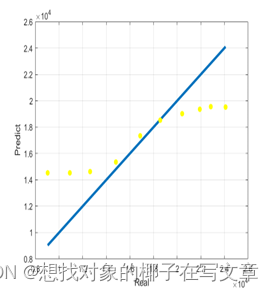
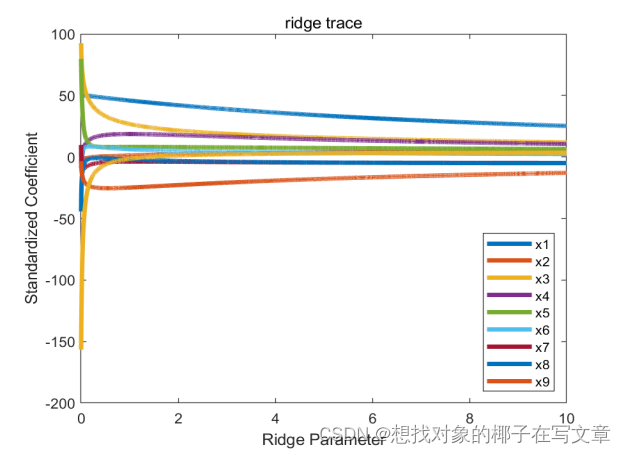
本文介绍: 新能源汽车的发展对传统能源汽车的影响体现在许多方面,首先如果世界兴起去买新能源汽车,传统能源的发展速度就一定会受到一定阻碍,其次,目前来看,电能的成本远小于汽油,如果电能和汽油的差值持续相差许多,竞争结局的结果一定是朝向新能源汽车市场的,此外,随着一些国家的技术创新,新能源汽车的成本有可能进一步下降,这会传统能源市场带来巨大竞争力。图17是通过K-means聚类方法得到的不同的K值残差平方和图,由图可得,当SSE的值最小时对应的K值就是我们岭回归参数中中K的取值,用方差扩大因。
六、问题三的模型建立和求解
6.1问题分析
问题3.收集数据,建立数学模型分析新能源电动汽车对全球传统能源汽车行业的影响。
本题要求建立模型分析新能源电动汽车对全球传统能源汽车行业的影响。由于数据集可能略大,而在处理复杂问题、大量特征和大规模数据集时神经网络,支持向量机算法,随机森林算法等均表现出色,考虑到当数据集中有多个特征,且特征之间的关系复杂时,随机森林处理效果更佳,故我们收集一定新能源汽车的相关信息作为自变量构建随机森林模型。
6.2特征选取
新能源汽车的发展对传统能源汽车的影响体现在许多方面,首先如果世界兴起去买新能源汽车,传统能源的发展速度就一定会受到一定阻碍,其次,目前来看,电能的成本远小于汽油,如果电能和汽油的差值持续相差许多,竞争结局的结果一定是朝向新能源汽车市场的,此外,随着一些国家的技术创新,新能源汽车的成本有可能进一步下降,这会传统能源市场带来巨大竞争力。
于是,我们根据第一问的结果选取新能源汽车的特征数据探究他们对传统能源汽车市场的影响,我们以新能源汽车所占的市场份额,平均售价,保有量等作为中国新能源汽车的特征数据,以传统能源汽车市场占有量,作为因变量,探究自变量对因变量的影响。
6.3随机森林的建立
随机森林的算法步骤如下:
STEP1:从原始样本中抽取训练集,每轮从原始样本中用Bootstraping的放法抽取n个训练样本(Bootstraping就是有放回的抽取样本)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)


七.第四题模型建立和求解
7.1第四小题问题分析
7.2数据分析
7.3岭回归模型

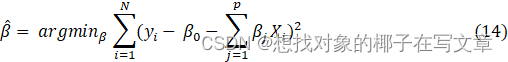
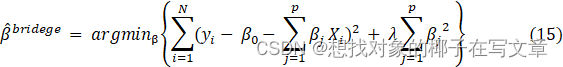
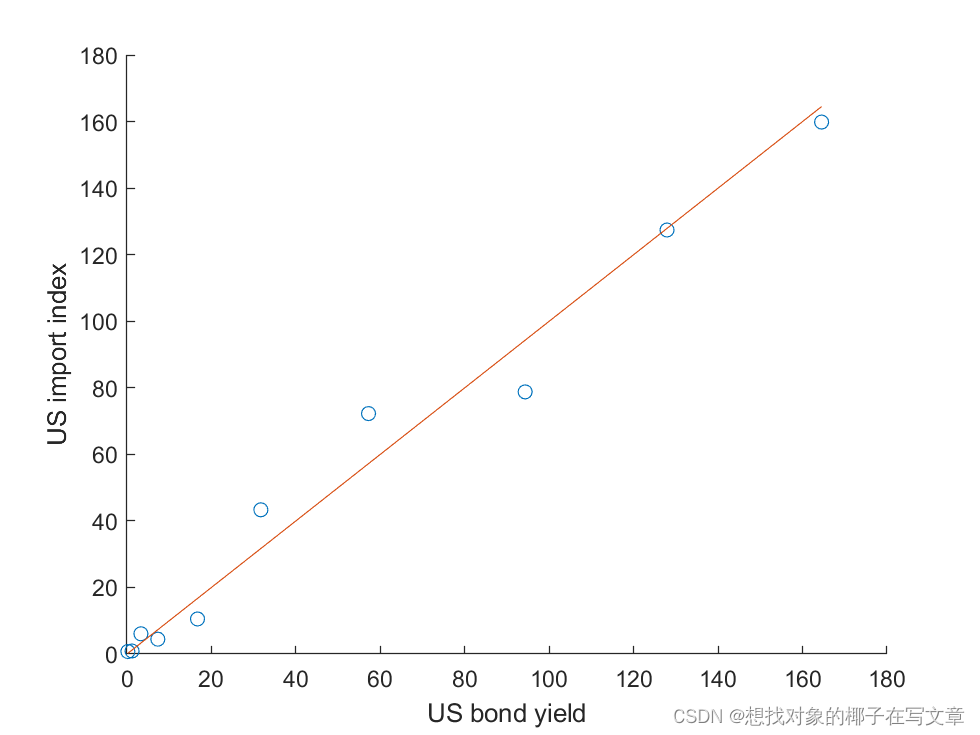
7.4 模型求解结果
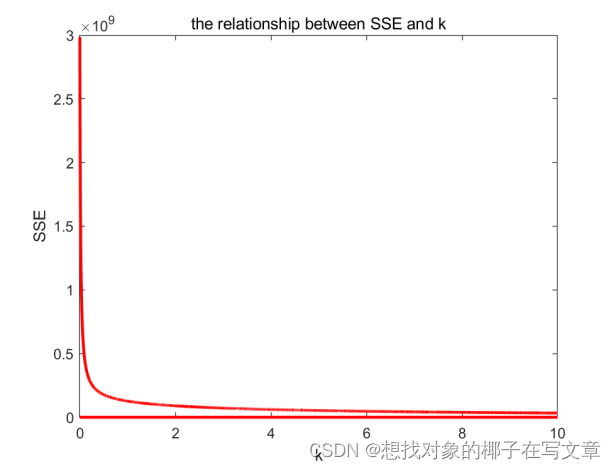
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。