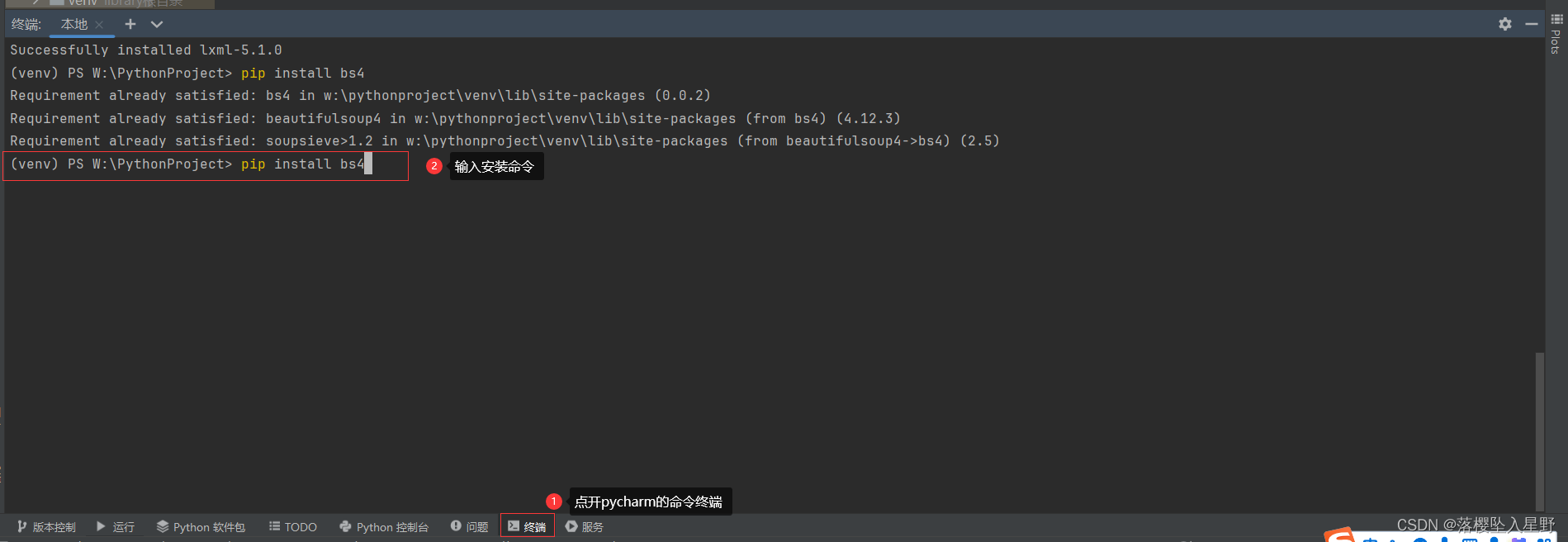
本文介绍: 项目框架没有问题大家布好了的话,接着我们就开始部署scrapy项目(没搭好架子的话,看我上文爬虫工作量由小到大的思维转变—<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客。
前言:
项目框架没有问题大家布好了的话,接着我们就开始部署scrapy项目(没搭好架子的话,看我上文爬虫工作量由小到大的思维转变—<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客)
正文:
1.创建主机:
首先gerapy的架子,就相当于部署服务器上的;所以,我们先要连接主机(用户名/密码随你填不填)
—-ps:我建议你填一下子,养成习惯;别到时候布到云服务上去了,被人给扫了,那不好玩的!
这里ip就填 127.0.0.1 ,端口6800 —>就是你scrapyd的端口!


2.开启scrapyd服务
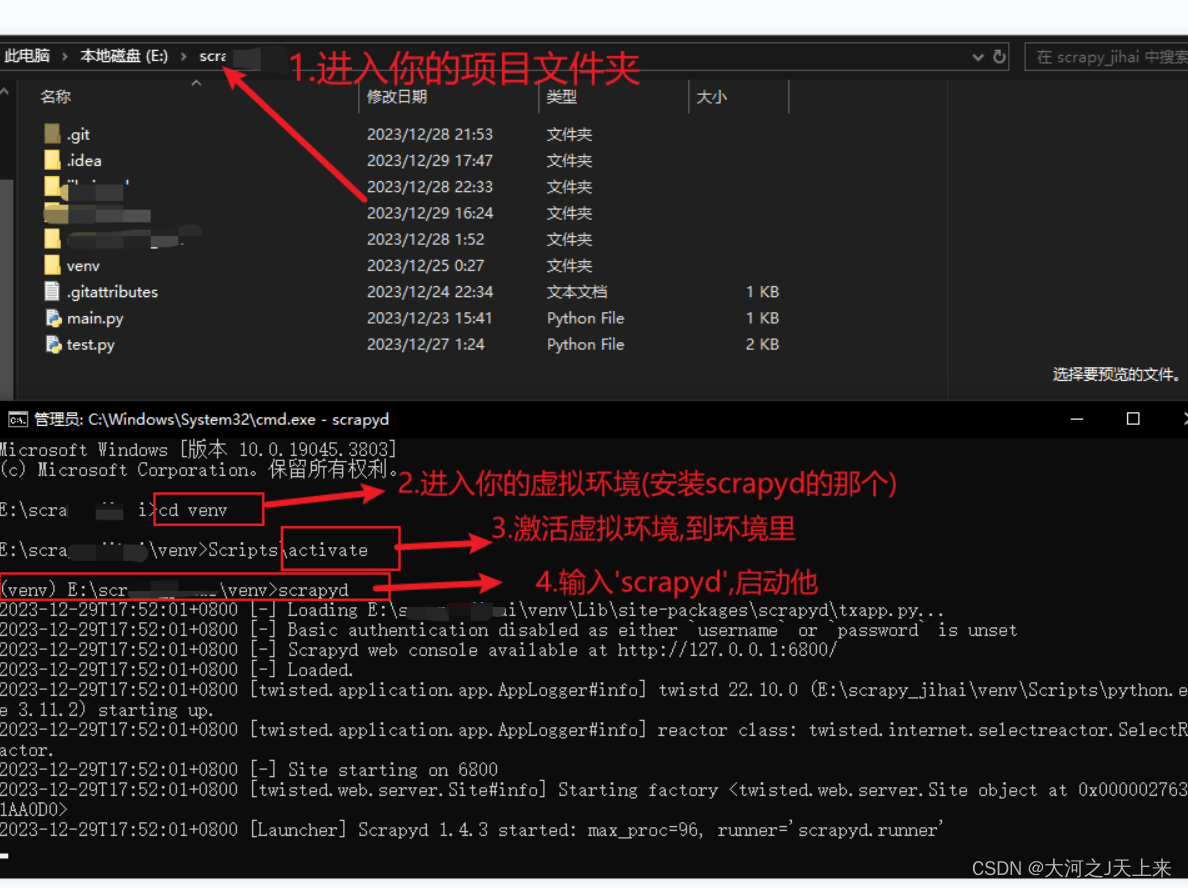

3.创建项目文件夹(你也可以自己cmd完成,都随意! 看我原理就成):
特别注意:

4.丢爬虫工程:
1.怎么丢爬虫工程:

2.从github上/其他地方拷(后面会讲,这里只谈本地的先带着走一遍)
5.部署到XX服务器(这里是部署本机链接服务):
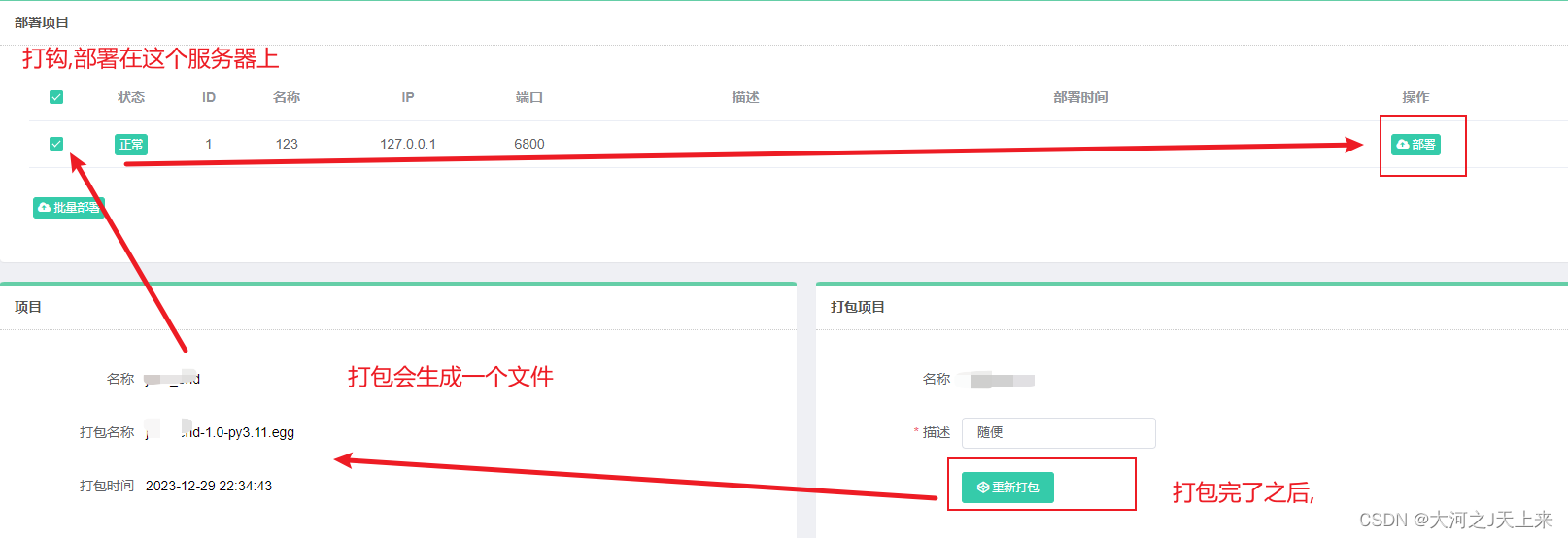
步骤1. 你爬虫项目丢的没问题,这个图就没问题!
步骤2: 打包如果有问题,去看log! 很有可能是坏在setting上—按我步骤,一般不会报错;你就反复去看 ‘4.丢爬虫工程’那个环节!


7.随便玩了
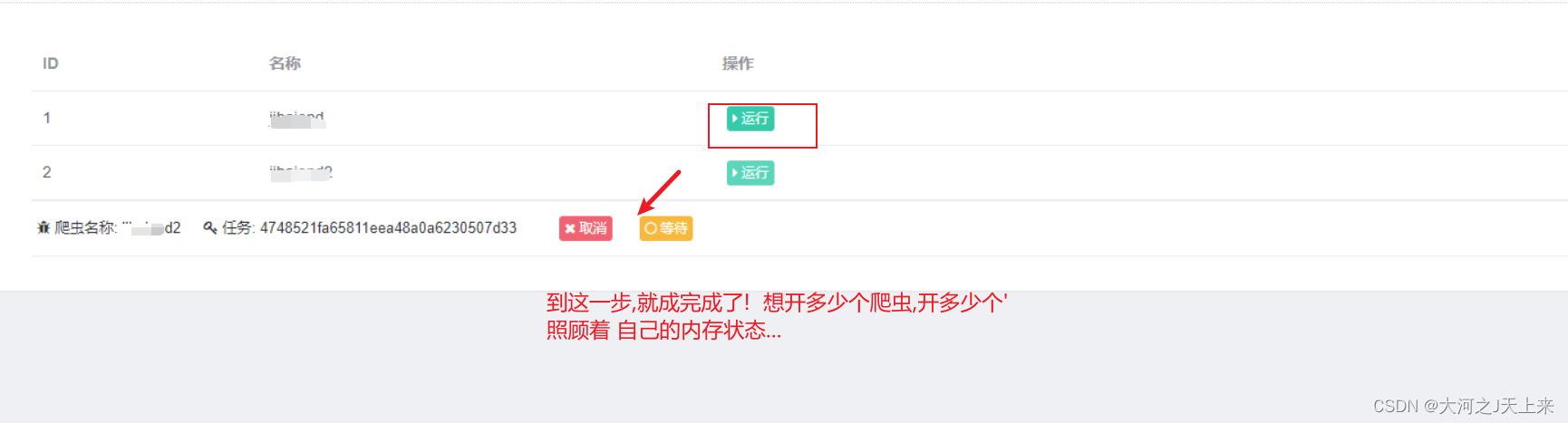
———–恭喜大家,部署了自己第一个爬虫项目! 是不是瞬间感觉其他都不香了….
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。