资料
- 课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
- Github:https://github.com/Fafa-DL/Lhy_Machine_Learning
- B站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800
一、图像生成常见模型
前提:一张好的图像的资讯量是远超一句文句所能提供的。
差异:在图像中许多文字中没有提供的信息是需要机器进行大量的脑补才能产生的,这也是图片生成(或语音生成)与文字生成的不同之处,而这种不同体现在模型的设计上。
对比:

-
文字生成:多采用Autoregressive(各个击破)的方法,也就是去计算下一个输出文字的概率
-
图像生成:类比文字生成,多采用Autoregressive(各个击破)的方法,计算下一个像素出现的概率;图像逐行生成,可行,但是生成速度慢,所以在图像生成中一般采用一次到位的生成方法
① 一次到位产生的问题:输入一段文字,正确答案并不是只有一个,单独做每个像素的分布,各有各的想法,会导致生成的图像像拼凑的破布;

②对应解法:增加一个额外的输入normal/uniform distribution,产生P(x|y)

二、常见图像生成模型

1. VAE

说明:
- 1)文字输入decoder,用于限制图像生成的范围;
- 2)Encoder输出一个向量交给Decoder,希望还原回一样的图像;
- 3)Encoder和Decoder一起训练,希望生成的图像越相似越好;
- 4)Encoder生成的向量强制满足Normal Distribution;
2. Flow-based Generative Model
 说明:
说明:
1)训练Encoder,输入一张图片输出一个向量,并保证这个向量是Invertible可逆的(大小与输入图像一致);
2)多个向量组成Normal Distribution,输入Encoder得出生成图像;
3. Diffusion Model

说明:
1)对一张图片不断添加噪声,让它看起来就像一个Normal Distribution取样得出的向量;
2)训练一个Denoise(解噪声)模型,一步步去除噪音,得到原图;
4. GAN

说明:
1)训练decoder,输出大量从Normal Distribution中sample出的向量(此时的输出质量差,几乎看不出是什么,只是一堆噪音),
2)训练Discriminator(鉴别器),作用是判断一张图片是decoder生成的图片P’(x)(左)还是真正的图片P(x)(右),
3)调整decoder的参数,计算P’(x)和P(x)的相似程度Loss,使discriminator越接近越好;
三、浅谈Diffusion Model
相关论文:Denoising Diffusion Probabilistic Models (DDPM)
论文地址:https://arxiv.org/abs/2006.11239

1. Diffusion Model原理
(1)Diffusion model
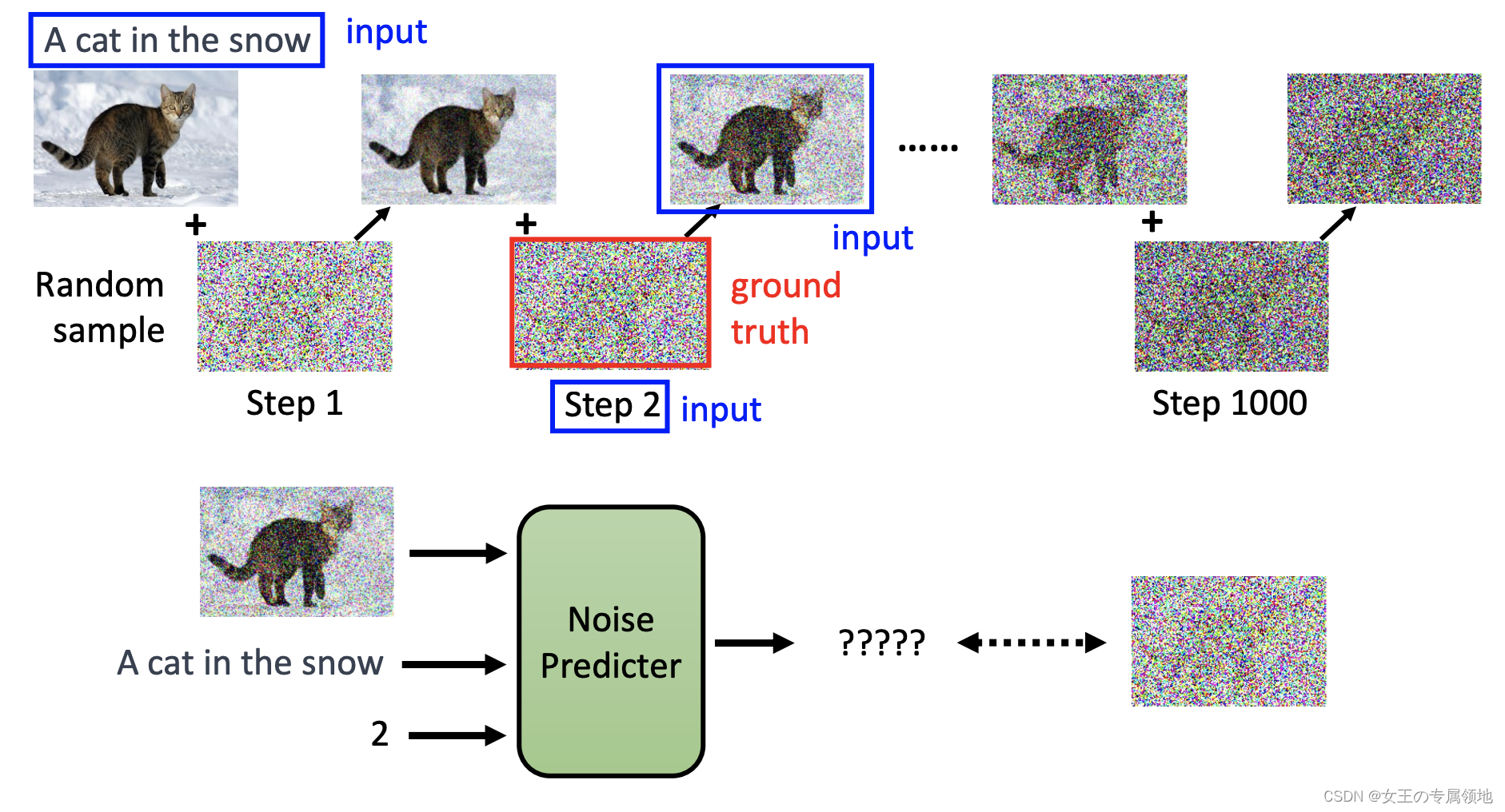
(2)Denoise模块
- 将带有噪音的图像和噪音严重程度输入Noise Predicter
- Noise Predicter预测输入图片的噪音并输出噪音图像
- 最后将输入的图片减去预测的噪音图像作为输出结果

(3)Noise Predicter模块
- 训练数据:通过Forward/Diffusion Process不断对原图像加噪音生成噪音图像;
- 输入:输入图像input、噪声严重程度step
- 输出:Ground truth

2. Text-to-Image 文生图

说明:
-
模型:在原有Diffusion的基础上增加文本输入;

-
数据来源:在原有Noise Predicter训练基础上增加文本输入;
四、Stable Diffusion、DALL-E、Imagen 背后共同的套路
1. 观察Stable Diffusion、DALL-E、Imagen

论文地址:https://arxiv.org/abs/2112.10752
模型:最右边是输入(不只可以输入文字),中间是一个生成模型(使用diffusion modal),将diffusion modal生成的中间产物(一个图片压缩后的版本)输入最左边,还原回原来的图像;

模型:DALL-E series内置两个生成模型autoregressive(图像不大时使用)与diffusion modal

模型:先通过diffusion modal生成64×64的小图,再通过decoder生成256×256的大图;
2. 总结套路

- Text Encoder将文字叙述转化为多个向量;
- Generation Model,输入噪音和text Encoder生成的向量,生成一个中间产物(中间产物有不同的形式)
- 把中间产物(图中的中间产物是图片的压缩版本)输入Decoder,将图片还原为原始图像
模块 1:Text Encoder
过程:文字转为向量
模块2:Generation Model
过程:输入文字的向量和噪音图像,输出中间产物,与前面的描述diffusion model不同的是,noise不是直接加在图片上,而是加在representation上。

训练完成后,将Latent Representation与一段文字输入Denoise,重复多次,得到合适的中间产物传给Decoder;

模块3:Decoder
过程:Decoder的训练不需要文字资料,只需要大量的图片资料。
-
第一种:中间产物是小图,将原图(图像对的右边)做down-sampling变为小图(左),即可得到训练资料;

-
第二种:中间产物是Latent Representation(潜在图像特征),获取方式(使用Auto-encoder:往encoder输入一张图像,生成Latent Representation,再把Latent Representation输入decoder,以还原原来的图片,让输入与输出越接近越好。训练完成后,取出decoder即为所求。

五、拓展学习
Variational Auto-encoder (VAE)
Flow-based Generative Model
Generative Adversarial Network (GAN)
原文地址:https://blog.csdn.net/Julialove102123/article/details/135381732
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_51774.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!



![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)
