本文介绍: 【代码】2023.12.28 Python高级-正则表达式。
目录
re正则表达式,一种专门用来匹配目标字符串的规则
| 正则语法 | 描述 |
|---|---|
| . | 匹配任意1个字符,除了 n |
| d | 匹配1位数字,即0-9 |
| D | 匹配1位非数字 |
| s | 匹配1位空白符:空格、Tab |
| S | 匹配1位非空白符 |
| w | 匹配1位非特殊字符:即a-z、A-Z、0-9、_、汉字 |
| W | 匹配1位特殊字符 |
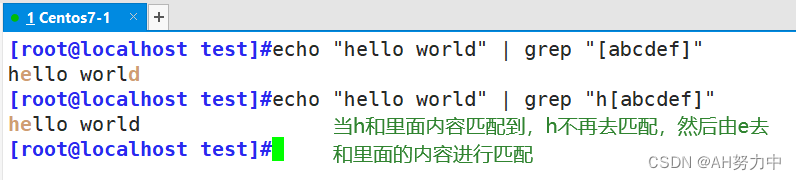
| [列举字符] | 匹配1个[ ]中列举的字符:[a-z]表示匹配1个小写英文字符 |
| * | 匹配出现0次或任意次的一个字符:d* 表示 0个或任意个连续的数字 |
| + | 匹配出现1次或任意次的一个字符:d+ 表示 1个或任意个连续的数字 |
| ? | 匹配出现1次或0次的一个字符:d+? 表示 1个数字 |
| {m} | 匹配出现m次的字符:d{3} 表示 连续3个数字 |
| {m,n} | 匹配出现从m到n次的字符:d{2,5} 表示连续2到5个数字 |
| ^ | 匹配字符串开头:^a 表示以a开头的 |
| $ | 匹配字符串结尾 :b$ 表示以b结尾 |
| [^指定字符] | 匹配除了指定字符以外的所有字符 [^d]+表示除了数字以外的字符 |
| | | 匹配左右任意一个正则表达式 d+|W+ 表示数字或特殊字符 |
re.match(),从头匹配一个,无则none
"""
match函数:尝试从字符串起始位置根据正则表达式匹配一个结果
re.match(pattern正则表达式, string目标字符串)
1.如果不能从起始位置匹配成功,则返回None;
2.如果能从起始位置匹配成功,则返回一个匹配的对象
"""
import re
my_str = 'abc_123_DFG_456_abc'
# 匹配字符串bc(注:从头开始)
res = re.match('bc', my_str)
print(res) # None
# 匹配字符串abc(注:从头开始)
res = re.match('abc', my_str)
print(res) # 匹配成功,返回一个 Match 对象
# Match对象.group():获取匹配的内容
print(res.group())
print('-----------')re.search(), 不从头匹配返回一个,无则none
"""search函数:根据正则表达式扫描整个字符串,并返回第一个成功的匹配
re.search(pattern, string, flags=0)
1. 如果不能匹配成功,则返回None;
2. 如果能匹配成功,则返回一个匹配对象
"""
import re
my_str = 'abc_123_DFG_456_abc'
# 匹配连续的3位数字 # d{3}
res = re.search(r'd{3}', my_str)
print(res.group())
res = re.search(r'bc', my_str)
print(res.group())re.findall(), 不从头匹配,用list返回所有
"""findall函数:根据正则表达式扫描整个字符串,并返回所有能成功匹配的子串
re.findall(pattern, string, flags=0)
1. 如果不能匹配成功,则返回一个空列表;
2. 如果能匹配成功,则返回包含所有匹配子串的列表
"""
import re
my_str = 'abc_123_DFG_456_abc'
# 匹配字符串中的所有连续的3位数字
res = re.findall(r'd{3}', my_str)
print(res)re分组
import re
"""
示例1:正则匹配分组操作
语法:(正则表达式)
"""
# 匹配手机号前3、中4、后4位数据
my_str = '13155667788'
# 131 5566 7788
# d{3}d{4}d{4}
# (d{3})(d{4})(d{4})
res = re.match(r'(d{3})(d{4})(d{4})', my_str)
print(res)
print(res.group()) # 完整的匹配结果
# Match对象.group(组序号)
print(res.group(1)) # '131'
print(res.group(2)) # '5566'
print(res.group(3)) # '7788'
print('--------------')
"""
示例2:给正则分组起别名
语法:(?P<分组别名>正则表达式)
"""
# 需求:使用正则提取出 my_str 字符串中的 `传智播客` 文本
my_str = '<div><a href="https://www.itcast.cn" target="_blank">传智播客</a><p>Python</p></div>'
res = re.search('<a.*>(?P<text>.*)</a>', my_str)
print(res)
print(res.group()) # 完整匹配结果
print(res.group(1)) # 根据组序号取匹配的数据
print(res.group('text')) # 根据组别名取匹配的数据
"""
示例3:引用正则分组
语法:(?P<分组别名>正则表达式).*(?P=分组别名)
"""
import re
# 需求: 找到字符串里反复出现3次的连续的数字
my_str = 'a123jkfjkfjg123' # ==> None
my_str = '123aq123a123' # ==> 123
my_str = '123123123' # ==> 123
my_str = '123 123123' # ==> 123
res = re.match(r'(?P<num>d+)D*(?P=num)D*(?P=num)$', my_str)
if res:
print('匹配成功')
print(res.group(1))
print(res.group('num'))
else:
print('匹配失败')re匹配修饰符
import re
"""
re.I:匹配时不区分大小写
re.M:多行匹配,影响 ^ 和 $
re.S:影响 . 符号,设置之后,.符号就能匹配n了
"""
# re.I:匹配时不区分字母的大小写
my_str = 'aB'
res = re.match('ab', my_str, flags=re.I)
print(res.group())
print('----------------')
# re.M:开启多行匹配模式,把每一行字符串,当作一个独立的字符串进行匹配
my_str = 'aabbnbbcc'
res = re.findall('^[a-z]{4}$', my_str, flags=re.M)
print(res)
res = re.findall('^[a-z]{4}$', my_str)
print(res)
res = re.findall('[a-z]{4}', '11aabb')
print(res)
res = re.findall('^[a-z]{4}$', '11aabb')
# 被匹配的字符串必须以字母开头以字母结尾
print(res)
print('----------------')
# re.S:让 . 也能匹配n
my_str = 'nabc'
res = re.match('.', my_str, flags=re.S)
print(res)
# 多模式:flags=re.S|re.M|re.I
my_str = '1111nabc'
res = re.findall('.', my_str, flags=re.S|re.M|re.I)
print(res)re贪婪非贪婪
import re
"""
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
正则中的量词包括:{m,n}、?、*和+,这些量词默认都是贪婪模式的匹配
可以在这些量词后面加?将其变为非贪婪模式。
"""
my_str = '<div>test1</div><div>test2</div>'
# 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
re_obj = re.match('<div>.*</div>', my_str)
print(re_obj.group()) # 获取整个正则表达式匹配的内容
print('----')
# 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
re_obj = re.match('<div>.*?</div>', my_str)
print(re_obj.group()) # 获取整个正则表达式匹配的内容
# d{2,5}? == d{2} != d{2,5}
my_str = '221324324324242'
re_obj = re.match('d{2,5}?', my_str)
print(re_obj.group())
re_obj = re.match('d{2,5}', my_str)
print(re_obj.group())
re_obj = re.match('d{2}', my_str)
print(re_obj.group())re切割和替换
import re
# re.split(pattern, string, maxsplit, flags)
# 作用:对字符串进行分割
# 过程:先使用正则对字符串进行匹配,正则匹配到的内容作为分割符,对字符串进行分割
str1 = 'hello-python_hive'
res1 = re.split('[-_]', str1)
print(res1) # ['hello', 'python', 'hive']
# re.sub(pattern, repl, string, count, flags)
# 作用:对字符串中的内容进行替换
# 过程:先使用正则对字符串进行匹配,然后将匹配到的内容进行替换,返回替换之后的新字符串
str2 = 'hello-python_hive' # 'hello:python:hive'
res2 = re.sub('[-_]', ':', str2)
print(res2) # hello:python:hive原文地址:https://blog.csdn.net/m0_49956154/article/details/135271407
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_51808.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。