本文介绍: (1)使用 yum 安装需要虚拟机可以正常上网,yum 安装前可以先测试下虚拟机联网情况(2)安装epel-release(3)注意:如果Linux 安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作net-tool:工具包集合,包含ifconfig 等命令vim:编辑器。
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 概述-CSDN博客
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建-CSDN博客
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行模式-CSDN博客
1、模板虚拟机环境准备
1.1、 hadoop100 虚拟机配置要求如下
(1)使用 yum 安装需要虚拟机可以正常上网,yum 安装前可以先测试下虚拟机联网情况
(2)安装epel-release
(3)注意:如果Linux 安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作
net-tool:工具包集合,包含ifconfig 等命令
vim:编辑器
1.2、 关闭防火墙,关闭防火墙开机自启
1.3、 创建普通用户,并修改普通用户的密码
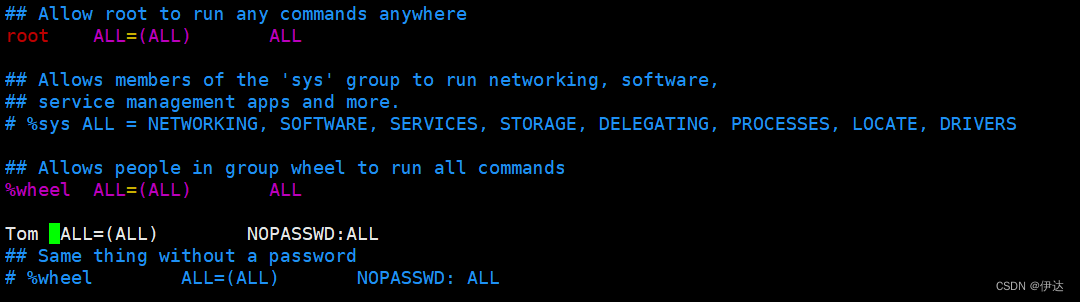
1.4、 配置普通用户具有 root 权限,方便后期加sudo 执行 root 权限的命令
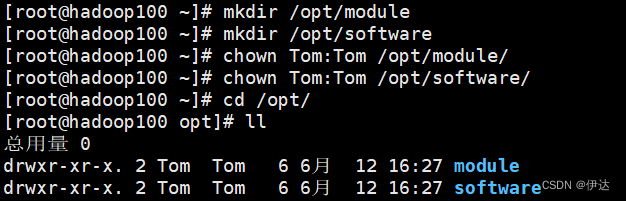
2.1.5 在 /opt目录下创建文件夹 ,并修改所属用户和所属组
2.1.6 卸载虚拟机自带的 JDK
1.7| 重启虚拟机
2.2 克隆虚拟机
2.1、 利用模板机 hadoop100,克隆 三台虚拟机 hadoop102 hadoop103 hadoop104
2.2、 修改克隆机 IP,以 hadoop102 举例说明
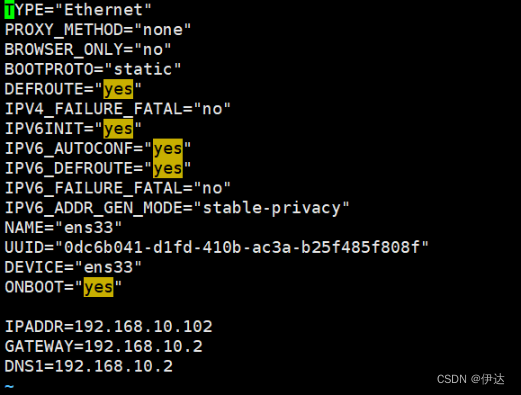
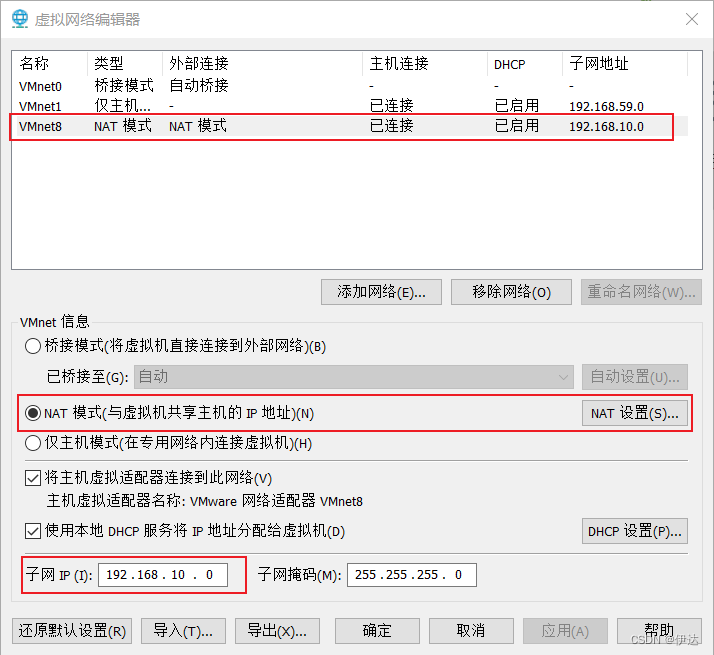
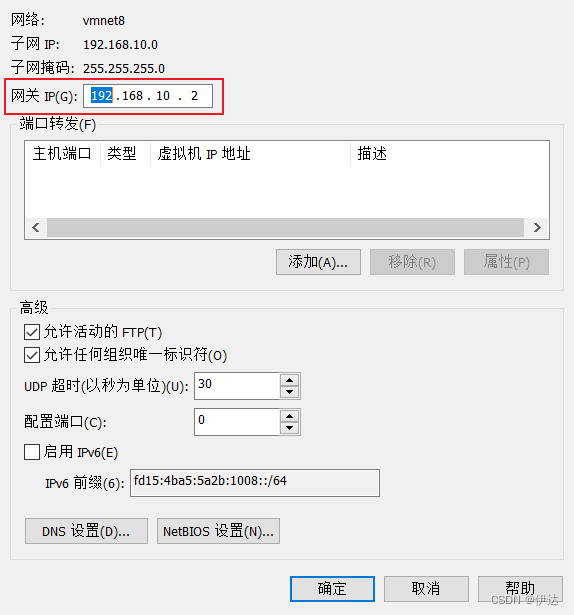
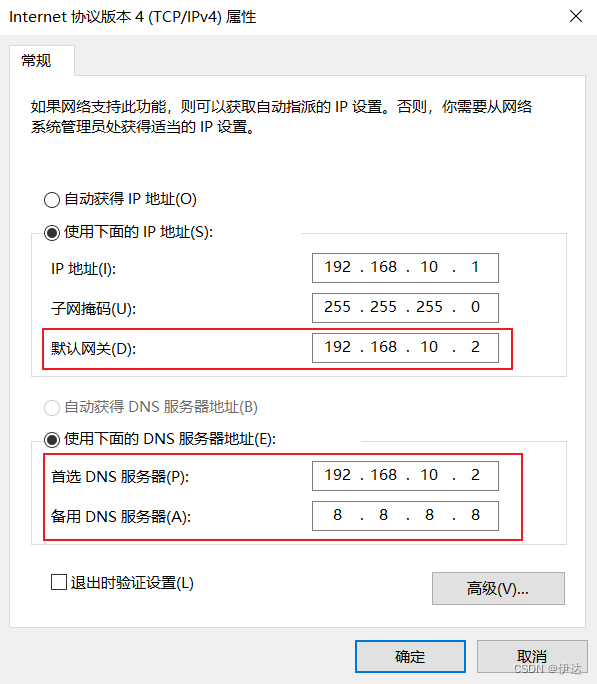
2.3、 修改克隆机主机名 ,以 hadoop102举例说明
2.4、 重启克隆机 hadoop102
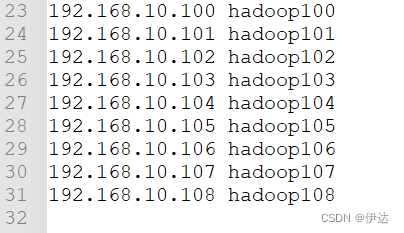
2.5、 修改 windows的主机映射文件(hosts文件)
3、 在 hadoop102 安装 JDK
3.1、卸载现有 JDK
3.2、用 XShell传输工具将 JDK导入到 opt目录下面的 software文件夹下面
3.3、在 Linux系统下的 opt目录中查看软件包是否导入成功
3.4、解压 JDK到 /opt/module目录下
3.5、配置 JDK环境变量

4、 在 hadoop102 安装 Hadoop
4.1、用 XShell文件传输 工具将 hadoop-3.1.3.tar.gz导入到 opt目录下面的 software文件夹下面
4.2、解压安装文件到 /opt/module下面
4.3、查看是否解压成功
4.4、将 Hadoop添加到环境变量

4.5、测试是否安装成功
4.6、重启 如果 Hadoop命令不能用再重启虚拟机
5、 Hadoop 目录结构
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。