简介
近年来NLP领域最让人印象深刻的成果,无疑是以谷歌提出的Bert为代表的预训练模型了。它们不断地刷新记录(无论是任务指标上,还是算力需求上),在很多任务上已经能超越人类平均水平,还具有非常良好的可迁移性,以及一定程度的可解释性。
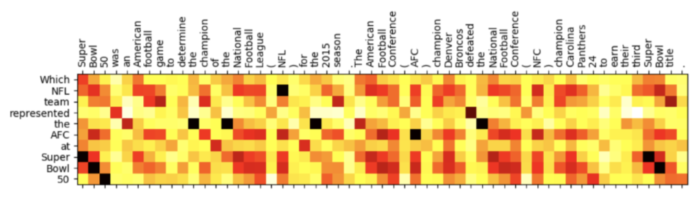
例如,当我们需要在论文里解释为什么算法或者改动能够work的时候,一张基于attention的热力图显然更容易说明我们的代码究竟做到了什么。
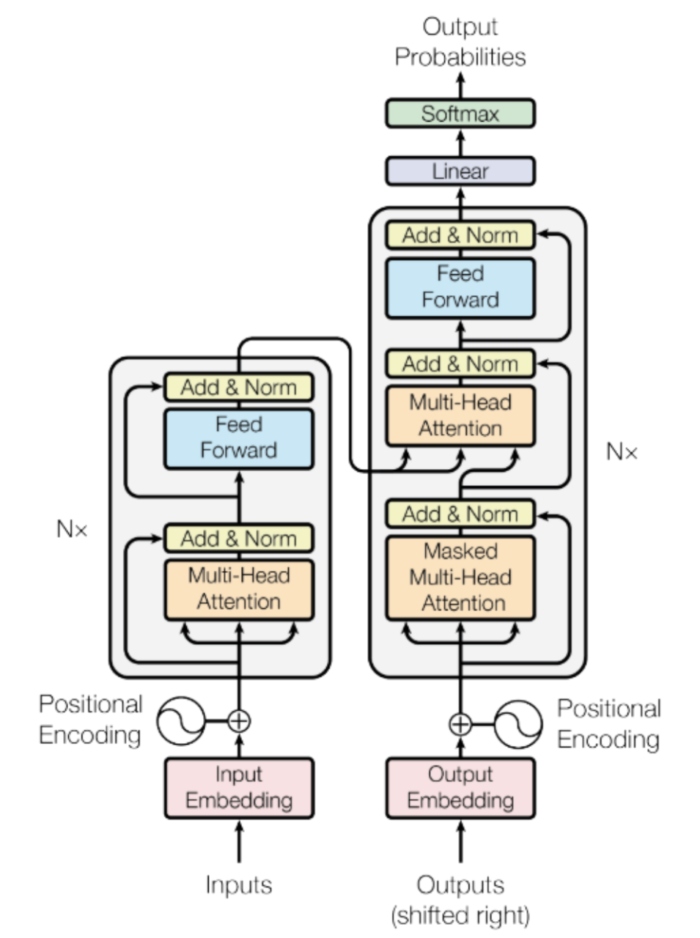
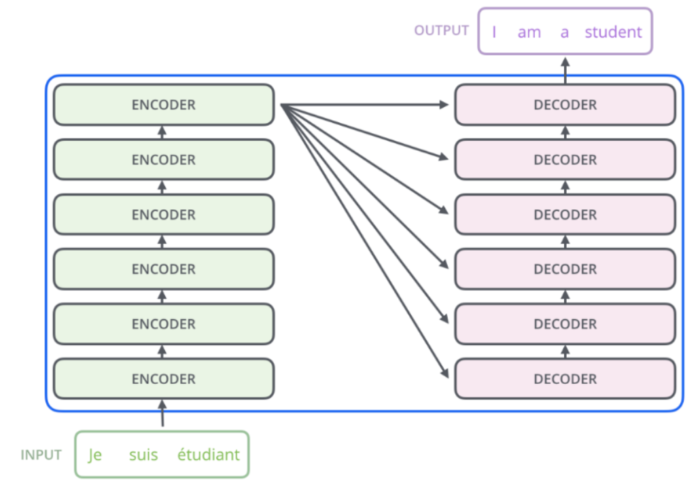
Transformer
Attention
Scaled Dot-Product Attention
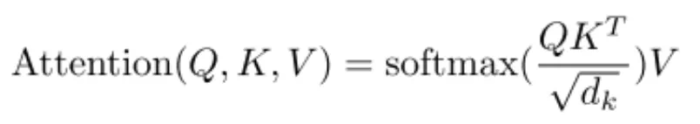 在Transformer中,这部分是通过Attention(Q, K, V)
在Transformer中,这部分是通过Attention(Q, K, V)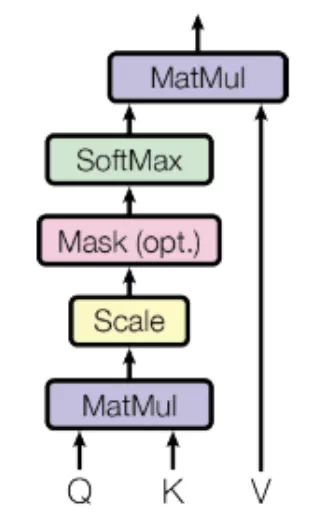
Multi-Head Attention
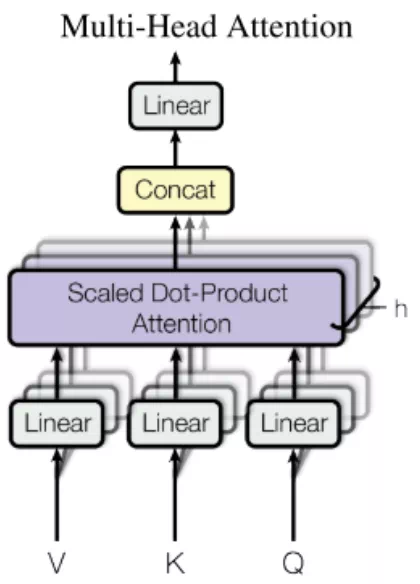 图5 Multi-He
图5 Multi-He
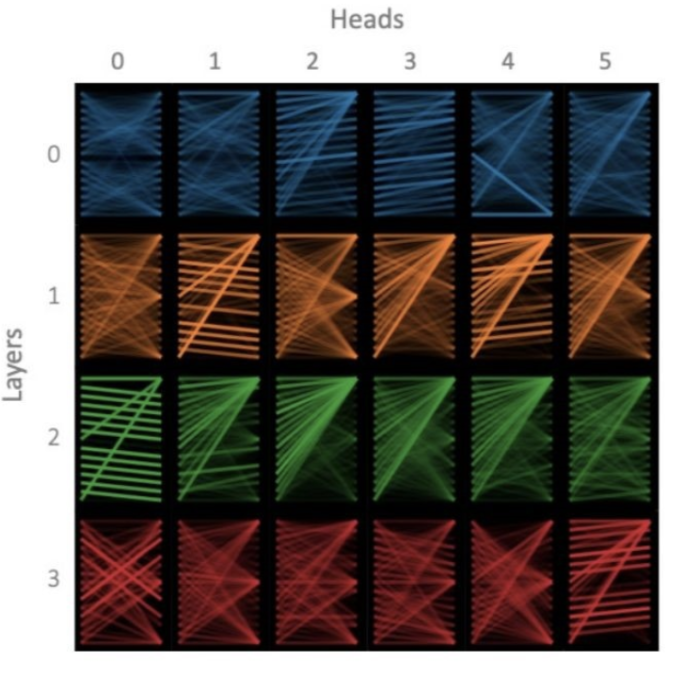
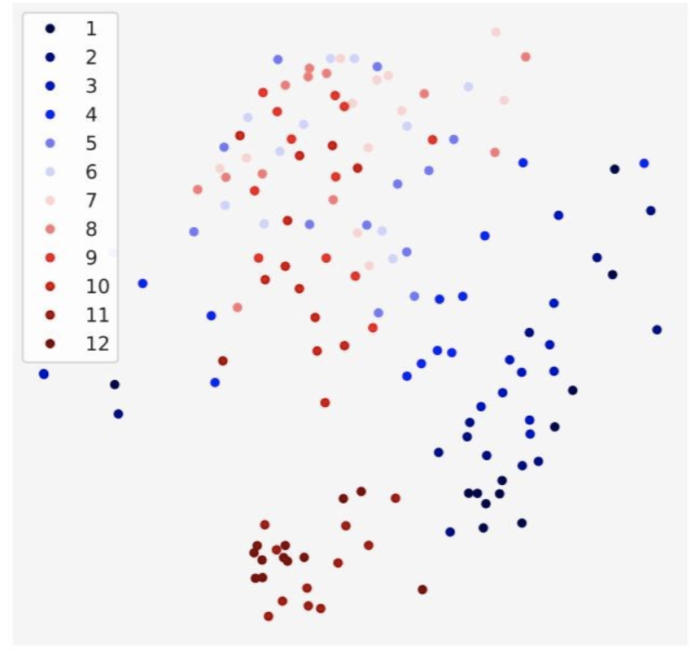
Positional Encoding
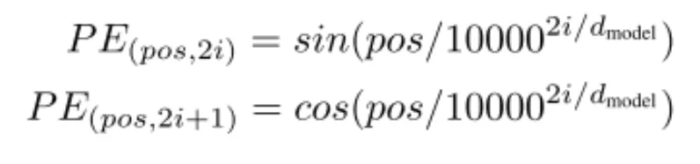
缺点
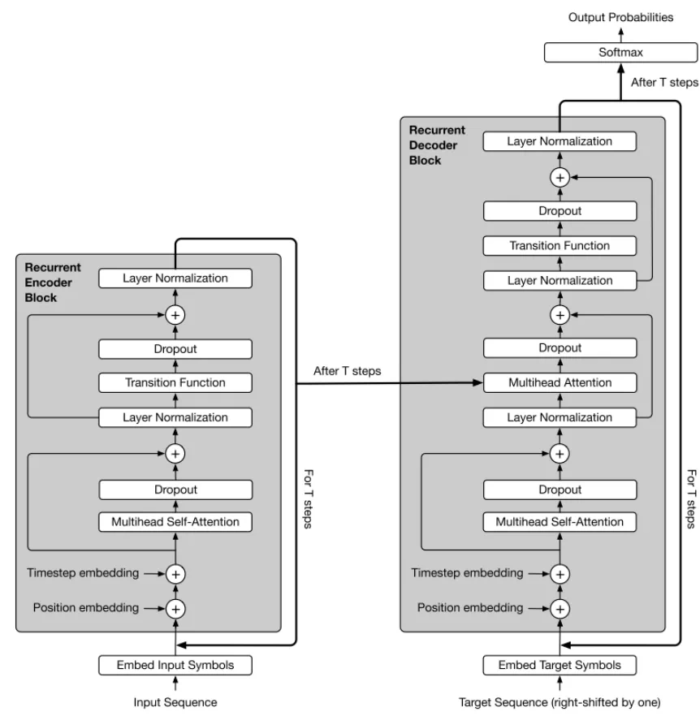
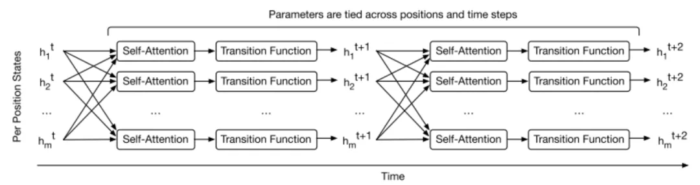
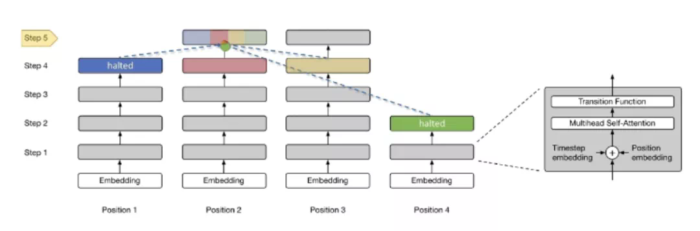
Universal Transformer
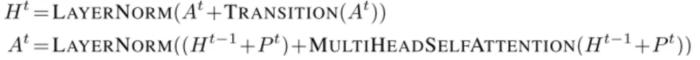
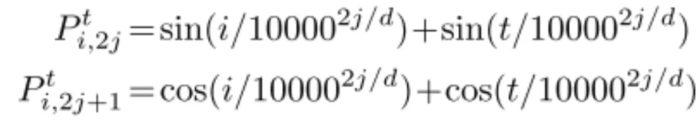
Transformer-XL

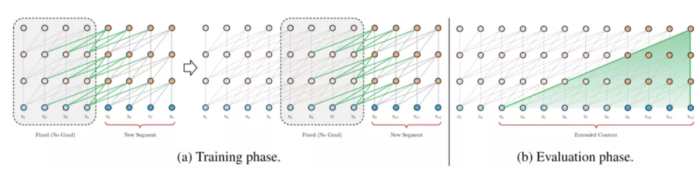 图11 Transformer-XL中,节点能够“看到”之前的segment中的内容
图11 Transformer-XL中,节点能够“看到”之前的segment中的内容 
从图中可以看出,在当前segment中,第n层的每个隐向量的计算,都是利用下一层中包括当前位置在内的,连续前L个长度的隐向量。这也就意味着,每一个位置的隐向量,除了自己的位置,都跟下一层中前(L-1)个位置的token存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1)。所以最长的依赖关系长度是N(L-1),N是模型中layer的数量。在对长文本进行计算的时候,可以缓存上一个segment的隐向量的结果,不必重复计算,大幅提高计算效率。
由于考虑了之前的segment,那么先前的位置编码就不足以区分不同segment之间的相同位置的token,因此作者提出了使用Relative Positional Encodeing来替代之前的位置编码。具体来说,就是使用相对位置编码来替代绝对位置编码。这种做法在思想上是很容易理解的,因为在处理序列时,一个token在其中的绝对位置并不重要,我们需要的仅仅是在计算attention时两个token的相对位置。由于这部分工作起到的作用主要是补丁,这里不再展开说。
总结来看。Transformer-XL在没有大幅度提高算力需求的情况下,一定程度上解决了长距离依赖问题。
Reformer

作者还考虑到有一定的概率相似的向量会被分到不同的桶里,因此采用了多轮hashing来降低这个概率。
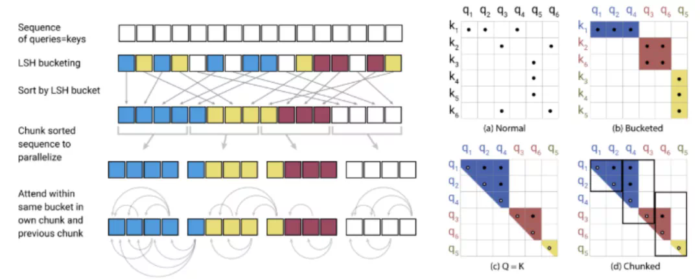 图12 Reformer模型预先使用了hashing筛选,类似桶排序,避免了对QK的计算
图12 Reformer模型预先使用了hashing筛选,类似桶排序,避免了对QK的计算
LSH解决了计算速度的问题,但仍有一个内存消耗的问题。一个单层网络通常需要占用GB级别的内存,但是当我们训练一个多层模型时,需要保存每一层的激活值和隐变量,以便在反向传播时使用。这极大地提高了内存的占用量。
这里作者借鉴了RevNet的思想,不保留中间残差连接部分的输入了,取而代之的,是应用一种“可逆层”的思路,就如同下图中所示的那样,(a)为前向传播,(b)为反向传播。
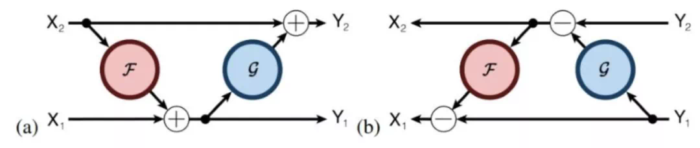 图13 Reformer中的反向传播时,每一层的输入可以根据其输出计算出来 可逆层对每个层有两组激活。一个遵循正常的标准过程,并从一个层逐步更新到下一个层,但是另一个只捕获对第一个层的更改。因此,要反向运行网络,只需减去应用于每个层的激活。
图13 Reformer中的反向传播时,每一层的输入可以根据其输出计算出来 可逆层对每个层有两组激活。一个遵循正常的标准过程,并从一个层逐步更新到下一个层,但是另一个只捕获对第一个层的更改。因此,要反向运行网络,只需减去应用于每个层的激活。
这意味着不需要缓存任何激活来计算后向传播。类似于使用梯度检查点,虽然仍然需要做一些冗余计算,但由于每一层的输入都可以很容易地从它的输出中构造出来,内存使用不再随网络中层数的增加而增加。
总结来看,Reformer在减少了attention计算量的情况下,还减少了模型的内存占用,为未来大型预训练模型的落地奠定了基础。
总结
本文主要介绍了Transformer模型以及针对其缺点作出改进的一些变种模型,总结了它们的设计思路和优缺点。未来,以Transformer及其改进版为基础特征抽取器的预训练模型,一定能够在自然语言处理领域取得更大的突破。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Dehghani M, Gouws S, Vinyals O, et al. Universal transformers[J]. arXiv preprint arXiv:1807.03819, 2018.
[3] Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed–length context[J]. arXiv preprint arXiv:1901.02860, 2019.
[4] Kitaev N, Kaiser Ł, Levskaya A. Reformer: The Efficient Transformer[J]. arXiv preprint arXiv:2001.04451, 2020.
[5] Vig J. A multiscale visualization of attention in the transformer model[J]. arXiv preprint arXiv:1906.05714, 2019.
[6] Clark K, Khandelwal U, Levy O, et al. What does bert look at? an analysis of bert’s attention[J]. arXiv preprint arXiv:1906.04341, 2019.






