这个是笔者大学时期的大数据课程使用三台CentOS7.6虚拟机搭建完全分布式集群的案例,已成功搭建完全分布式集群,并测试跑实例。
9 安装hbase
温馨提示:安装hbase先在master主节点上配置,然后远程复制到slave01或slave02 ,在配置环境即可。
9.1 解压并配置环境变量
9.1.1 解压安装包
1)使用WinSCP将hbase-2.2.2-bin.tar.gz的压缩包从windows系统传至master主节点机器上,并放置在/opt/software目录中,同时创建 /usr/hbase目录,后续将hbase-2.2.2-bin.tar.gz的压缩包解压到/usr/hbase即可。

2)在usr下创建hbase文件夹
mkdir -p /usr/hbase

3)将放置在/opt/software目录中hbase-2.2.2-bin.tar.gz解压到/usr/hbase目录下
tar –zxvf /opt/software/hbase-2.2.2-bin.tar.gz -C /usr/hbase

9.1.2 修改配置文件hbase-env.sh
1)先进入hbase配置目录conf
cd /usr/hbase/hbase-2.2.2/conf
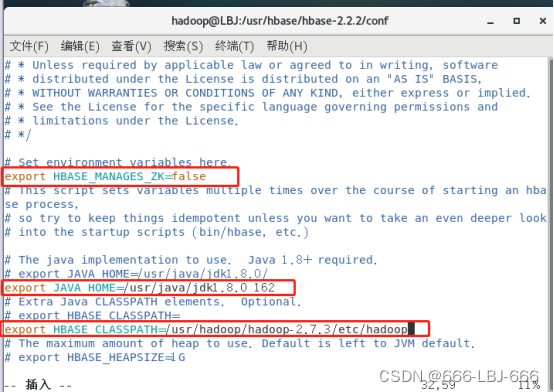
2)修改配置文件hbase-env.sh
vim hbase-env.sh

3)并修改文件内容:
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.8.0_162
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/hadoop
注:
一个分布式运行的Hbase依赖一个zookeeper集群。所有的节点和客户端都必须能够访问zookeeper。默认的情况下Hbase会管理一个zookeep集群,即Hbase默认自带一个zookeep集群。这个集群会随着Hbase的启动而启动。而在实际的商业项目中通常自己管理一个zookeeper集群更便于优化配置提高集群工作效率,但需要配置Hbase。需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 来切换。这个值默认是true的,作用是让Hbase启动的时候同时也启动zookeeper.在本实验中,我们采用独立运行zookeeper集群的方式,故将其属性值改为false。
9.1.3 修改配置文件vim hbase-site.xml

<property>
<name>hbase.rootdir</name>
<value>hdfs://LBJ:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://LBJ:6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>LBJ,slave01,slave02</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper/zookeeper-3.4.10</value>
</property>

注:
要想运行完全分布式模式,加一个属性 hbase.cluster.distributed 设置为 true 然后把 hbase.rootdir 设置为HDFS的NameNode的位置;
hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase。URL需要是’完全正确’的,还要包含文件系统的scheme;hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。在hbase-site.xml配置zookeeper,当Hbase管理zookeeper的时候,你可以通过修改zoo.cfg来配置zookeeper,对于zookeepr的配置,你至少要在 hbase-site.xml中列出zookeepr的ensemble servers,具体的字段是 hbase.zookeeper.quorum.在这里列出Zookeeper集群的地址列表,用逗号分割。
hbase.zookeeper.property.clientPort:ZooKeeper的zoo.conf中的配置,客户端连接的端口。hbase.zookeeper.property.dataDir:ZooKeeper的zoo.conf中的配置。对于独立的Zookeeper,要指明Zookeeper的host和端口。需要在 hbase-site.xml中设置。
9.1.4 修改配置文件conf/regionservers
vim regionservers

将里面修改为:两个从节点名称
slave01
Slave02

9.1.5 hadoop配置文件拷入hbase的目录下
hadoop配置文件拷入hbase的目录下(当前目录为/usr/hbase/hbase-2.2.2/conf)
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /usr/hbase/hbase-2.2.2/conf
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml /usr/hbase/hbase-2.2.2/conf

9.2 分发hbase到子节点并配置环境
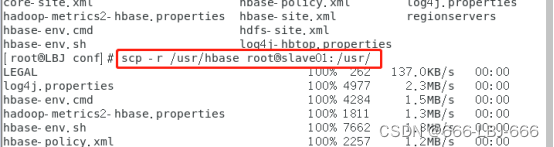
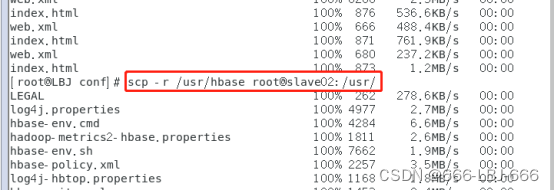
9.2.1 分发hbase到子节点
scp -r /usr/hbase root@slave01:/usr/
scp -r /usr/hbase root@slave02:/usr/
9.2.2 子节点配置hbase环境(三台机器都需配置)
vim /etc/profile
需要配置Hbase环境变量 :
#hbase
export HBASE_HOME=/usr/hbase/hbase-2.2.2
export PATH=$PATH:$HBASE_HOME/bin
是配置生效:source /etc/profile
在master上:

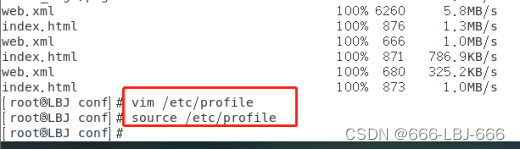
在slave01上:

在slave02上:

9.3 运行和测试(在master上执行并保证hadoop和zookeeper已开启)
在/usr/hbaes/hbase-2.2.2目录下,cd /usr/hbaes/hbase-2.2.2/
bin/start-hbase.sh #开启hbase
jps
在master上

在slave01上

在slave02上

9.4 shell操作
9.4.1 进入shell界面
在/usr/hbaes/hbase-2.2.2目录下:cd /usr/hbaes/hbase-2.2.2/
bin/hbase shell
1)在HBase中用create命令创建表:
create 'student','Sname','Ssex','Sage','Sdept','course'

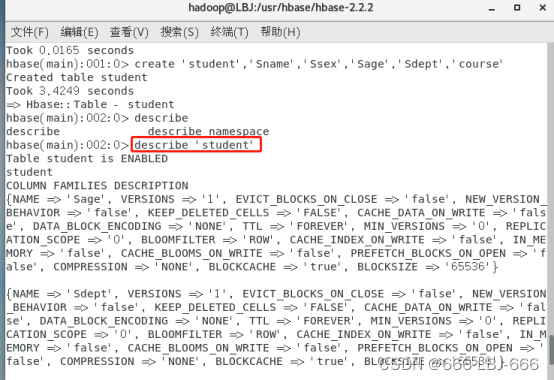
2)此时,即创建了一个“student”表,属性有:Sname,Ssex,Sage,Sdept,course。因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。创建完“student”表后,可通过describe命令查看“student”表的基本信息。
describe 'student'
9.4.2 hbase数据库基本操作
温馨提示:
在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。
1)添加数据
注:HBase中用put命令添加数据,注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据。
当运行命令:put ‘student’,’95001’,’Sname’,’LiYing’时,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
put 'student','95001','Sname','LiYing'

put 'student','95001','course:math','90'
即为95001行下的course列族的math列添加了一个数据。

2)删除数据
delete:用于删除一个数据,是put的反向操作。
deleteall:操作用于删除一行数据
①delete:
delete ‘student’,‘95001’,‘Ssex’
即删除了student表中95001行下的Ssex列的所有数据

②deleteall:
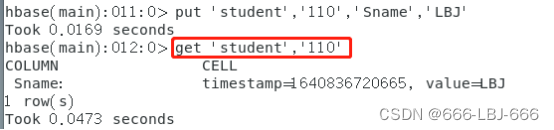
先put ‘student’,’110’,’Sname’,’LBJ’
再deleteall ‘student’,‘110’

3)查看数据
get:用于查看表的某一行数据。
scan:用于查看某个表的全部数据。
①get:
get ‘student’,’110’
②scan:
scan ‘student’

4)删除表格
删除表有两步,第一步先让该表不可用,第二步删除表。
disable ‘student’
drop ‘student’

9.4.3 hbase数据库查询表历史数据
1)在创建表格时,指定保存的版本数(这里假设指定为5)
create 'teacher',{NAME=>'username',VERSIONS=>5}

2)插入数据然后更新数据,使其产生历史版本数据,用put命令插入数据和更新数据
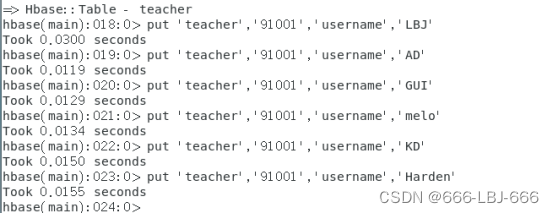
put ‘teacher’,‘91001’,‘username’,‘LBJ’
put ‘teacher’,‘91001’,‘username’,‘AD’
put ‘teacher’,‘91001’,‘username’,‘GUI’
put ‘teacher’,‘91001’,‘username’,‘Melo’
put ‘teacher’,‘91001’,‘username’,‘KD’
put ‘teacher’,‘91001’,‘username’,‘Harden’
3)查询时,指定查询的历史版本数。默认会查询出最新的数据。(有效取值为1到5)
get ‘teacher’,‘91001’,{COLUMN=>‘username’,VERSIONS=>5}
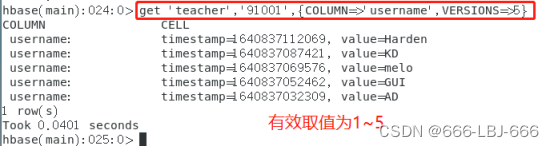
注:由于value为LBJ的数据最先插入,查询的数据有效取值为1~5,所以没有value为LBJ的数据。
9.4.4 退出hbase数据库
注:先退出shell命令界面,用exit退出。退出shell命令界面后,才能关闭hbase。
exit
关闭hbase:bin/stop-hbase.sh
10 安装hive
注:选用hive的远程模式,slave02安装mysql server用于存放元数据,slave01作为hive server作为thrift 服务器,master作为client客户端进行操作。
10.1 在slave02上安装MySQL server
1)查找yum源中是否有MySQL:
yum list | grep mysql

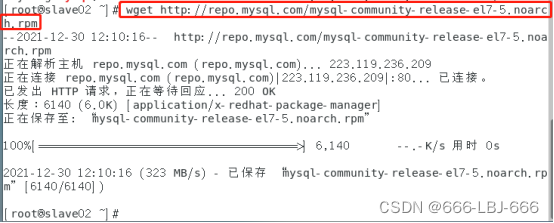
2)下载mysql的repo源:
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
3)安装mysql-community-release-el7-5.noarch.rpm包:
sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm

注:安装这个包后,就会获得两个mysql的yum repo源,如下:

4)安装mysql
sudo yum install mysql-server

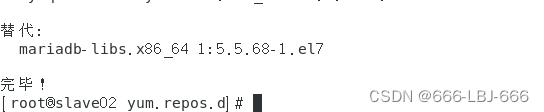
5)查看mysqld服务是否开启
①查看mysqld服务
sudo service mysqld status
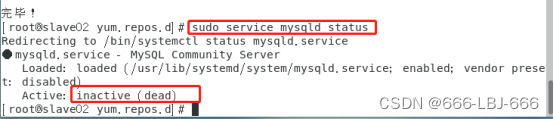
systemctl daemon-reload #重新加载某服务配置文件(包括Mysql)
service mysql start #开启mysql
systemctl enable mysqld #开启”mysqld”后再设置其开机自启,可不做
sudo netstat -tap | grep mysql #查看mysql的开放的端口
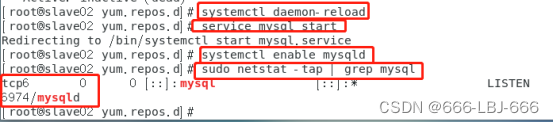
结果:发现还没有全部开启
⑤开放所有端口,以便远程连接。
在/etc/目录下找到my.cnf文件
vim my.cnf
在文件中添加:
bind-address = 0.0.0.0

所有端口开启成功:
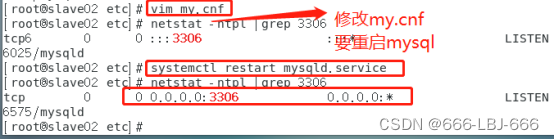
安装成功
systemctl status mysql #验证”mysql.service”服务器正在运行

6)重新设置mysql密码
①将本地密码设置成:123456
mysqladmin -u root password '123456'

第一次设置都可以成功,如果不能成功设置,可以参考一下的步骤:
在my.cnf文件中加入:skip-grant-tables #即可实现免密码登录
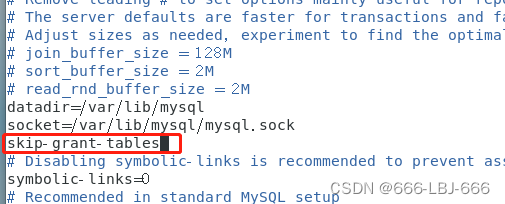
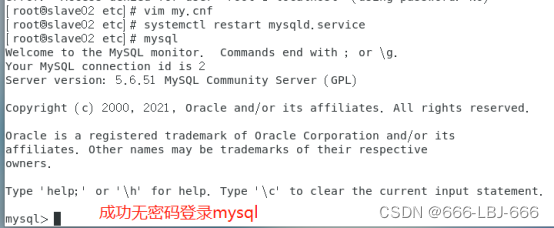
然后在mysql中修改密码即可:
修改成功:

不要忘记把skip-grant-tables删除:

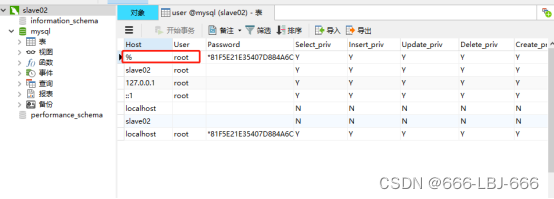
②首先删除之前的root账户,然后建立可本机且远程访问的root
show databases;
use mysql;
select user,host, authentication_string from user;


注:
每个人的root用户不同,有的没有,有的可能 ‘root’@‘localhost’ 按自己情况删除
drop user 'root'@'localhost';
select user,host,authentication_string from user;
显示root已被删除

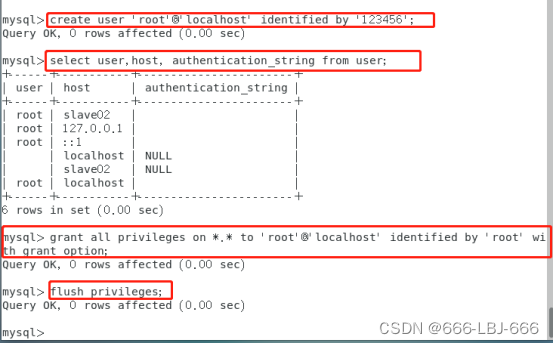
create user 'root'@'localhost' identified by '123456';
允许远程连接:
grant all privileges on . to ‘root’@‘localhost’ identified by ‘root’ with grant option;
flush privileges;
由于远程连接可能会失败,所以建议把localhost改为:%:

允许远程连接:
grant all privileges on . to ‘root’@‘%’ identified by ‘root’ with grant option;
并将登录密码改为:root
在终端中使用”root”用户和新设置的密码登入MySql即可,命令如下:
mysql -u root –p
更多修改登录密码的操作,可以参考:Mysql初始化root密码和允许远程访问 – 敏捷的水 – 博客园 (cnblogs.com)
本机mysql使用账号和密码:

③成功安装MySql数据库后,需要确保部署数据库的服务器上的3306端口已经开启,且可以使用数据库连接软件远程访问MySql数据库。
使用以下命令查看3306端口情况:
netstat -ntpl |grep 3306
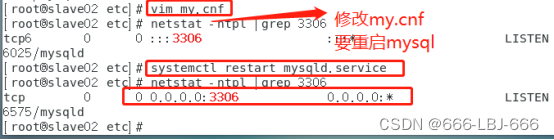
3306端口成功侦听了全部地址
7)远程连接登录mysql测试:
最好使用navcat等远程连接mysql工具
ip:为机器的ip名。

8)用root登入mysql创建元数据库hive
create database hive;
show databases;
exit #退出mysql,仅退出,未关服务

10.2 在master和slave01上安装hive
1)使用WinSCP将apache-hive-2.1.1-bin.tar.gz的压缩包从windows系统传至master主节点机器上,并放置在/opt/software目录中,同时创建 /usr/hive目录,后续将apache-hive-2.1.1-bin.tar.gz的压缩包解压到/usr/hive即可。

cp /home/hadoop/tmp/apache-hive-2.1.1-bin.tar.gz /opt/software

2)在master上创建hive目录,并解压hive安装包
mkdir -p /usr/hive
cd /usr/hive
解压到:/usr/hive/下
tar -zxvf /opt/software/apache-hive-2.1.1-bin.tar.gz -C /usr/hive/

3)同时需要一些联机操作,在slave01上建立文件夹/usr/hive,然后在master中将安装包远程复制到slave1。
mkdir -p /usr/hive
scp -r /usr/hive/apache-hive-2.1.1-bin root@slave01:/usr/hive/


10.3 在master和slave01上配置hive的环境
修改/etc/profile文件设置hive环境变量。(master和slave1都执行)
vim /etc/profile
#hive
export HIVE_HOME=/usr/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin
并生效: source /etc/profile
在master上:


在slave01上:

10.4 解决版本冲突和jar包依赖问题
由于客户端需要和hadoop通信,所以需要更改Hadoop中jline的版本。即保留一个高版本的jline jar包,从hive的lib包中拷贝到Hadoop中lib位置为/usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib。(master中执行)
cp /usr/hive/apache-hive-2.1.1-bin/lib/jline-2.12.jar
/usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/

因为服务端需要和Mysql通信,所以服务端需要将Mysql的依赖包放在Hive的lib目录下。(slave01中进行)
先进入/usr/hive/apache-hive-2.1.1-bin/lib下:
cd /usr/hive/apache-hive-2.1.1-bin/lib
cp /home/hadoop/tmp/mysql-connector-java-5.1.47-bin.jar /usr/hive/apache-hive-2.1.1-bin/lib

10.5 将slave01作为服务器端并配置hive
10.5.1配置hive-env.sh文件
注:回到slave1,修改hive-env.sh文件中HADOOP_HOME环境变量。进入hive配置目录,因为hive中已经给出配置文件的范本hive-env.sh.template,直接将其复制一个进行修改即可:
cd $HIVE_HOME/conf

cp hive-env.sh.template hive-env.sh
vim hive-env.sh

hive-env.sh文件中修改HADOOP_HOME环境变量。
HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.1.1-bin/lib

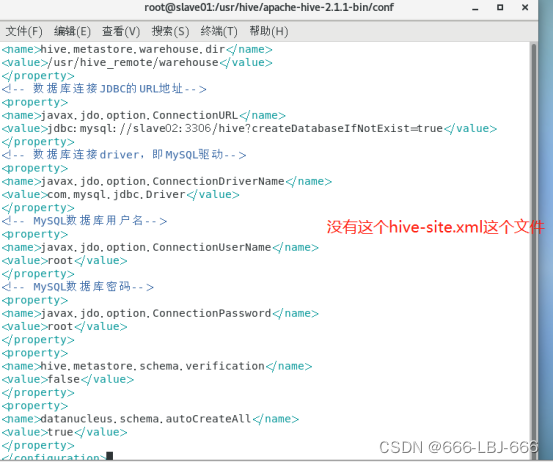
10.5.2配置hive-site.xml文件
①配置hive-site.xml文件
注:conf里是没有这个文件的,我们自己创建配置,直接vim hive-site.xml,即可直接创建该新文件。保存退出即可(:wq)
<configuration>
<!-- Hive产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive_remote/warehouse</value>
</property>
<!-- 数据库连接JDBC的URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave02:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!-- 数据库连接driver,即MySQL驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- MySQL数据库用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- MySQL数据库密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
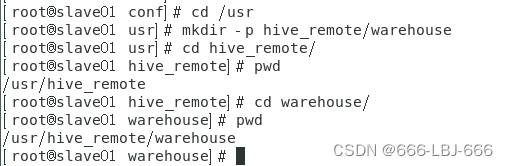
②在/usr下用mkdir -p新建hive_remote/warehouse目录,在配置文件中用到,hive产生元数据的存储文件夹。
10.6 将master作为客户端配置hive
先进入hive修改配置文件目录
cd $HIVE_HOME/conf
10.6.1 配置 hive-site.xml
①配置hive-site.xml文件
先vim hive-site.xml
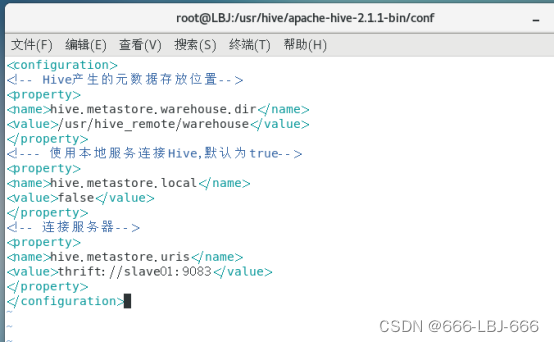
<configuration>
<!-- Hive产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive_remote/warehouse</value>
</property>
<!--- 使用本地服务连接Hive,默认为true-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!-- 连接服务器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://slave01:9083</value>
</property>
</configuration>
②在/usr下用mkdir -p新建hive_remote/warehouse目录,在配置文件中用到,hive产生元数据的存储文件夹。

10.6.2 配置 hive-env.sh文件
在master上
先拷贝hive-env.sh.template文件,命名为hive-env.sh
cp hive-env.sh.template hive-env.sh

vim hive-env.sh
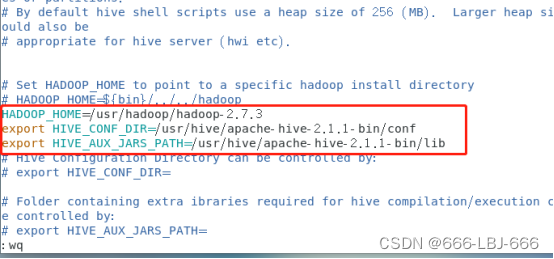
hive-env.sh文件中修改HADOOP_HOME环境变量。
HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.1.1-bin/lib
10.7 启动hive
注:启动前,按顺序将之前所有的hadoop,zookeeper,hbase服务启动,否则在master上输入bin/hive命令时会报错。
1)启动hive server服务(slave01上)
先进入 /usr/hive/apache-hive-2.1.1-bin/
接着:bin/hive --service metastore(hive后面后空格)
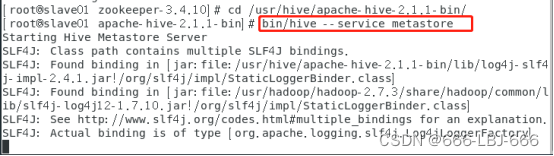
启动成功(注:slave01启动hive后有些关于ssl的warn如下,应该是slave02和其余节点未免密,以后安装集群在一开始集群免密还是要三台机器都互相免密)
2)在master上启动hive client
①进入/usr/hive/apache-hive-2.1.1-bin/目录:
cd /usr/hive/apache-hive-2.1.1-bin/
bin/hive #启动hive

②测试hive是否启动成功:
show databases;
创建数据库hive_db:create database hive_db;(之前已经创建)
③查看runjar(启动成功的标志)
先不要关闭当前终端会话,去外面打开一个新的终端会话,打开另一个terminal:
jps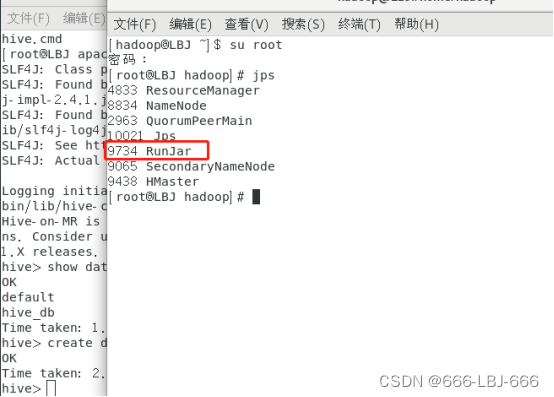
11 安装Spark
11.1 安装scala环境
1)使用WinSCP将scala-2.11.12.tgz的压缩包从windows系统传至master主节点机器上,并放置在/opt/software目录中,同时创建 /usr/scala目录,后续将scala-2.11.12.tgz的压缩包解压到/usr/scala即可。(先在master配置好,在分发到slave01、slave02节点上)
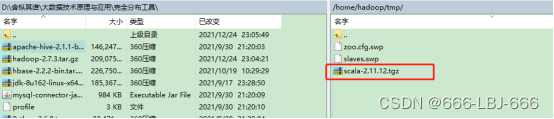
cp /home/hadoop/tmp/scala-2.11.12.tgz /opt/software/

2)创建 /usr/scala目录,并解压scala
mkdir -p /usr/scala
cd /usr/scala

tar -zxvf /opt/software/scala-2.11.12.tgz -C /usr/scala/

rm -rf /opt/software/scala-2.11.12.tgz
3)配置scala的环境变量并生效:
vim /etc/profile
#scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH

source /etc/profile

4)查看scala是否安装成功:
scala -version

5)将scala分发复制到其他节点:
scp -r /usr/scala root@slave01:/usr/
scp -r /usr/scala root@slave02:/usr/


并在其他节点配置环境变量,并使之生效。
在slave01查看scala是否安装成功:

在slave02查看scala是否安装成功:

做完这一步,scala安装完成了!!!
11.2 安装Spark(具体)
1)使用WinSCP将spark-2.4.0-bin-hadoop2.7.tgz的压缩包从windows系统传至master主节点机器上,并放置在/opt/software目录中,同时创建 /usr/spark目录,后续将spark-2.4.0-bin-hadoop2.7.tgz的压缩包解压到/usr/spark即可。(先在master配置好,在分发到slave01、slave02节点上)
cp /home/hadoop/tmp/spark-2.4.0-bin-hadoop2.7.tgz /opt/software/

2)创建 /usr/spark目录,并解压spark
mkdir -p /usr/spark
cd /usr/spark
tar -zxvf /opt/software/spark-2.4.0-bin-hadoop2.7.tgz -C /usr/spark

rm -rf /opt/software/spark-3.0.3-bin-hadoop2.7.tgz
3)配置spark-env.sh文件:
由于没有spark-env.sh文件,需要复制一份spark-env.sh.template
cd spark-3.0.3-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh

添加以下内容:
export SPARK_MASTER_IP=LBJ
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_162
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop

4)配置spark从节点,修改slaves文件
注:注意slaves节点中只包含节点信息,其他注释不需要
由于没有slaves文件,需要复制一份slaves.template
cp slaves.template slaves
vim slaves

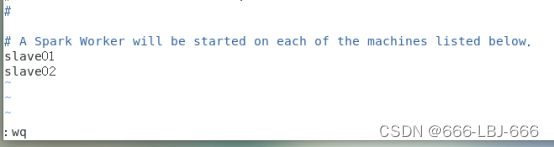
5)将spark分发复制到其他节点:
scp -r /usr/spark root@slave01:/usr/
scp -r /usr/spark root@slave02:/usr/


6)配置spark环境变量(三台机器都做,一样操作)
vim /etc/profile
添加内容:
#spark
export SPARK_HOME=/usr/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH

使之生效:source /etc/profile



7)开启spark(在master节点上)
/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
jps
在master上:
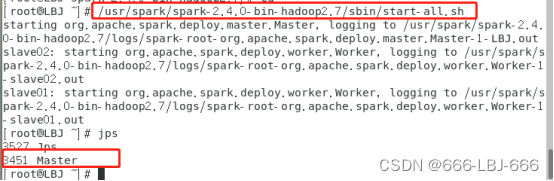
在slave01上:

在slave02上:
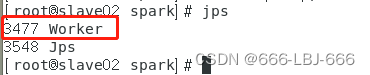
做完这一步,spark安装完成了!!!
11.3 运行例程
注:运行spark自带例程和shell命令板块。
1)运行自带例程进行验证
cd /usr/spark/spark-2.4.0-bin-hadoop2.7/
bin/run-example SparkPi
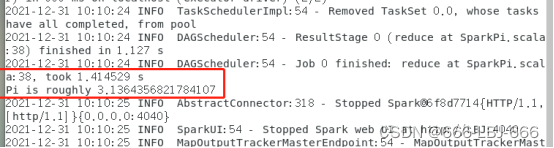
bin/run-example SparkPi 2>&1 | grep "Pi is"

2)shell命令验证
进入shell命令界面:bin/spark-shell
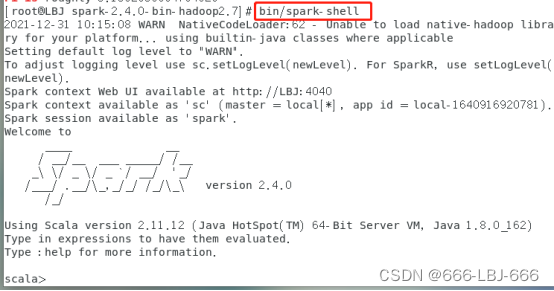
加载text文件
spark创建sc,可以加载本地文件和HDFS文件创建RDD。这里用Spark自带的本地文件README.md文件测试。
val textFile = sc.textFile("file:///usr/spark/spark-2.4.0-bin-hadoop2.7/README.md")

简单RDD操作
//获取RDD文件textFile的第一行内容
textFile.first()
//获取RDD文件textFile所有项的计数
textFile.count(
)
//抽取含有“Spark”的行,返回一个新的RDD
val lineWithSpark = textFile.filter(line => line.contains(“Spark”))
//统计新的RDD的行数
lineWithSpark.count()

可以通过组合RDD操作进行组合,可以实现简易MapReduce操作
//找出文本中每行的最多单词数
textFile.map(line => line.split(” “).size).reduce((a, b) => if (a > b) a else b)

退出Spark Shell
输入exit,即可退出spark shell
:quit
做完这一步,运行例程验证完成了!!!
12 安装eclipse
1)使用WinSCP将eclipse-committers-2020-03-R-linux-gtk-x86_64.tar.gz的压缩包从windows系统传至master主节点机器上,在master上解压安装在/usr/即可。

tar -zxvf /home/hadoop/tmp/eclipse-committers-2020-03-R-linux-gtk-x86_64.tar.gz -C /usr/
启动eclipse



做完这一步,安装eclipse完成了!!!
后续使用eclipse编程会在后续实现。
做完以上操作,hadoop的完全分布式集群搭建成功!!!
三台CentOS7.6虚拟机搭建Hadoop完全分布式集群(三)笔记到此完结,笔者归纳、创作不易,大佬们给个3连再起飞吧
原文地址:https://blog.csdn.net/kdzandlbj/article/details/135300539
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52022.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!