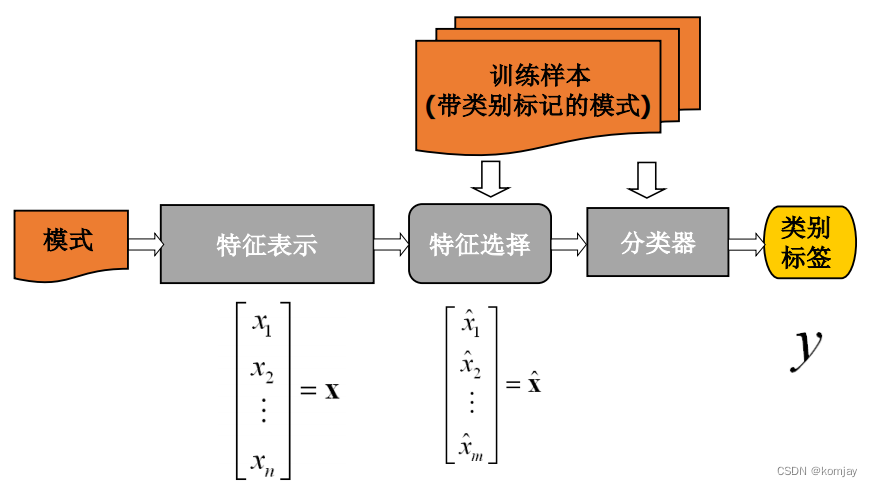
(1)文本表示


(2)特征选择








(3)分类算法

(a)朴素贝叶斯



(b)线性支持向量机


3.深度学习方法



4.文本分类性能评估







三、文本聚类
1.文本相似性度量

(1)文本之间

(2)集合之间




(3)文本与集合之间

2.文本聚类算法




3.文本聚类性能评估
(1)外部标准



(2)内部指标



四、本章小节
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。